本文主要是介绍文献阅读:MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文献阅读:MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis
论文链接:
paper
代码地址:
code
MAE
掩码自动编码器(MAE):屏蔽输入图像的随机patch并重建丢失的像素。它基于两个核心设计。

- 首先,文章开发了一种非对称的编码器-解码器架构:其中一个编码器仅对可见的patch进行操作,另一个轻量级解码器从潜在表示和掩码标记重建原始图像。
- 文章发现掩蔽高比例的输入图像,例如75%,产生了一个非平凡且有意义的自我监督任务。将这两种设计结合起来,能够高效地训练大型模型。
首先,我们为每个输入补丁生成一个标记(通过添加位置嵌入的线性投影)。接下来,我们将随机洗牌列表,并根据屏蔽比率删除列表的最后一部分。这个过程为编码器产生一个小的目标子集,等价于不用替换的方法采样patch。编码后,我们将一个掩码令牌列表添加到已编码的补丁列表中,并对整个列表进行反洗牌(颠倒随机洗牌操作),以将所有令牌与其目标对齐。解码器被应用于这个完整的列表(添加了位置嵌入)。如前所述,不需要进行稀疏操作。这个简单的实现引入了可以忽略不计的开销,因为拖曳和反洗牌操作是快速的。

在预训练之后,丢弃解码器,并将编码器应用于未损坏的图像(完整的补丁集)以执行识别任务。
方法
- Masking:将图像划分为规则的非重叠小块,然后对一个子集的小块进行采样,并屏蔽(即移除)其余的小块。具有高掩蔽比的随机采样在很大程度上消除了冗余。
- MAE encoder:编码器是一个ViT,通过添加位置嵌入的线性投影来嵌入补丁,然后通过一系列Transformer块来处理结果集。(每个掩码标记都是一个共享的学习向量,是可以学习得到的。我们将位置嵌入添加到此完整集合中的所有标记;没有这一点,掩码令牌将没有关于它们在图像中的位置的信息。)
- MAE decoder :MAE解码器的输入是由编码的可见patch和遮盖patch组成
- Reconstruction target:本文做了两种实验,第一种是直接产出pixel,然后计算MSE。第二种是对每一个patch计算均值方差,然后归一化。实验发现,归一化处理后representation的质量有提升。
- 提出了MAsked Generative Encoder(MAGE),这是第一个统一图像生成和自监督表示学习的框架。
- 在掩模图像建模预训练中使用可变掩模比可以允许在相同的训练框架下进行生成训练(非常高的掩模比)和表示学习(较低的掩模率)。
- MAGE提出了基于图像语义符的 masked image token modeling 方法
它是一种新的方法,可以通过一个基于token的masked image modeling (MIM)框架,使用不同的masking比例,来统一图像生成和自监督表示学习

现有方法通常使用像素上的简单重建损失,从而导致输出模糊。
- 不同于以前的MIM方法,MAGE的输入和重建目标都是语义标记。
- 对于生成,不仅允许MAGE迭代执行图像生成任务,还允许MAGE学习掩码tokens的概率分布。
- 对于表示学习,使用tokens作为输入和输出允许网络在高语义级别上运行,而不会丢失低级细节。


VQGAN模型是一种用于图像生成的模型,它结合了离散化编码和Transformer的技术。
离散化编码是指使用一个codebook来表示模型中间特征,每个codebook中的编码都对应一个特定的图像块。
Transformer是一种基于自注意力机制的序列模型,可以捕捉长距离的依赖关系,并且可以并行化处理。
VQGAN模型的整体架构如下:
编码器:将输入图像分成多个patches,并将每个patch映射为一个线性嵌入,然后通过寻找codebook中的最近邻编码来得到离散化的特征。
生成器:使用Transformer作为生成器,将离散化的特征作为输入序列,并输出与codebook相同长度的序列,然后通过查找codebook中对应的编码来重建图像。
判别器:使用PatchGAN作为判别器,对生成的图像和真实图像进行判别,并提供对抗损失。
- Tokenization:采用与VQGAN模型中的第一阶段相同的设置,模型对语义标记而不是原始像素进行操作。 (离散化编码是指使用一个codebook来表示模型中间特征,每个codebook中的编码都对应一个特定的图像块。将输入图像分成多个patches,并将每个patch映射为一个线性嵌入,然后通过寻找codebook中的最近邻编码来得到离散化的特征。)
- Masking Strategy:从以0.55为中心、左截0.5、右截1的截断高斯分布中随机采样掩蔽比mr。 如果tokens输入序列的长度为l,随机屏蔽掉mr·ltokens,并用可学习的掩码tokens替换它们。由于mr≥0.5,我们进一步从这些屏蔽tokens中随机丢弃0.5·ltokens。
- Encoder-Decoder Design:将一个可学习的“假”类标记[C0]连接到输入序列。然后将级联序列馈送到视觉变换器(ViT)编码器-解码器结构中,并将其编码到潜在特征空间中。
- 在解码之前,编码器学习的类tokens特征[C]将编码器的输出填充到完整的输入长度。然后,解码器使用填充的特征来重建原始tokens。
- 将一个可学习的“假”类标记[C0]连接到输入序列。然后将级联序列馈送到视觉变换器(ViT)编码器-解码器结构中。ViT编码器将掩蔽和丢弃后的tokens序列作为输入,并将其编码到潜在特征空间中。如MAE所示,类标记位置可以概括输入图像的全局特征。因此,我们使用每个图像特有的[C]来填充编码器输出,而不是使用在不同图像之间共享的可学习掩码tokens。我们在附录中表明,与使用掩蔽tokens相比,该设计提高了生成和表示学习性能(如MAE中所做)。然后,解码器使用填充的特征来重建原始tokens。
- Reconstructive Training :
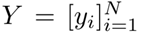 表示目标tokens,
表示目标tokens,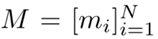
表示确定要屏蔽tokens的对应二进制掩码。
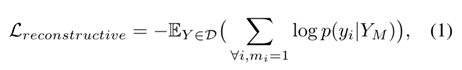
(YM是Y中的未屏蔽tokens的(子集),p(yi|YM)是编码器网络预测的概率,以未屏蔽tokens为条件。在MAE之后,我们只优化了掩码tokens的损失(优化所有tokens的损失会降低生成和表示学习性能)
- Contrastive Co-training:在对编码器输出进行全局平均池化而获得的特性之上添加了两层MLP。然后在MLP头的输出上添加InfoNCE损失[44]:
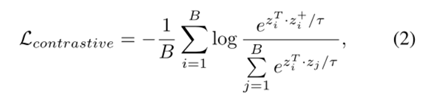
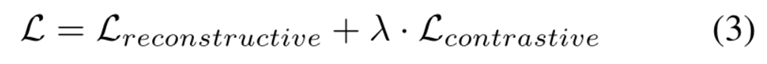
Experiment

预训练模型可以自然地执行类无条件图像生成,而无需对模型参数进行任何微调。
“强”增强(即随机调整作物规模从0.2到1),较弱的增强(随机调整作物比例从0.8到1)更差。a) 从MAGE生成的图像经过默认的强增强训练,即裁剪出图像的较大部分。(b) 从用弱增强训练的MAGE生成的图像,即裁剪出图像的较小部分。

使用默认增强生成的图像可以放大和缩小得多,但图像仍然真实且质量高。
一个可能的原因是,用于计算FID的ImageNet验证集的大小调整为256并居中裁剪。由于FID是基于生成的图像和ImageNet验证集中的图像之间的相似性计算的,因此如果生成的图像的比例较小,FID将更高。然而,这并不一定意味着生成的图像的视觉质量更差。
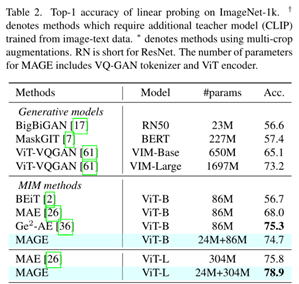
MAGE在ViT-B上比MAE高6.7%,在ViT-L上比MAE高3.1%,在所有MIM方法中实现了最先进的结果。
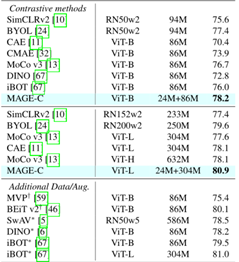
此外,MAGE-C在ViT-B和ViT-L中的准确率分别达到78.2%和80.9%。



MAGE在ImageNet-1k上使用不同掩蔽比分布的线性探测和类无条件生成的结果。结果表明,可变的掩蔽比是实现生成所必需的。此外,使用可变掩蔽比还使得表示学习能够学习更好的特征并实现更好的线性探测性能。


首先,在生成过程中,它允许网络在下一次迭代中迭代使用其输出作为输入,从而实现高质量和多样化的图像重建和生成,如图2和图4所示。
第二,它允许整个网络在语义级别上运行,而不丢失低级细节,从而提取更好的表示。我们通过比较使用MAE和MAGE训练的ViT-B的每个变压器块的特征上的线性探针性能来证明这一点。如图6所示,在整个编码器中,每个变压器块的MAGE线性探头精度始终高于MAE。
第三,量化器防止VQGAN CNN编码器创建的快捷方式。如果我们直接使用提取的特征通过没有量化的VQGAN编码器作为变压器的输入,由于相邻特征像素的感受野具有显著的重叠,因此使用附近的未量化特征像素来推断掩蔽的特征像素要容易得多。如表6所示,在相同的掩蔽策略下,使用未量化的特征实现了低得多的重建损失(3.31 vs.5.76),但线性探针精度也低得多(49.5%vs.74.7%)。这表明预训练任务太容易,导致了快捷解决方案,因此导致了较差的表示。因此,量化步骤对于学习良好的表示是必要的。
这篇关于文献阅读:MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!