representation专题

访问controller404:The origin server did not find a current representation for the target resource
ider build->rebuild project。Rebuild:对选定的目标(Project),进行强制性编译,不管目标是否是被修改过。由于 Rebuild 的目标只有 Project,所以 Rebuild 每次花的时间会比较长。 参考:资料

Journal of Visual Communication and Image Representation (JVCI)投稿经验分享
网站:Journal of Visual Communication and Image Representation | ScienceDirect.com by Elsevier 影响因子:2.678 CiteScore:4.9 SCI:三区 今年3月份,开始向 Journal of Visual Communication and Image Representa
[MOCO] Momentum Contrast for Unsupervised Visual Representation Learning
1、目的 无监督表示学习在自然图像领域已经很成功,因为语言任务有离散的信号空间(words, sub-word units等),便于构建tokenized字典 现有的无监督视觉表示学习方法可以看作是构建动态字典,字典的“keys”则是从数据(images or patches)中采样得到的,并用编码网络来代表 构建的字典需要满足large和co
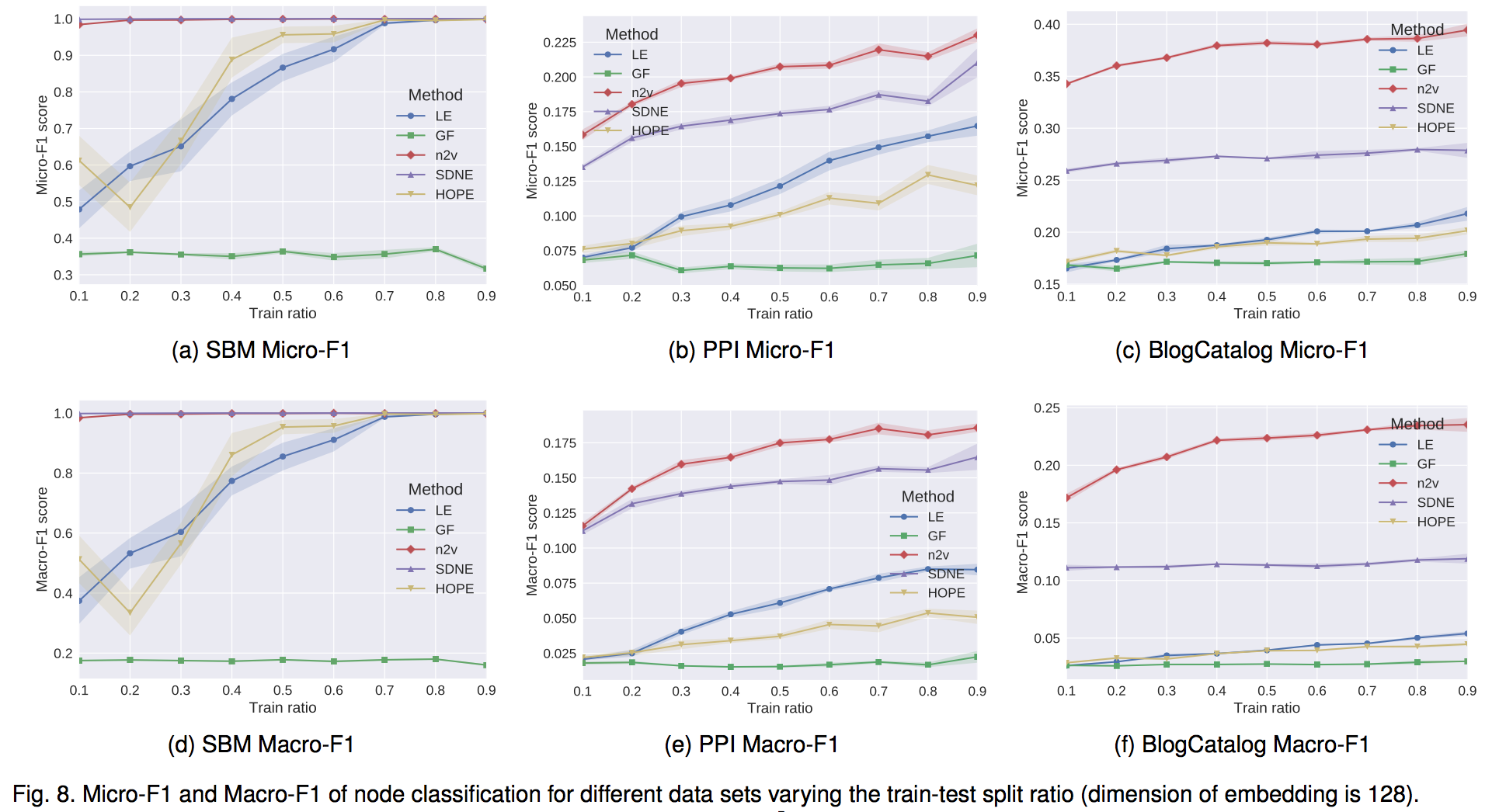
Representation Learning on Network 网络表示学习笔记
Embedding Nodes Encoder-decoder ViewEncoding Methods 1 Factorization based2 Random Walk based3 Deep Learning based 网络表示学习(Representation Learning on Network),一般说的就是向量化(Embedding)技术,简单来说,就是

Graph representation and definition
representation: adjacency matrix 好处是对边或者权重的queries 都是O(1), remove or add an edge也是O(1). 坏处是对点不友好,增加一个点的操作是O(V^2). 而且本身存储太space consuming,同样是点的平方复杂度。导致在sparse matrix里不适用。 Adjacency Matrix is a 2D ar

【多视图感知】BEVFormer: Learning Bird’s-Eye-View Representation
BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers 论文链接:http://arxiv.org/abs/2203.17270 代码链接:https://github.com/fundamentalvision/BEVFormer

表示学习(Representation learning)以及相关(半监督)论文阅读
引言: 这篇博客主要介绍的是表示学习(representation learning),在此基础上,研究了Circle loss这篇CVPR文章。感觉所谓的半监督,目前,在图像分类领域作用寥寥,图数据已经与图像这类数据不是一个类别了。 表示学习(Representation learning)以及相关(半监督)论文阅读 1. 表示学习2. 论文阅读-CVPR-Circle loss:

对比表征学习(一)Contrastive Representation Learning
对比表征学习(一) 主要参考翁莉莲的Blog,本文主要聚焦于对比损失函数 对比表示学习(Contrastive Representation Learning)可以用来优化嵌入空间,使相似的数据靠近,不相似的数据拉远。同时在面对无监督数据集时,对比学习是一种极其有效的自监督学习方式 对比学习目标 在最早期的对比学习中只有一个正样本和一个负样本进行比较,在当前的训练目标中,一个批次的数

【机器学习论文阅读笔记】Robust Recovery of Subspace Structures by Low-Rank Representation
前言 终于要轮到自己汇报了好崩溃。。盯着论文准备开始做汇报ppt感觉一头乱麻,决定还是写博客理清思路再说吧 参考资料: 论文原文:arxiv.org/pdf/1010.2955 RPCA参考文章:RPCA - 知乎 (zhihu.com) 谱聚类参考文章:谱聚类(spectral clustering)原理总结 - 刘建平Pinard - 博客园 (cnblogs.com) 一、问题描

Spring Data Rest学习篇----Object Representation (实体对象展现)
Spring Data Rest---Object Representation(实体对象展现) 对应spring-data-rest-reference 的第7章 在HTTP请求中,Spring Data Rest为一个请求返回一个指定数据格式的对象,目前,Spring Data Rest只支持JSON格式数据,在未来也可以支持其他格式的数据展现。如果用户发现对象模型没有正确地转换到JSON
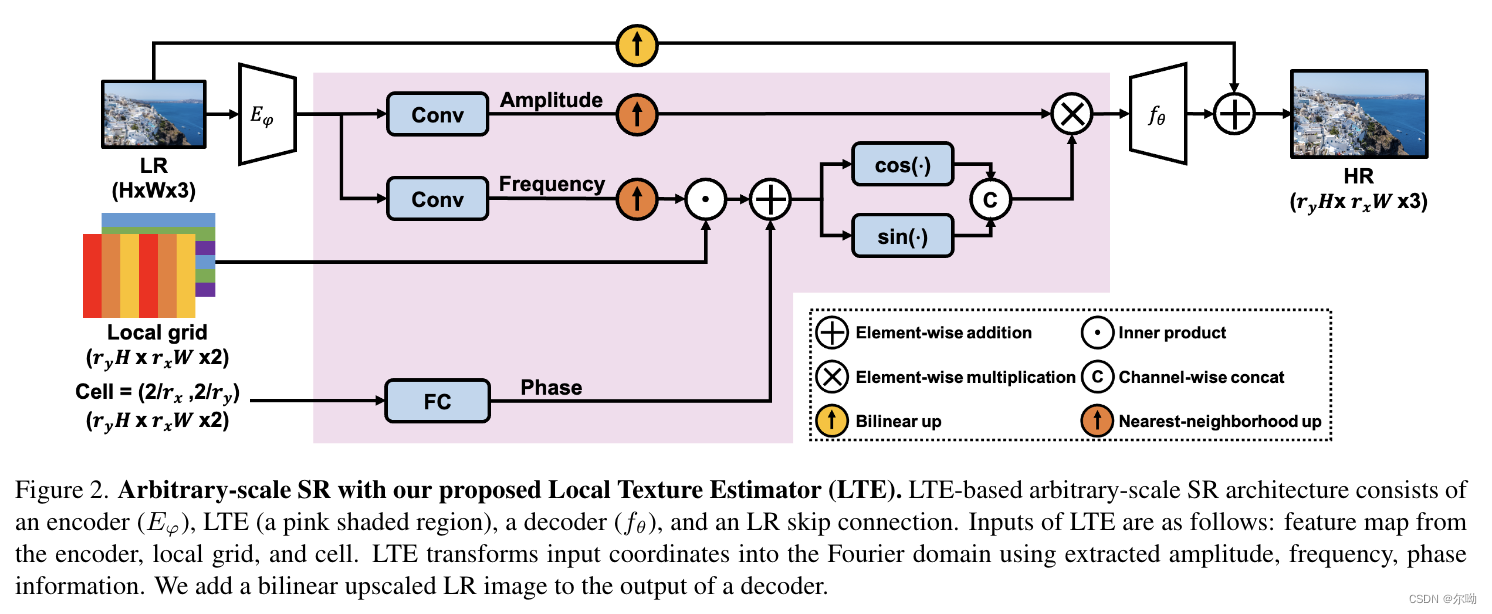
Local Texture Estimator for Implicit Representation Function
CVPR2022https://github.com/jaewon-lee-b/lte 问题引入 现在的任意超分辨率方法使用MLP模型,无法很好的生成高频信息,所以本文提出了一个模型来增加高频信息生成能力,也就是增加超分的细节信息,对应的问题是spectral bias problem;类似于NeRF输入不是直接坐标,而是进行了映射,本文将坐标输入之前也进行了映射; 方法: 整体概览:包含
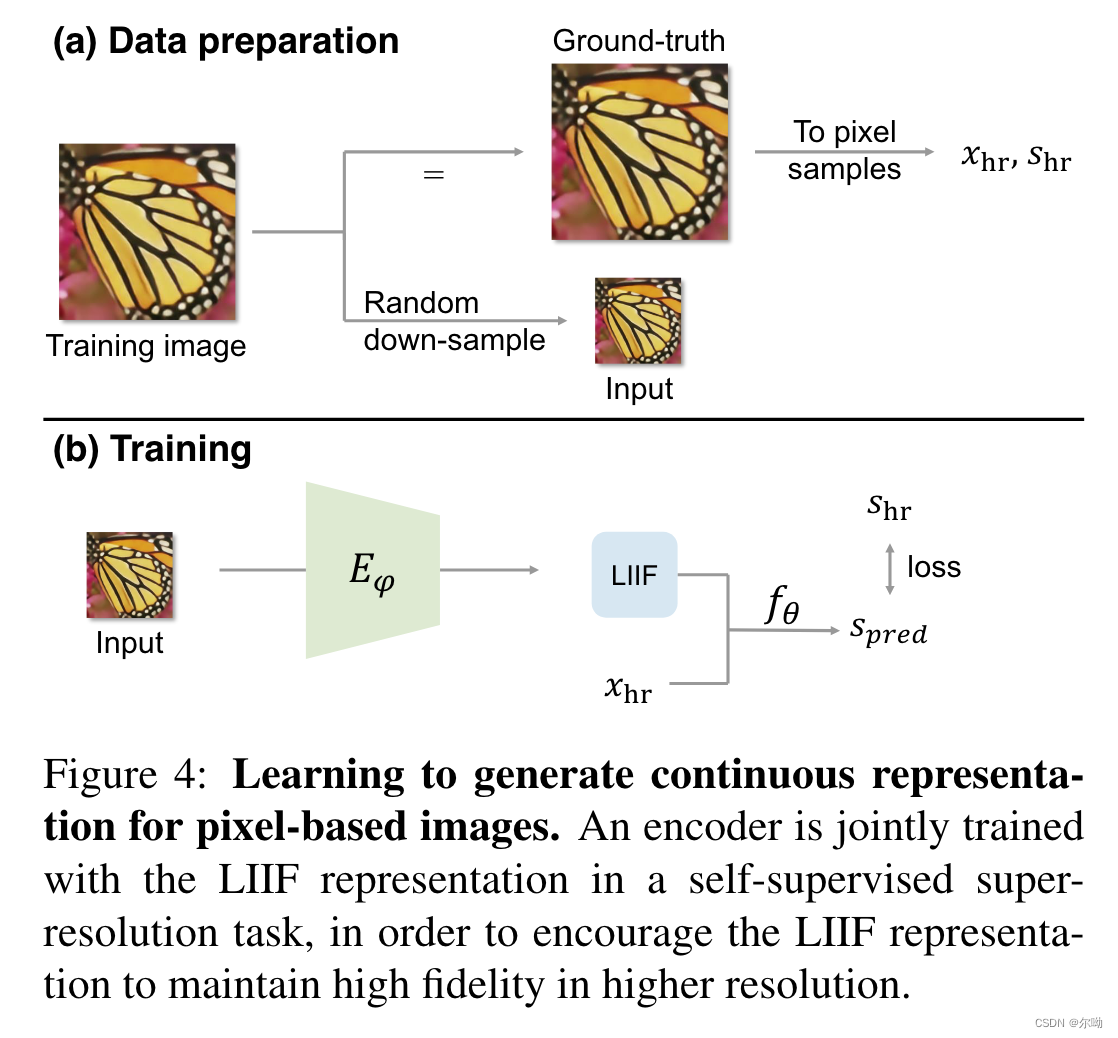
Learning Continuous Image Representation with Local Implicit Image Function
CVPR2021https://github.com/yinboc/liif 问题引入 图像普遍都是使用像素来表示的,而现实世界是连续的,所以本文借鉴3D中neural implicit representation的思想,以连续的方式表示图像;模型输入坐标值和坐标附近的特征,得到该坐标处的像素值,而坐标是连续的,从而得以连续的表示图像;因为连续的特性,使得可以以任意scale来完成超分辨率的

Semantic Video CNNs through Representation Warping中文翻译
基于表示扭曲的语义视频中枢神经系统 摘要1.引言2.相关工作3.将图像中枢神经系统扭曲为视频中枢神经系统3.1NetWarp 4.实验4.1CamVid Dataset4.2Cityscapes Dataset 5.结论和展望 摘要 在这项工作中,我们提出了一种将静态图像语义分割的神经网络模型转换为视频数据的神经网络的技术。我们描述了一种扭曲方法,它可以用很少的额外计算成本

论文解读:(MoCo)Momentum Contrast for Unsupervised Visual Representation Learning
文章汇总 参数的更新,指encoder q的参数,为encoder k,sampling,monentum encoder 的参数。 值得注意的是对于(b)、(c)这里反向传播只更新,的更新只依赖于。 对比学习如同查字典 考虑一个编码查询和一组编码样本是字典的键。假设字典中只有一个键(记为)与匹配。对比损失[29]是指当与它的正键相似,且与其他所有键不相似时(认
3d representation的一些基本概念
顶点(Vertex):三维空间中的一个点,可以有多个属性,如位置坐标、颜色、纹理坐标和法线向量。它是构建三维几何形状的基本单元。 边(Edge):连接两个顶点形成的直线段,它定义了几何形状的轮廓。 面(Face):由边界的边围成的平面区域,通常是三角形(Triangle),因为三角形可以表示任何多边形面,并且在数学上稳定(不会自相交或扭曲)。 网格(Mesh):由许多顶点、边和面组成的集合
An Introduction to Text Representation
文章目录 1. Introduction2. Word Representation2.1. One-hot Encoding2.2. Word Embedding2.2.1. Word2Vec2.2.1.1. Continuous Bag of Words Model(CBOW)2.2.1.2. Skip-Gram Model 3. Sentence Representation3

Uniformer: Unified Transformer for Efficient Spatial-Temporal Representation Learning
Unified Transformer for Efficient Spatial-Temporal Representation Learning 1. Motivation2. Method2.1 MHRA:2.2 DPE2.3 FFN 1. Motivation 高维视频具有大量的局部冗余和复杂的全局依赖关系,而该研究主要是由3D卷积神经网络和视觉Transformer驱
从零开始一步一步掌握大语言模型---(3-词表示-word representation)
词表示和语言模型 词表示是指把自然语言里面最基本的单位,也就是词,将其转换为机器所能理解的过程。 词表示的目的: 1. 计算词之间的相似度; 2. 推理词之间的关系。 1.最早是如何表示一个词呢? 设目标词是X,则用X的近义词、反义词等放在一起表示。或者用X的上位词来表示,如NLP隶属于information sciences,sciences等等。但这种表示方法在于,

ANNA: Enhanced Language Representation for Question Answering
ANNA:增强的问答语言表达 Changwook Jun, Hansol Jang, Myoseop Sim, Hyun Kim, Jooyoung Choi, Kyungkoo Min and Kyunghoon Bae LG AI Research { cwjun, hansol.jang, myoseop.sim, hyun101.kim, jooyoung.choi, mingk24,
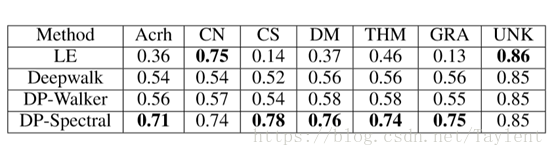
AAAI 2018文章 Representation Learning for Scale-free Networks 翻译
大三上课翻译的一篇paper,之前一直放在草稿箱,发出来供大家参考一下,没有再做修改,哪里翻译有问题或理解不对欢迎指出。 无标度网络表示学习 冯瑞,杨洋,胡文
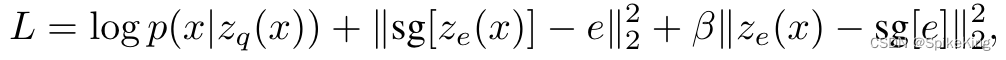
Paper - Neural Discrete Representation Learning (VQ-VAE) 论文简读
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/133992971 问题1:训练完成之后,如何判断 VQ-VAE 的效果? 输入一张训练样本之外的图像,经过编码器,与EmbeddingTable计算最近邻的向量,再把向量输入解码器中,获得重构之后的图像,判断图像

Local occluded face recognition based on HOG-LBP and sparse representation
一、引言 人脸识别技术是一种基于人脸特征的生物识别技术,广泛应用于安全等领域。 目前大多数人脸识别系统都是在自然条件下基于标准的人脸识别, 但人脸是自然结构目标的一种复杂的细节变化,检测和识别容易受到力量变化、面部表情、手势和面部远离、以及其他因素如帽子、眼镜、围巾等的影响 。面部遮挡是导致识别率下降的主要因素。 因此,具有遮挡的人脸识别是一个需要解决的关键问题, 其困难主要体现在遮挡引起的特征丢
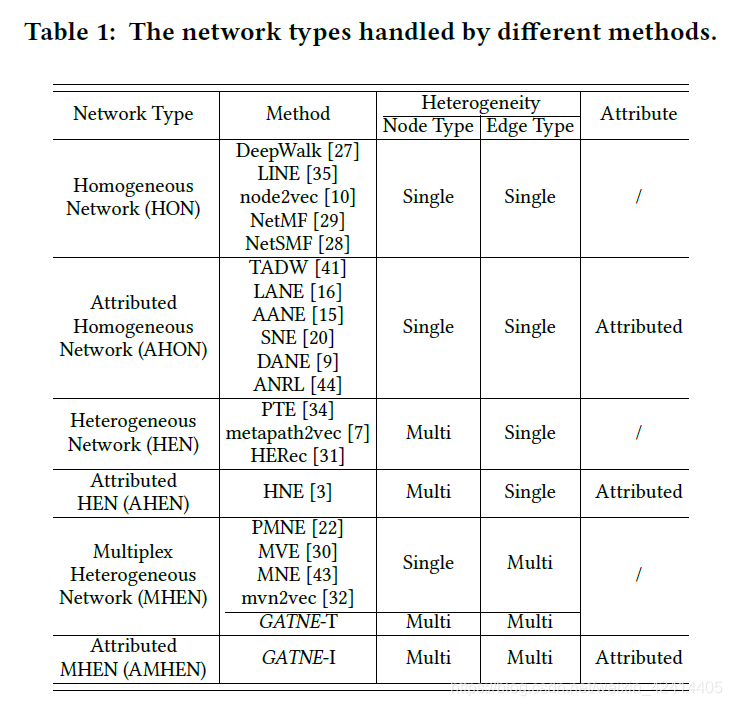
Representation Learning for Attributed Multiplex Heterogeneous Network 论文阅读笔记
摘要部分 网络嵌入(图嵌入)在真实世界中已经有了非常大规模的应用,然而现存的一些网络嵌入(图嵌入)相关的方法主要还是集中在同质网络的应用场景下,即节点和边的类型都是单一类型的情况下。但是真实世界网络中每个节点的类型都多种,每条边的类型也有多种,而且每一个节点都具有不同且繁多的属性。所以本论文提出了一种在Attributed Multiplex Heterogeneous Network中进行嵌入

Representation Learning for Atributed Multiplex Heterogeneous Network
Representation Learning for Atributed Multiplex Heterogeneous Network 本文中心思想问题背景核心思路edge embedding Heterogeneous Network) 本文中心思想 问题背景 异构图分这么多种种类:要注意不是只有节点类型不同的才叫异构图,根据不同的节点类型,和不同的边的连接关系(单
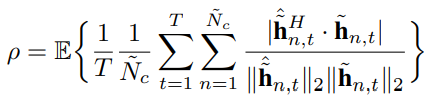
Spatio-Temporal Representation With Deep Neural Recurrent Network in MIMO CSI Feedback简记
Spatio-Temporal Representation With Deep Neural Recurrent Network in MIMO CSI Feedback简记 文章目录 Spatio-Temporal Representation With Deep Neural Recurrent Network in MIMO CSI Feedback简记参考简记LSTM结构深度可分
Representation Learning for Attributed Multiplex Heterogeneous Network论文阅读笔记
论文提出的算法主要是针对复杂的多重异构网络(即节点有属性,节点类型有多种,边的类型有多种)。算法名字叫做GATNE,可以分为直推式GATNE-T和归纳式GATNE-I。 每个节点的embedding包括base embedding和edge embedding。其中base embedding是用在共有的,edge embedding是针对不同类型的边构造的图生成的embedding。 对于GAT