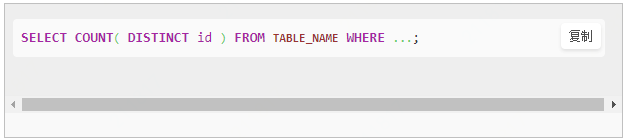
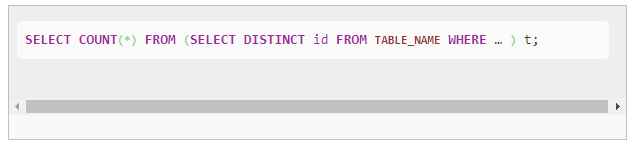
| hive> set mapreduce.job.reduces=5;
hive>
> select count(dept_num)
> from (
> select distinct dept_num
> from emp_ct
> ) t1;
Query ID = mart_fro_20200320234453_68ad3780-c3e5-44bc-94df-58a8f2b01f59
Total jobs = 2
Launching Job 1 out of 2
Number of reduce tasks not specified. Defaulting to jobconf value of: 5
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Start submit job !
Start GetSplits
GetSplits finish, it costs : 13 milliseconds
Submit job success : job_1584341089622_358684
Starting Job = job_1584341089622_358684, Tracking URL = http://BJHTYD-Hope-25-11.hadoop.jd.local:50320/proxy/application_1584341089622_358684/
Kill Command = /data0/hadoop/hadoop_2.100.31_2019090518/bin/hadoop job -kill job_1584341089622_358684
Hadoop job(job_1584341089622_358684) information for Stage-1: number of mappers: 2; number of reducers: 5
2020-03-20 23:45:02,920 Stage-1(job_1584341089622_358684) map = 0%, reduce = 0%
2020-03-20 23:45:23,533 Stage-1(job_1584341089622_358684) map = 50%, reduce = 0%, Cumulative CPU 3.48 sec
2020-03-20 23:45:25,596 Stage-1(job_1584341089622_358684) map = 100%, reduce = 0%, Cumulative CPU 7.08 sec
2020-03-20 23:45:32,804 Stage-1(job_1584341089622_358684) map = 100%, reduce = 20%, Cumulative CPU 9.43 sec
2020-03-20 23:45:34,861 Stage-1(job_1584341089622_358684) map = 100%, reduce = 40%, Cumulative CPU 12.39 sec
2020-03-20 23:45:36,923 Stage-1(job_1584341089622_358684) map = 100%, reduce = 80%, Cumulative CPU 18.47 sec
2020-03-20 23:45:40,011 Stage-1(job_1584341089622_358684) map = 100%, reduce = 100%, Cumulative CPU 23.23 sec
MapReduce Total cumulative CPU time: 23 seconds 230 msec
Stage-1 Elapsed : 46404 ms job_1584341089622_358684
Ended Job = job_1584341089622_358684
Launching Job 2 out of 2
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Start submit job !
Start GetSplits
GetSplits finish, it costs : 47 milliseconds
Submit job success : job_1584341089622_358729
Starting Job = job_1584341089622_358729, Tracking URL = http://BJHTYD-Hope-25-11.hadoop.jd.local:50320/proxy/application_1584341089622_358729/
Kill Command = /data0/hadoop/hadoop_2.100.31_2019090518/bin/hadoop job -kill job_1584341089622_358729
Hadoop job(job_1584341089622_358729) information for Stage-2: number of mappers: 5; number of reducers: 1
2020-03-20 23:45:48,353 Stage-2(job_1584341089622_358729) map = 0%, reduce = 0%
2020-03-20 23:46:05,846 Stage-2(job_1584341089622_358729) map = 20%, reduce = 0%, Cumulative CPU 2.62 sec
2020-03-20 23:46:06,873 Stage-2(job_1584341089622_358729) map = 60%, reduce = 0%, Cumulative CPU 8.49 sec
2020-03-20 23:46:08,931 Stage-2(job_1584341089622_358729) map = 80%, reduce = 0%, Cumulative CPU 11.53 sec
2020-03-20 23:46:09,960 Stage-2(job_1584341089622_358729) map = 100%, reduce = 0%, Cumulative CPU 15.23 sec
2020-03-20 23:46:35,639 Stage-2(job_1584341089622_358729) map = 100%, reduce = 100%, Cumulative CPU 20.37 sec
MapReduce Total cumulative CPU time: 20 seconds 370 msec
Stage-2 Elapsed : 54552 ms job_1584341089622_358729
Ended Job = job_1584341089622_358729
MapReduce Jobs Launched:
Stage-1: Map: 2 Reduce: 5 Cumulative CPU: 23.23 sec HDFS Read: 0.000 GB HDFS Write: 0.000 GB SUCCESS Elapsed : 46s404ms job_1584341089622_358684
Stage-2: Map: 5 Reduce: 1 Cumulative CPU: 20.37 sec HDFS Read: 0.000 GB HDFS Write: 0.000 GB SUCCESS Elapsed : 54s552ms job_1584341089622_358729
Total MapReduce CPU Time Spent: 43s600ms
Total Map: 7 Total Reduce: 6
Total HDFS Read: 0.000 GB Written: 0.000 GB
OK
3
Time taken: 103.692 seconds, Fetched: 1 row(s)
|