本文主要是介绍Spark distinct去重原理 (distinct会导致shuffle),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
distinct算子原理: 含有reduceByKey则会有shuffle
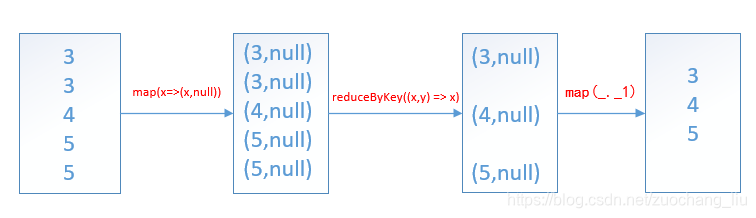
贴上spark源码:
/*** Return a new RDD containing the distinct elements in this RDD.*/def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)}示例代码:
package com.wedoctor.utils.testimport org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSessionobject Test {Logger.getLogger("org").setLevel(Level.ERROR)def main(args: Array[String]): Unit = {//本地环境需要加上System.setProperty("HADOOP_USER_NAME", "root")val session: SparkSession = SparkSession.builder().master("local[*]").appName(this.getClass.getSimpleName).getOrCreate()val value: RDD[Int] = session.sparkContext.makeRDD(Array(3,3,4,5,5))value.distinct().foreach(println)//等价于value.map(x=>(x,null)).reduceByKey((x,y) => x).map(_._1).foreach(println)session.close()}
}转自:https://blog.csdn.net/zuochang_liu/article/details/105387704
这篇关于Spark distinct去重原理 (distinct会导致shuffle)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






