本文主要是介绍MySQL row_number()函数,rank()函数和dense_rank()函数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
从MySQL8.0开始引用row_number(), rank()函数和dense_rank()函数,也就是常见的窗口函数,三个函数都是一种用于计算排名的工具,它们根据指定的列对结果集进行排序,并为每一行分配一个排名值(1,2,3,...)。
函数区别点
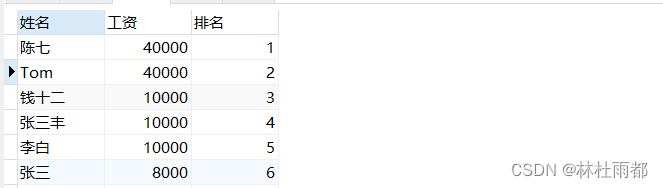
1、row_number()函数不会跳过相同值排名,即常见顺序(1,2,3)
适用场景:
- 需要为每一行分配唯一的数字。
- 不关心相同值的排名差异。
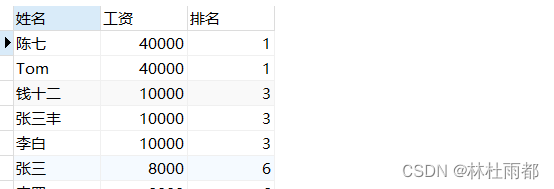
2、rank()函数会跳过相同值的排名,即使有相同的值也会分配相同的排名(1,1,3);
适用场景:
- 需要考虑相同值的排名差异。
- 希望在出现相同值时跳过下一级的排名。
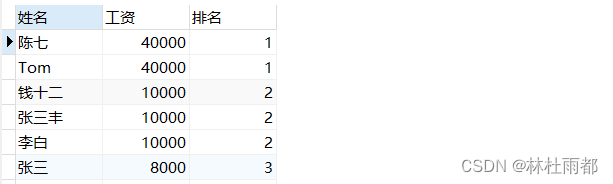
3、dense_rank()函数不会跳过排名,即使有相同的值也会分配相同的排名(1,1,2);
适用场景:
- 需要考虑相同值的排名差异。
- 希望在出现相同值时不跳过下一级的排名。
函数语法
row_number()函数语法:
row_number() over (partition by expr,...[,expr_n]
order by expr [asc|desc],...[,expr_n]);
- partition by :可选部分,将结果集分成更小的集合,如果省略此部分,会将整个结果集视为一个分区。
- order by :必选部分,指定按照哪些列对行进行排序。
示例:为每个部门内的员工按照薪水排序
select department,employee_name,salary,row_number() over (partition by department order by salary) as '排名' from employees;
rank()函数语法:
rank() over (order by column_name [asc|desc])
dense_rank函数语法:
dense_rank() over (order by column_name [asc|desc])
简单使用
假设有一个employee表,需要查询员工薪资排名
-- 使用row_number()函数
select name '姓名',salary '工资',row_number() over(order by salary desc) as '排名'
from `employees`;
-- rank()函数
select name '姓名',salary '工资',rank() over(order by salary desc) as '排名'
from `employees`;
-- dense_rank()函数
select name '姓名',salary '工资',dense_rank() over(order by salary desc) as '排名'
from `employees`;
这篇关于MySQL row_number()函数,rank()函数和dense_rank()函数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



