本文主要是介绍ANNA: Enhanced Language Representation for Question Answering,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ANNA:增强的问答语言表达
Changwook Jun, Hansol Jang, Myoseop Sim, Hyun Kim, Jooyoung Choi, Kyungkoo Min and Kyunghoon Bae LG AI Research { cwjun, hansol.jang, myoseop.sim, hyun101.kim, jooyoung.choi, mingk24, k.bae } @lgresearch.ai
摘要
经过预训练的语言模型在各种自然语言处理任务中的表现有了显著的提高。
大多数执行最新结果的现有模型都从数据处理、预训练任务、神经网络建模或微调等不同角度展示了它们的方法。在本文中,我们展示了这些方法是如何单独影响表现的,并且当在训练前模型中联合考虑这些方法时,语言模型在特定的问答任务中表现最好。特别是,我们提出了一种扩展的预训练任务,以及一种新的邻居感知机制,该机制更多地关注相邻的tokens,以捕获上下文的丰富性,用于预训练语言建模。我们的最佳模型在SQuAD 1.1上取得了95.7%的F1和90.6%的EM的最新成绩,并且在SQuAD 2.0基准上也优于现有的预先训练过的语言模型,如RoBERTa、ALBERT、ELECTRA和XLNet。
1引言
问答是回答给定问题的任务,这对语言理解和机器阅读理解能力提出了更高的要求。由于基于transformer编码器的预训练语言模型(Vaswani et al.,2017)极大地提高了国外自然语言处理(NLP)任务(包括QA任务)的表现,QA任务的方法被广泛用于开发应用程序,如2016,2018)涉及证据文件中包含两个或多个单词的文本跨度之间的推理关系(Lee等人,2016)。在本例中,如图1所示,“圣母玛利亚的金色雕像”,这是对“圣母院主楼顶部是什么?”这一问题的正确答案,是由名词和其他词组成的一组词,称为名词短语,在句子中表现为名词。由于预测答案文本的范围,包括开始和结束位置,对于自我监督的训练来说可能是一个挑战,而不是预测单个单词,我们介绍了一种新的预训练方法,该方法将标准的mask方案扩展到更大范围的文本,例如名词短语,而不是实体级别,并证明该方法通过优于现有模型,对抽取QA任务更有效。
在本文中,我们提出了一种新的预训练方法,ANNA(基于N-oun短语的语言表达方法,具有N-eighbor意识注意力),该方法旨在通过对数据处理、预训练任务、注意力机制的综合实验评估,更好地理解句法和上下文信息。首先,我们扩展了传统的训练前任务。我们的模型经过训练的,不仅可以预测单个tokens,还可以在预训练过程中预测整个名词短语。
这种名词短语广度掩码模式让模型在整个广度水平上学习语境化表示,这有利于预测特定提取QA任务的答案文本。其次,我们通过在transformer架构中加入一种新的邻居感知机制来增强自我注意方法(Vaswani et al.,2017)。我们发现,通过掩码对角性不注意矩阵更多地考虑相邻tokens之间的关系有助于语境化的表征。此外,我们使用大量语料库进行预训练语言模型,发现使用大量额外的数据集并不能保证最佳的表现。
我们在SQuAD数据集上评估我们提出的模型,该数据集是预训练语言模型的主要提取QA基准。对于SQuAD 1.1任务,ANNA取得了90.6%的精确匹配(EM)和95.7%的F1分数(F1)的最新成绩。在SQuAD 2.0开发数据集上进行评估时,结果表明,我们提出的方法取得了优于自我监督训练前模型(如BERT、阿尔伯特、RoBERTa和XLNet模型)的竞争性表现。
我们将我们的主要贡献总结如下:•我们提出了一个新的预训练语言模型,ANNA,旨在解决抽取式QA任务。ANNA接受了训练的,能够预测掩码式词组,这是一个完整的名词短语,以便通过利用跨度级表示更好地学习句法和上下文信息。
•我们引入了一种新的transformer编码机制,在transformer编码器块的原始自我注意力上堆叠新的邻居感知自我注意力。该方法在计算注意力得分时,更重要的是考虑了邻居tokens,而不是相同的tokens。
•ANNA在SQuAD 1.1排行榜和outper上建立了最新的最新结果,形成了SQuAD 2.0数据集的现有预训练语言模型。

图1:从SQuAD 1.1数据集中抽取一对问答的文章示例。
2相关工程
经过训练的语境化单词表征最近,人们在训练前语言表征模型方面做出了许多努力,旨在捕获语言和语境信息,这些模型在各种NLP任务中显著提高了表现。ELMo(peters et al.,2018)是一种深入的语境化单词表示法,用于学习跨语言语境中单词使用的复杂特征,使用这些表示法的预训练模型在许多NLP挑战中显示出显著的改进。
BERT(Devlin et al.,2018)是一种预训练语言模型,具有深度双向长-短期记忆,使用掩码式语言建模(MLM)和下一句预测(NSP)目标学习文本中的上下文,用于自我监督的预训练。受BERT影响的最新语言模型(Liu et al.,2019;Lan et al.,2019;Yang et al.,2019b;Radford et al.,2018;Raffel et al.,2019a;Lewis et al.,2019)主要采用transformer架构(Vaswani et al.,2017)进行预训练,但训练的与BERT实施中使用的预训练目标类似或扩展,以提高绩效曼斯。也有许多人试图提高标准transformer机制在语境化单词表示中的能力。
传销的扩展最近的许多研究试图通过在语言建模中扩展传销任务来使用不同的训练前目标,包括BART(Lewis et al.,2019)和T5(Raffel et al.,2019b)。ELECTRA(Clark et al.,2020)介绍了一种新的被替换token检测预训练方法,该方法使用替代样本替换输入的tokens,并检测tokens是否被替换。MASS(Song et al.,2019)在序列到序列框架上进行预训练,其中输入句子的片段被掩码式,而掩码式片段在其解码器部分进行预测。XLNet(Yang et al.,2019b)采用了一种基于跨度的掩码方法,该方法预测在tokens递增的背景下,tokens的掩码式后续跨度。SpanBERT(Joshi et al.,2020)和REALM(Guu et al.,2020)采用了一种广度掩码方案,该方案掩蔽了tokens的广度,而不是随机的单个tokens,模型设计用于在预训练期间学习广度表示。Sim-ilarly、LUKE(Yamada et al.,2020)、ERNIE(Zhang et al.,2019)和KnowBERT(Peters et al.,2019)通过结合实体嵌入知识学习单词和实体的联合表示。
注意力机制的改进由于标准transformer架构具有灵活性,许多研究表明,基于transformer的变体的实现可以进一步提高语言建模和NLP任务(如机器翻译)的表现。(Shaw等人,2018)通过嵌入序列元素之间的相对位置或距离,扩展了自我注意机制,这有利于机器翻译任务的表现提高。(Yang等人,2019a)介绍了一种上下文感知的自我注意方法,该方法通过额外的上下文信息来提高自我注意。(Sukhbatar et al.,2019)提出了一种新的注意力方法,该方法使用存储信息的持久向量扩展自我注意力层,该向量与前馈层的作用类似。(Fan等人,2021)提出了一种mask注意力网络,它是一种顺序分层结构,将新的动态mask注意力层与自注意力和前馈网络结合在一起。
3方法
我们介绍了一种新的transformer编码器架构,它集成了一种新的邻居感知机制,用于预训练语言模型。图2展示了ANNA模型的架构。ANNA扩展了原来的transformer编码器块,包括堆叠在多头自关注层上的邻居感知自关注层。
3.1邻感知自注意力
在本研究中,我们提出了一种邻居感知的注意力机制。我们假设transformer编码器中的单个自我注意力层可能不足以学习上下文,并且基于transformer的预训练模型很难预测下游任务中的正确答案,因为语言噪声在transformer编码器块中的潜在答案的不相关区域中带来。
在注意力矩阵中,有一个对角线模式,说明token更关注自身,但对其他tokens的影响较小。为了更加关注相关标记,我们实现了一种新的邻居感知注意机制,该机制通过在计算注意分数时忽略注意矩阵中的对角性来减轻相同标记的影响。相反,其他tokens更受关注,因此邻居感知机制增强了对输入中tokens之间关系的更好理解。在这里,我们在自我关注和前馈网络之间集成了邻居感知的自我关注层。一个token的原始注意力信息,通过自我注意力和剩余连接,再次通过邻居感知的自我注意力传递,因此token更能反映上下文来理解句子。
由于图2所示的自我关注层采用的是标准transformer架构(Vaswani et al.,2017),我们将自我关注表示为S,该S使用查询(Q)、键(K)和值(V)投影计算,如下所示:
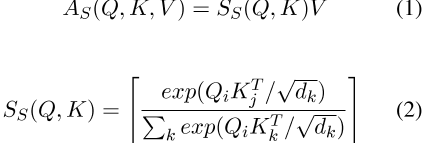
,其中Q、K和V分别表示HW Q、HW K和HW V。H∈ R L×d表示为输入隐藏向量,L是输入序列的长度,dis是隐藏大小。W q、W k、W v∈ R d×d是投影矩阵,d k是查询/键维度。 表示注意力矩阵。
表示注意力矩阵。
我们将邻居感知的注意力层定义为N,如下所示:

,其中M表示mask,其功能是省略捕获相同tokens的交互。0的位置i和j处每对输入tokens x i和x j之间的交互≤ i、 j≤ 除i=j外,计算L。
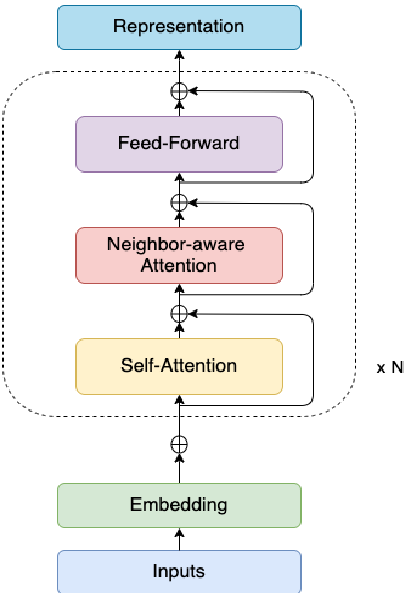
图2:ANNA的架构。
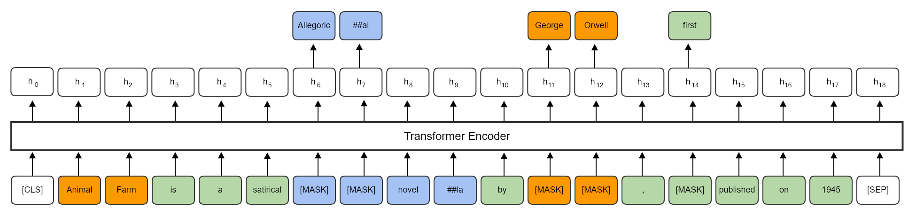
图3:“动物农场是乔治·奥威尔(GeorgeOrwell)于1945年首次出版的讽刺寓言中篇小说”输入序列示例,用于ANNA的预训练。不同类型的掩码方案以这样的颜色进行说明:名词或名词短语span(橙色)、整词掩码(蓝色)和词条token掩码(绿色)的掩码。
3.2预训练任务
我们为训练ANNA模型提出了一项新的训练前任务。我们遵循与BERT类似的传统传销前训练目标(Devlin等人,2018年)。BERT更明智、更有效的做法是将左右文本与传销目标融合在一起,而不是采用单向语言模型(Radford et al.,2018、2019;Brown et al.,2020)或浅显的双向传销模型(Clark et al.,2018;Huang et al.,2015)。
此外,一种新的掩码方案被用于关注名词短语,以便训练我们的语言模型,以便更好地理解句法和词汇信息,考虑到特定的下游任务。这里,我们定义了三种不同的mask方案,如图3所示。首先,我们使用span掩码方案,在SpanBERT采用的span级别上掩蔽一组文本(Joshi et al.,2020)。在这项研究中,spaCy的解析器(Honnibal和Mon-tani,2017)识别的名词或名词短语被随机掩码式,以进行跨度掩码选择。然后,我们应用一种全词掩码方法,一次掩蔽与一个词对应的所有子tokens,而我们随机mask上述两种情况中未包含的tokens。
继BERT之后,我们在输入序列中随机选择15%的tokens,并将80%的选定tokens替换为特殊的token[MASK]。
我们将10%的tokens保留在其余的未更改的代币中,另外10%被随机选择的tokens替换。我们的语言模型还被设计为通过计算交叉熵损失函数,对掩码式跨度中的每个token进行训练预测。然而,由于下游任务的表现下降,RoBERTa(Liu等人,2019)删除了NSP任务,因此本研究未使用BERT实施中使用的下一句预测(NSP)目标。
3.3词汇和标记器
在这项研究中,我们构建了127490个单词的新词汇,这些单词是从英语常用爬网语料库(Raffel et al.,2019a)和英语维基百科转储数据集中提取的。词汇由词条算法标记的子词(30%)组成(Wu等人,2016),其余70%包括原始形式的名词短语词。我们的目标是防止单词超出词汇表,同时保持名词短语为原始形式,以便我们的模型能够容纳许多单词,以便在训练期间更好地学习人类的语言理解。
此外,我们还提出了一种新的单词标记化方法,以适合我们在训练前使用的词汇ANNA模型。这种方法避免了用特殊符号来分隔单词,因为我们的词汇表中包含包含特殊字符的单词,只使用空格来标记名词短语单词。许多研究使用基于子词的词汇表示方法来提高词汇的效率。如表1所示,一个单词由BERT标记器表示的几个子单词单元表示。
然而,我们没有遵循这种传统的tok-enization方法(Wu等人,2016),因为我们使用了一种广度-掩码方案,该方案掩蔽了在训练前过程中随机选择的整个名词短语。如果子字单元用于span掩码方案,则不适合训练模型,因为掩码tokens的长度会变长。当计算注意力得分时,我们还旨在表示一个完整的单词token,而不是子单词单位。我们实现了一个ANNA标记器,以便通过尽可能不分离单词来更好地理解上下文。表1比较了BERT和ANNA标记化者的单词标记化结果。

表1:BERT和ANNA之间标记化结果的比较。
3.4预训练数据集
我们使用像BERT(Devlin et al.,2018)这样的英语维基百科数据集,并添加公开可用的英语语料库,如大型清理版的通用爬网(C4)语料库(Raffel et al.,2019a),Books3(Gao et al.,2020),以及从Web文本(Radford et al.,2019)和OpenWebTextCor-pus(Gokaslan和Cohen)扩展而来的OpenWebText2(OWT2),以预训练我们的模型。附录B中描述了数据集和预处理技术的详细信息。
通过广泛的数据预处理过程,我们获得的Wikipedia、C4、Books3和OWT2的大小分别为12GB、580GB、51GB和22GB。预处理的文本被转换为总共410B字的tokens,用于对我们的模型进行预训练。
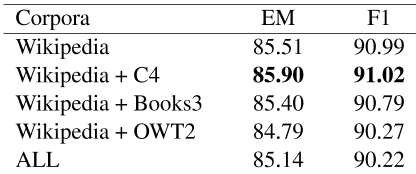
在这项研究中,我们进行了一项实验,以研究在训练前语言模型中使用不同的数据源是否会影响模型在下游任务中的表现。我们比较了使用表2中不同数据集预先训练的模型的表现。我们观察到,当C4被添加到维基百科数据集时,它提高了SQuAD 1.1任务的表现,但在Books3和OWT2数据集上预先训练的模型对表现的提高没有好处。我们还发现,使用包括所有这四个语料库在内的大量数据无助于提高表现。因此,我们使用C4数据和维基百科语料库对ANNA模型进行预训练。ANNA车型的训练前详细信息见附录A。
表2:不同数据源的模型表现预训练的的比较。在SQuAD1.1数据集上评估了使用不同预训练语料库预训练的模型。所有这些都包括维基百科、C4、Books3和OWT2的四个数据集。由于计算资源的限制,本实验采用ANNA基模型。
4个实验
在本节中,我们将介绍ANNA转移到特定抽取式问答任务的微调结果。
我们评估了ANNA的SQuAD 1.1和2.0任务,这些任务是NLP领域著名的机器阅读理解基准,以及一些NLU任务。SQuAD 1.1的数据集由大约10万对问题和答案以及包含答案的维基百科段落组成。
这项任务是预测对应维基百科段落中给定问题的答案文本的正确跨度(Rajpurkar等人,2016)。对于SQuAD 2.0,通过组合50000多个无法回答的问题,数据集扩展到SQuAD 1.1数据集,因此需要系统预测可回答和无法回答问题的答案(Rajpurkar et al.,2018)。我们遵循BERT(Devlin et al.,2018)的微调程序,但提供的SQuAD训练数据集仅用于微调,而BERT使用公开的其他QA数据集扩充其训练数据集。
SQuAD 1.1表3显示了与SQuAD 1.1排行榜上的顶级成绩相比,我们表现最好的系统的结果。我们还将我们的基线与BERT基线进行了比较。在测试数据集上,ANNA在这项任务上建立了一个新的最先进的结果,比LUKE(Yamada et al.,2020)高出EM 0.4分和F1 0.3分。LUKE是排行榜上表现最好的最新系统,它是为单词和实体的上下文化表示而设计的。与SpanBERT(Joshi et al.,2020)相比,ANNA还通过EM 1.8分和F1 1.1分获得了更好的表现,SpanBERT(Joshi et al.,2020)为span表示屏蔽了token的连续序列。
SQuAD 2.0 ANNA在SQuAD 2.0开发数据集上进行了评估,并将结果与表4中公布的预训练语言模型(Devlin et al.,2018;Liu et al.,2019;Lan et al.,2019;Yang et al.,2019b;Clark et al.,2020)进行了比较,这表明ANNA优于所有这些语言模型,尤其是,生产表现比ELECTRA提高0.4分EM和0.2分F1。
GLUE通用语言理解评估(GLUE)基准是一组数据集,用于训练和评估各种自然语言理解任务(Wang等人,2018)。由于目前正在对GLUE进行微调,我们将在附录A中显示完成的任务的结果。
5模型分析
我们在观察方面进行了额外的实验,如数据处理、训练前任务和注意力机制。我们详细分析了这些方法如何影响ANNA在特定下游任务中的表现。在这项研究中,由于计算资源的限制,ANNA基地模型被用于这些额外的实验。
5.1 ANNA标记化的影响
如第3.3节所述,我们构建了一个新的词汇表,其中包含原始格式的名词短语词。为此,我们引入了一种新的单词标记化策略,该策略使单词保持名词短语的原始格式,这适合我们的词汇。我们将我们的标记化方法与标准的单词片段分割方法进行比较,发现ANNA标记化的性能更好,如表5所示。
5.2数据处理的影响
在第3.4节中,我们描述了几种数据预处理技术,以构建高质量的数据集,用于训练ANNA。在这里,我们展示了数据处理技术的使用如何影响抽取式问答任务的表现。在训练前语料库中,存在着不同字长范围的文档。对于生成的输入序列,包含少于100个单词的文档将被过滤掉,而其他文档则被分成多个句子块。由于最大序列长度为512,我们将块的大小限制为不超过大约300个字。我们观察到,数据处理过程为最大序列长度选择合适的字长有助于略微提高表现,如表6所示。
然而,在连续的句子块之间,输入序列的前后有128个tokens重叠,这严重影响了系统的表现。
5.3预训练机制的作用
我们研究了不同的传销目标如何影响特定下游任务模型的表现。在预训练过程中,使用输入序列的深层双向表示对模型进行训练的。首先,我们将词性(POS)标记连接到每个单词上,然后应用全词掩码方法来探索使用句法信息的掩码方法是否有助于理解上下文。我们还mask了被识别为命名实体和名词短语的tokens,而不是掩码单个tokens。在所有的实验中,我们对掩码任务使用相同的15%。表7比较了使用这些传销计划的模型在SQuAD 1.1任务中的结果。与仅屏蔽15%tokens的标准传销方法相比,使用实体和名词短语传销方案的预训练模型提高了性能,但与标准传销方法相比,包括POS标签的掩码单词方法降低了表现。因此,我们使用名词短语传销方法对ANNA模型进行预训练,以获得最终结果。
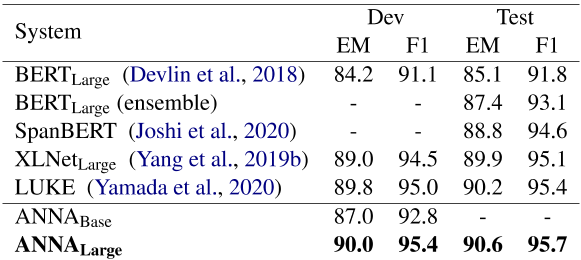
表3:根据SQuAD 1.1数据集评估的系统表现。
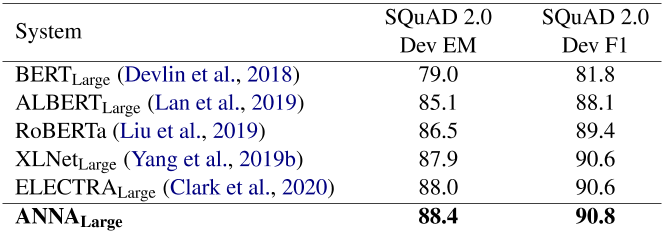
表4:在SQuAD 2.0开发数据集上评估的系统的表现。

表5:我们的标记器与BERT标记器的消融比较研究
5.4邻感知自注意力的影响
我们试图实现一个新的transformer en-coder,重点关注输入tokens中的亲属、实体或邻居,以增强捕获语法和上下文信息的能力。首先,我们在transformer的基础上扩展了原有的自我注意,以考虑输入-kens之间的关系。在计算注意力得分时,只需简单地添加输入tokens的关系矩阵。对于关注命名实体的实体自我注意力,我们在文本中识别命名实体,然后计算这些实体的额外注意力分数,以学习有效的表征。我们在第3.1节中详细描述了邻居感知自我注意的机制。在表8中,我们发现邻居感知的自我注意方法在抽取式问答任务上的表现优于原始的自我注意和其他transformer改进方法。我们认为邻居感知机制可以有效地捕获输入序列中相邻tokens的关系信息。
5.5层堆叠方法的影响
我们研究了在transformer编码器架构中堆叠子层的方法如何影响性能。我们通过协作三个子层,如自我注意力、邻居感知自我注意力和前馈网络无关组合,组成了一个transformer编码器块。
我们使用不同的叠加层组合方法对模型进行评估,并在表9中的SQuAD 1.1数据集上报告结果。
我们观察到,在原来的transformer架构中,用邻居感知的注意力代替自我注意力会将表现降低0.5分。当邻居感知的注意力叠加在自我注意力和前馈网络之间时,模型的性能略好于原来的transformer。自注意、邻居感知和前馈网络的顺序分层结构在精确匹配准则上实现了最佳的表现,这表明我们提出的方法对抽取式问答任务有一定的影响。我们认为,在计算邻居感知注意力中的注意力分数时,通过忽略相同的tokens,在自我注意力层中计算的注意力分数被重新加权到实际相关的tokens,因此邻居感知机制有助于捕获输入tokens之间的关系。
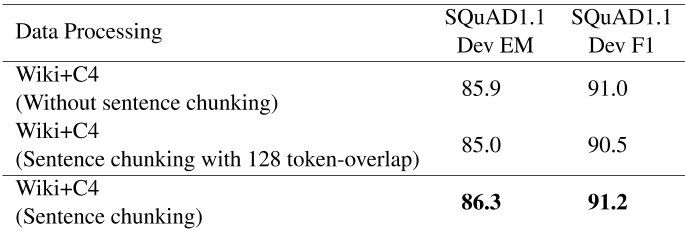
表6:使用不同数据处理技术预训练的模型表现的比较。
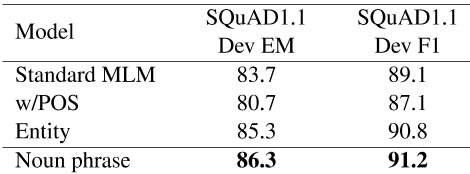
表7:训练前任务中不同掩码方案的结果。
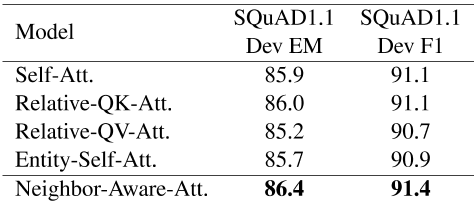
表8:不同transformer变型的模型表现预训练的的比较。Att是注意力的缩写。Self-Att.得分是多次跑步的平均值。
6结论
在本文中,我们提出了一种新的预训练语言表示模型ANNA,该模型通过协作邻居感知机制改进了原有的transformer编码器架构,并对单词和名词短语的跨级上下文表示进行了预训练。
实验结果表明,ANNA在特定的抽取式问答任务上达到了新的水平,其表现优于包括BERT基线在内的已发布语言模型系统,以及相应排行榜上的最新top系统。未来的研究主要有两个方向:(1)验证ANNA对各种NLP任务的竞争力;(2)增强ANNA的稳健性,以便应用于商业中的真实问题回答任务。
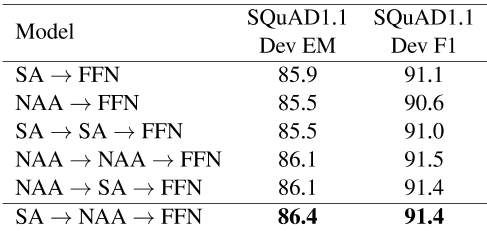
表9:transformer编码器块中自我注意力(SA)、邻居感知注意力(NAA)和前馈网络(FNN)层的不同堆叠方法的表现。SA-FNN分数是多次运行的平均值。
附录
表现GLUE
目前,我们尚未将结果提交给GLUE官方排行榜1,因为我们目前正在对GLUE基准进行微调。相反,我们报告了我们完成评估的任务的结果,如表10所示。我们将表现与两个基线模型BERT和斯潘伯特进行比较,前者是使用标准编码器架构的预训练语言模型,后者是预训练以预测文本跨度的,并激发了我们的名词短语掩码方法。与基线相比,ANNA在每项任务上都优于基线,平均准确率比SpanBERT提高了1.7%。为了进一步提高GLUE的表现,我们将继续进行微调。

表10:GLUE开发套件的比较结果。“Avg.”一栏与官方的GLUE分数略有不同,因为WNLI和AX任务的分数不包括在平均值中。
B预训练数据集和预处理
在这项研究中,我们使用了几个大型语料库进行训练前的语言模型。如表11所示,四个语料库的数据总大小约为900GB。
对于具有大量语料库的预训练语言模型,生成高质量的输入数据至关重要。我们使用启发式预处理技术来提高生成输入序列的数据质量,如下所示:•每个文档被分割成句子,并且由于不完整,我们过滤出包含少于10个单词的句子。此外,对于输入序列,将忽略少于100个单词的文档。
•段落分隔符、特殊字符、URL地址和目录路径等文本噪音通过常规表达式进行启发式过滤。
•对于Books3数据,非英语文档由语言检测模块删除(Shuyo,2010),该模块用于删除通用爬网数据集中以非英语单词书写的文档。
•由于最大序列长度为512个tokens,我们将预处理的文档分割为多个句子块,这些句子块不超过预训练输入的预定义最大长度。
C预训练详细信息
表12总结了我们用于两个模型预训练的超参数:ANNA Base(L=12,H=768,A=12,总参数=160M)和ANNA Large(L=24,H=1024,A=16,总参数=550M)。我们使用最大序列长度512,大型模型和基础模型分别使用学习率为2e-4和1e-4的Adam优化(Kingma和Ba,2014)。
我们的大型模型ANNA large在256 TPU v3上进行了100万步的训练的,批量大小为2048,大约需要10天。
参考文献
Aakash Bansal, Zachary Eberhart, Lingfei Wu, and Collin McMillan. 2021. A neural question answering system for basic questions about subroutines. In 2021 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER) , pages 60–71. IEEE.
Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. arXiv preprint arXiv:2005.14165 .
Kevin Clark, Minh-Thang Luong, Quoc V Le, and Christopher D Manning. 2020. Electra: Pre-training text encoders as discriminators rather than genera- tors. arXiv preprint arXiv:2003.10555 .
Kevin Clark, Minh-Thang Luong, Christopher D Man- ning, and Quoc V Le. 2018. Semi-supervised sequence modeling with cross-view training. arXiv preprint arXiv:1809.08370 .
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understand- ing. arXiv preprint arXiv:1810.04805 .
Vishnu Dutt Duggirala, Rhys Sean Butler, and Farnoush Banaei Kashani. 2021. ita: A digital teaching assistant. In CSEDU (2) , pages 274–281.
Zhihao Fan, Yeyun Gong, Dayiheng Liu, Zhongyu Wei, Siyuan Wang, Jian Jiao, Nan Duan, Ruofei Zhang, and Xuanjing Huang. 2021. Mask attention

表11:四个预训练语料库的统计数据,包括预处理程序前后的数据。

表12:训练前ANNA模型的超参数。
networks: Rethinking and strengthen transformer. arXiv preprint arXiv:2103.13597 .
Leo Gao, Stella Biderman, Sid Black, Laurence Gold- ing, Travis Hoppe, Charles Foster, Jason Phang, horace He, Anish Thite, Noa Nabeshima, et al. 2020.
The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027 . Aaron Gokaslan and Vanya Cohen. Openwebtext cor- pus.
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasu- pat, and Ming-Wei Chang. 2020. Realm: Retrieval- augmented language model pre-training. arXiv preprint arXiv:2002.08909 .
P Hemant, Pramod Kumar, and CR Nirmala. 2022. effect of loss functions on language models in question answering-based generative chat-bots. In Machine Learning, Advances in Computing, Renewable energy and Communication , pages 271–279. Springer.
Matthew Honnibal and Ines Montani. 2017. spaCy 2: Natural language understanding with Bloom embed- dings, convolutional neural networks and incremen- tal parsing. To appear.
Zhiheng Huang, Wei Xu, and Kai Yu. 2015. Bidirec- tional lstm-crf models for sequence tagging. arXiv preprint arXiv:1508.01991 .
Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S Weld, Luke Zettlemoyer, and Omer Levy. 2020. Spanbert: Improving pre-training by representing and predict- ing spans. Transactions of the Association for Com- putational Linguistics , 8:64–77.
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 .
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2019. Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942 .
Kenton Lee, Shimi Salant, Tom Kwiatkowski, Ankur Parikh, Dipanjan Das, and Jonathan Berant. 2016. Learning recurrent span representations for ex- tractive question answering. arXiv preprint arXiv:1611.01436 .
Mike Lewis, Yinhan Liu, Naman Goyal, Mar- jan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. 2019. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461 .
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Man- dar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining ap- proach. arXiv preprint arXiv:1907.11692 .
Matthew E Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word repre- sentations. arXiv preprint arXiv:1802.05365 .
Matthew E Peters, Mark Neumann, Robert L Lo- gan IV, Roy Schwartz, Vidur Joshi, Sameer Singh, and Noah A Smith. 2019. Knowledge enhanced contextual word representations. arXiv preprint arXiv:1909.04164 .
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding by generative pre-training.
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. language models are unsupervised multitask learners. OpenAI blog , 1(8):9.
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2019a. Exploring the limits of transfer learning with a unified text-to-text transformer . arXiv e-prints .
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2019b. Exploring the limits of transfer learning with a unified text-to-text trans- former. arXiv preprint arXiv:1910.10683 .
Pranav Rajpurkar, Robin Jia, and Percy Liang. 2018. Know what you don’t know: Unanswerable questions for squad. arXiv preprint arXiv:1806.03822 .
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. Squad: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250 .
Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. 2018. Self-attention with relative position represen- tations. arXiv preprint arXiv:1803.02155 .
Nakatani Shuyo. 2010. Language detection library for java. Retrieved Jul , 7:2016.
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie- Yan Liu. 2019. Mass: Masked sequence to sequence pre-training for language generation. arXiv preprint arXiv:1905.02450 .
Sainbayar Sukhbaatar, Edouard Grave, Guillaume Lample, Herve Jegou, and Armand Joulin. 2019. Augmenting self-attention with persistent memory. arXiv preprint arXiv:1907.01470 .
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems , 30. Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. 2018. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461 .
Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V
Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, et al. 2016. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144 .
Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, and Yuji Matsumoto. 2020. Luke: deep con- textualized entity representations with entity-aware self-attention. arXiv preprint arXiv:2010.01057 .
Baosong Yang, Jian Li, Derek F Wong, Lidia S Chao, Xing Wang, and Zhaopeng Tu. 2019a. Context- aware self-attention networks. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 33, pages 387–394.
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Car- bonell, Russ R Salakhutdinov, and Quoc V Le. 2019b. Xlnet: Generalized autoregressive pretrain- ing for language understanding. Advances in neural information processing systems , 32.
Zhengyan Zhang, Xu Han, Zhiyuan Liu, Xin Jiang, Maosong Sun, and Qun Liu. 2019. Ernie: enhanced language representation with informative en- tities. arXiv preprint arXiv:1905.07129 .
这篇关于ANNA: Enhanced Language Representation for Question Answering的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)



