masked专题

多图!今天聊聊Masked ROM
文章目录 成本与灵活性的妥协视频游戏卡带中的应用直接读取的优势 逻辑门NORORNAND TechnologyActive layer-有源层Contact layer-接触层Metal-金属层Implanted-离子注入 Reading out电子分析-Electronic光学分析-Optical染色法-Staining扫描电容显微镜(SCM)扫描微波阻抗显微镜(SMIM)能量色散X射线光

NoMaD: Goal Masked Diffusion Policies for Navigation and Exploration
引言 机器人学习的背景和挑战 本文的研究重点 现有方法的局限性 本文的创新点 相关工作 事先准备 视觉目标条件策略 ViNT在目标条件导航中表现出最先进的性能,但它不能执行无方向探索,需要外部的子目标建议机制。Nomad扩展了Vint,同时支持目标条件导航和无方向导航。 使用拓扑图探索 在本文中,我们基于frontier探索,测试
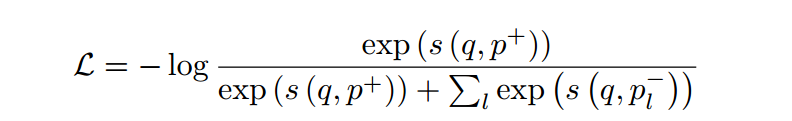
信息检索(36):ConTextual Masked Auto-Encoder for Dense Passage Retrieval
ConTextual Masked Auto-Encoder for Dense Passage Retrieval 标题摘要1 引言2 相关工作3 方法3.1 初步:屏蔽自动编码3.2 CoT-MAE:上下文屏蔽自动编码器3.3 密集通道检索的微调 4 实验4.1 预训练4.2 微调4.3 主要结果 5 分析5.1 与蒸馏检索器的比较5.2 掩模率的影响5.3 抽样策略的影响5.4 解码器
![[论文精读]Masked Autoencoders are scalable Vision Learners](https://img-blog.csdnimg.cn/direct/339a52553e2447ffa8b06a7d8d7d0fef.png)
[论文精读]Masked Autoencoders are scalable Vision Learners
摘要本文证明了掩码自编码器(MAE)是一种可扩展的计算机视觉自监督学习算法。我们的 MAE方法很简单:我们盖住输入图像的随机块并重建缺失的像素。它基于两个核心设计。首先,我们开发了一个非对称编码器-解码器架构,其中一个编码器仅对块的可见子集(没有掩码标记)进行操作,以及一个轻量级解码器,该解码器从潜在表示和掩码标记重建原始图像。其次,我们发现如果用比较高的掩盖比例掩盖输入图像,例如75%,这会产生

Failed to start docker.service: Unit docker.service is masked.
Failed to start docker.service: Unit docker.service is masked. 未知原因:docker 被mask 解决方式: systemctl unmask docker.service systemctl unmask docker.socket systemctl start docker.service Docker是一种相对使用较简单的

【论文精读】MAE:Masked Autoencoders Are Scalable Vision Learners 带掩码的自动编码器是可扩展的视觉学习器
系列文章目录 【论文精读】Transformer:Attention Is All You Need 【论文精读】BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding 【论文精读】VIT:vision transformer论文 文章目录 系列文章目录一、前言二、文章概览(一)研究背

MAE——「Masked Autoencoders Are Scalable Vision Learners」
这次,何凯明证明让BERT式预训练在CV上也能训的很好。 论文「Masked Autoencoders Are Scalable Vision Learners」证明了 masked autoencoders(MAE) 是一种可扩展的计算机视觉自监督学习方法。 这项工作的意义何在? 讨论区 Reference MAE 论文逐段精读【论文精读】_哔哩哔哩_bilibili //

PyTorch随笔 - MAE(Masked Autoencoders)推理脚本
MAE推理脚本: 需要安装:pip install timm==0.4.5需要下载:mae_visualize_vit_base.pth,447M 源码: #!/usr/bin/env python# -- coding: utf-8 --"""Copyright (c) 2022. All rights reserved.Created by C. L. Wang on 202
新型masked勒索病毒袭击工控行业
2019年10月9号总部设在荷兰海牙的欧洲刑警组织与国际刑警组织共同发布报告《2019互联网有组织犯罪威胁评估》,报告指出数据已成为网络犯罪分子的主机攻击目标,勒索软件仍是网络安全最大威胁,全球各界需要加强合作,联合打击网络犯罪。 尽管全球勒索病毒的总量有所下降,但是有组织有目的针对企业的勒索病毒攻击确实越来越多,给全球造成了巨大的经济损失,勒索软件仍然是网络安全最大的威胁,成为作案范围最广

docker 启动报错Failed to start docker.service: Unit docker.service is masked.
1 ubuntu 完成安装docker 之后, 执行: $ sudo service docker start 报错: 2 处理方法: 执行: $ systemctl unmask docker.service$ systemctl unmask docker.socket$ systemctl start docker.service 3 再执行: $

关于jQuery plugin: Masked Input不能处理中文的解决办法。
http://digitalbush.com/projects/masked-input-plugin/ 我用的是1.2.2 $('#period').mask("99小时99分钟"); 在chrome下有效,IE6下失败。其他浏览器未测。 做一下修改。 203行: } else if (buffer[i] == test[pos] && i!=partialP
【学习日记week5】基于掩蔽的学习方法和跨模态动量对比学习方法(Masked Language Modeling Cross-modal MCL)
序言 首先先review一篇师兄最近看的CVPR23的文章,这歌内容很有意思,通过Bert进行推理来构建类Masked Language,然后对其进行学习。 ViLEM: Visual-Language Error Modeling for Image-Text Retrieval(CVPR 23) 序言 ViLEM:是指视觉语言的错误建模。这个工作是基于ITC的基础上的。 Motiva

《Spelling Error Correction with Soft-Masked BERT》阅读记录
《Spelling Error Correction with Soft-Masked BERT》 To be published at ACL 2020. 2020.5.15 链接:https://arxiv.org/abs/2005.07421 摘要 彼时CSC的SOTA方法:在语言表示模型BERT的基础上,在句子的每个位置从候选词列表中选择一个字符进行纠正(包括不纠正)。 但这

On Data Scaling in Masked Image Modelin
论文名称:On Data Scaling in Masked Image Modeling 发表时间:CVPR2023 作者及组织:Zhenda Xie, ZhengZhang, Hu Han等,来自清华,西安交大,微软亚洲研究院。 前言 本文验证SIMMIM无监督预训练方法,是否会出现与NLP类似的拓展法则现象。 1、结论 这篇论文做了大量的对比实验,因此,先说结论: 1)大模型在

Masked Graph Attention Network for Person Re-identification
Masked Graph Attention Network for Person Re-identification 论文:Masked Graph Attention Network for Person Re-identification,cvpr,2019 链接:paper 代码:github 摘要 主流的行人重识别方法(ReID)主要关注个体样本图像与标签之间的对应关系,
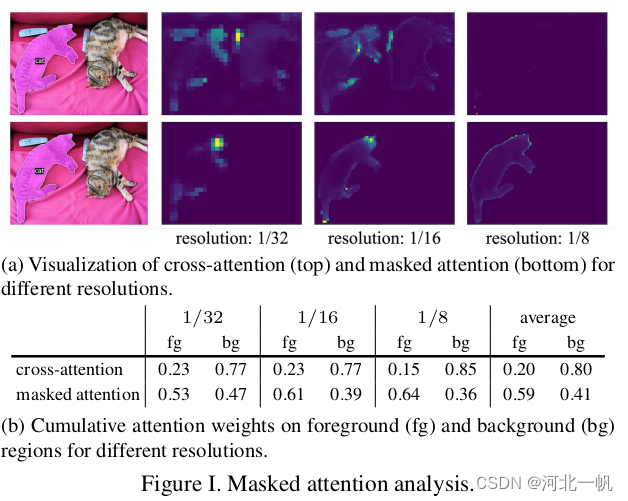
从DETR到Mask2Former(3):masked attention的attention map可视化
Mask2Former的论文中有这样一张图,表示masked attenion比cross attention效果要好 那么这个attention map是怎么画出来的? 在mask2attention的源代码中 CrossAttentionLayer这个类中,在forward_post函数中做如下修改: def forward_post(self, tgt, memory,me
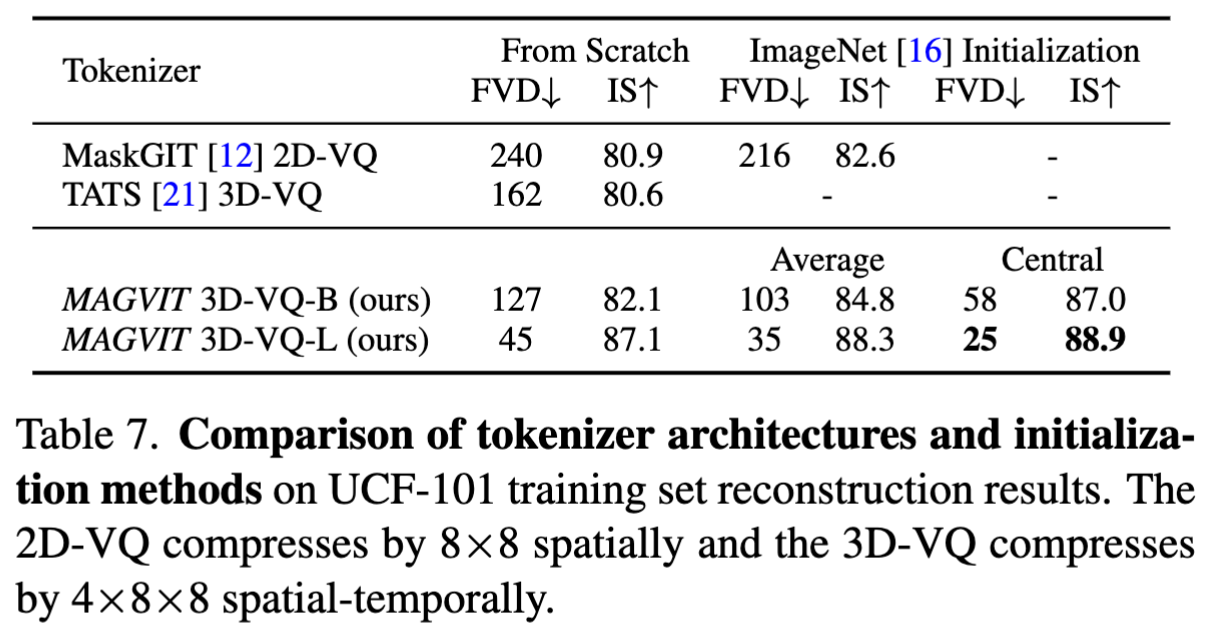
MAGVIT: Masked Generative Video Transformer
Paper name MAGVIT: Masked Generative Video Transformer Paper Reading Note Paper URL: https://arxiv.org/abs/2212.05199 Project URL: https://magvit.cs.cmu.edu/ Code URL: https://github.com/google-r
MAGVIT: Masked Generative Video Transformer
Paper name MAGVIT: Masked Generative Video Transformer Paper Reading Note Paper URL: https://arxiv.org/abs/2212.05199 Project URL: https://magvit.cs.cmu.edu/ Code URL: https://github.com/google-r
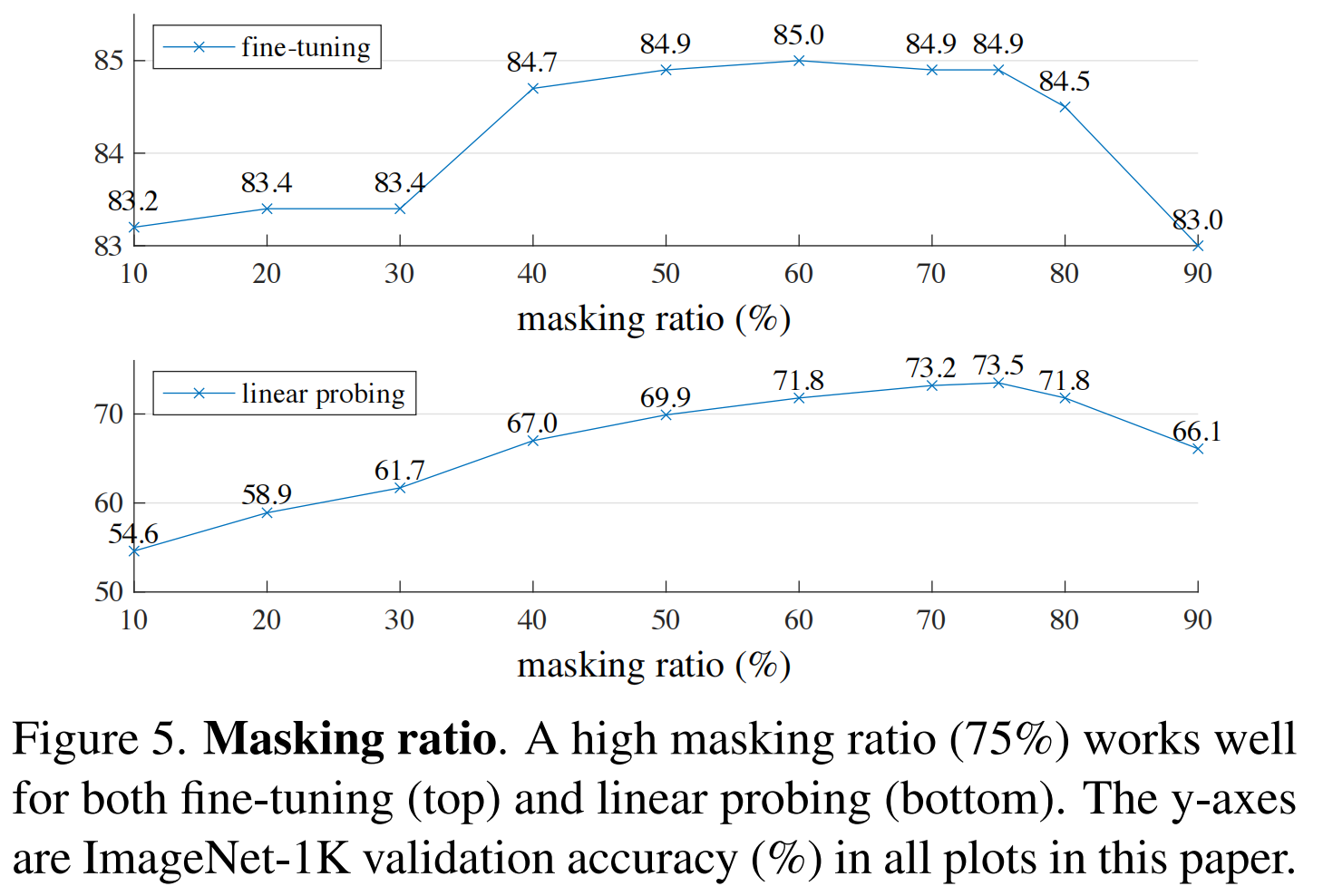
【ICCV 2022】(MAE)Masked Autoencoders Are Scalable Vision Learners
何凯明一作文章:https://arxiv.org/abs/2111.06377 感觉本文是一种新型的自监督学习方式 ,从而增强表征能力 本文的出发点:是BERT的掩码自编码机制:移除一部分数据并对移除的内容进行学习。mask自编码源于CV但盛于NLP,恺明对此提出了疑问:是什么导致了掩码自编码在视觉与语言之间的差异?尝试从不同角度进行解释并由此引申出了本文的MAE。 恺明提出一种用于计
论文阅读: Masked Autoencoders Are Scalable Vision Learners掩膜自编码器是可扩展的视觉学习器
Masked Autoencoders Are Scalable Vision Learners 掩膜自编码器是可扩展的视觉学习器 作者:FaceBook大神何恺明 一作 摘要: This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision.

【论文学习】Neighbour Interaction based Click-Through Rate Prediction via Graph-masked Transformer
简介 论文提出了一种基于Graph-Masked Transformer 方法,用于解决异构信息网络中链接预测问题。 传统的ctr预测存在问题:一方面用户数据存在稀疏的问题,导致冷启动问题和表达效果不好。另一方面由于传统的推荐系统是基于曝光的,所以直接和用户相关联的商品,不够丰富和详尽,不能梵音用户的潜在问题。 论文的主要贡献是: 1.为了充分挖掘HIN中u2i的关系,来帮组ctr预测问题,提出

文献阅读:MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis
文献阅读:MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis 论文链接: paper 代码地址: code MAE 掩码自动编码器(MAE):屏蔽输入图像的随机patch并重建丢失的像素。它基于两个核心设计。 首先,文章开发了一种非对称的编码器-解码器架构:
【论文阅读笔记】Traj-MAE: Masked Autoencoders for Trajectory Prediction
Abstract 通过预测可能的危险,轨迹预测一直是构建可靠的自动驾驶系统的关键任务。一个关键问题是在不发生碰撞的情况下生成一致的轨迹预测。为了克服这一挑战,我们提出了一种有效的用于轨迹预测的掩蔽自编码器(Traj-MAE),它能更好地代表驾驶环境中智能体的复杂行为。 具体来说,我们的Traj-MAE采用了多种掩蔽策略来预训练轨迹编码器和地图编码器,允许捕获智能体之间的社会和时间信息,同时利
NarrowBERT: Accelerating Masked Language Model Pretraining and Inference
本文是LLM系列文章,针对《NarrowBERT: Accelerating Masked Language Model Pretraining and Inference》的翻译。 NarrowBERT:加速掩蔽语言模型的预训练和推理 摘要1 引言2 NarrowBERT3 实验4 讨论与结论局限性 摘要 大规模语言模型预训练是自然语言处理中一种非常成功的自监督学习形式,但随着
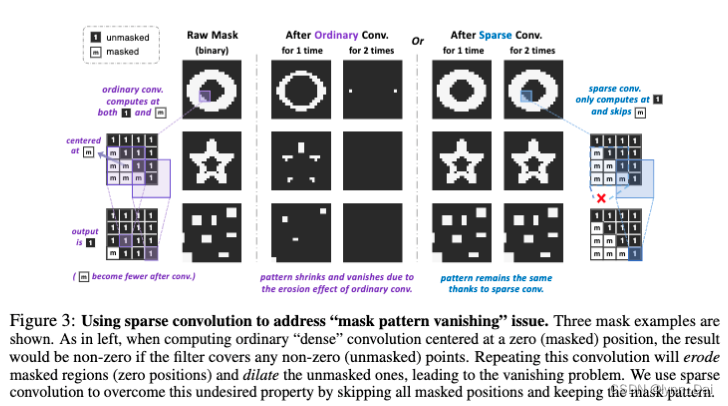
【iclr2023】DESIGNING BERT FOR CONVOLUTIONAL NETWORKS: SPARSE AND HIERARCHICAL MASKED MODELING
论文 & 代码 & Notable-top-25% 摘要 我们发现并攻克了将BERT-style预训练或者图像mask建模应用到CNN中的两个关键障碍:1) CNN不能处理不规则的、随机的掩码输入图像;2)BERT预训练的单尺度性质与convnet的层次结构不一致 对于第一点,我们将没有被mask掉的像素点视作为3d点云(点云是一种方便的3D表达方式)的稀疏体素;使用sparse CNN进行