answering专题

Large-Scale Relation Learning for Question Answering over Knowledge Bases with Pre-trained Langu论文笔记
文章目录 一. 简介1.知识库问答(KBQA)介绍2.知识库问答(KBQA)的主要挑战3.以往方案4.本文方法 二. 方法问题定义:BERT for KBQA关系学习(Relation Learning)的辅助任务 三. 实验1. 数据集2. Baselines3. Metrics4.Main Results 一. 简介 1.知识库问答(KBQA)介绍 知识库问答(KBQA

Reinforced History Backtracking for Conversational Question Answering论文翻译
公众号 系统之神与我同在 链接如下: http://link.zhihu.com/?target=https%3A//www.aaai.org/AAAI21Papers/AAAI-1260.QiuM.pdf 对话问答的强化历史追溯 摘要 在多轮对话中对上下文历史建模已成为更好地理解问答系统中的用户查询的关键步骤。为了利用语境历史,大多数现有的研究将整个语境视为输入,这将不可避免地面临以下两
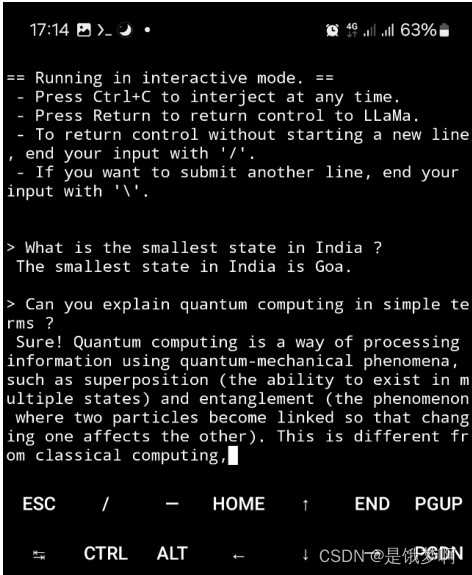
【论文浅尝】Porting Large Language Models to Mobile Devices for Question Answering
Introduction 移动设备上的大型语言模型(LLM)增强了自然语言处理,并支持更直观的交互。这些模型支持高级虚拟助理、语言翻译、文本摘要或文本中关键术语的提取(命名实体提取)等应用。 LLMs的一个重要用例也是问答,它可以为大量的用户查询提供准确的和上下文相关的答案。由于典型智能手机的处理能力有限,当前移动设备上的LLM查询在云中处理,LLM输出被发送回设备。这是ChatGPT应用程序

论文阅读笔记 | 《Constraint-Based Question Answering with Knowledge Graph》
1. 主要内容 在KBQA(基于知识库的问答)的基础上,由于其他问答系统都是回答简单问题,本文提出一种方法可以回答复杂问题(多个限制下的问题),并且提供一个数据集,名为ComplexQuestion,以此评测回答复杂问题的KBQA系统性能。 2个被用作benchmark的数据集:WebQuestions,SimpleQuestions. 多限制问题可以分为六种:多实体限制;答案类型限制;明确

YOLOV8注意力改进方法: CoTAttention(Visual Question Answering,VQA)附改进代码)
原论文地址:原论文下载地址 论文相关内容介绍: 论文摘要翻译: 具有自关注的Transformer导致了自然语言处理领域的革命,并且最近在许多计算机视觉任务中激发了具有竞争性结果的Transformer风格架构设计的出现。然而,大多数现有设计直接使用二维特征图上的自关注来获得基于每个空间位置上的孤立查询和键对的关注矩阵,而没有充分利用相邻键之间的丰富上下文。在这项工作中,我们设计了一个新颖的
读《Reasoning with Heterogeneous Graph Alignment for Video Question Answering》
摘要 主要的视频问题回答(VQA)方法是基于细粒度表示或特定于模型的注意机制。他们通常分别处理视频和问题,然后将不同模式的表示输入后续的后期融合网络(决策层融合?)。虽然这些方法使用一种模态的信息来增强另一种模态,但它们忽略了在统一模态中整合模态间和模态内的相关性。 本文提出了一个深度异构对视频图对齐网络。从四个步骤来探索网络架构:表示、融合、对齐和推理。在我们的网络中,模态间信息和模态内信息可

ANNA: Enhanced Language Representation for Question Answering
ANNA:增强的问答语言表达 Changwook Jun, Hansol Jang, Myoseop Sim, Hyun Kim, Jooyoung Choi, Kyungkoo Min and Kyunghoon Bae LG AI Research { cwjun, hansol.jang, myoseop.sim, hyun101.kim, jooyoung.choi, mingk24,
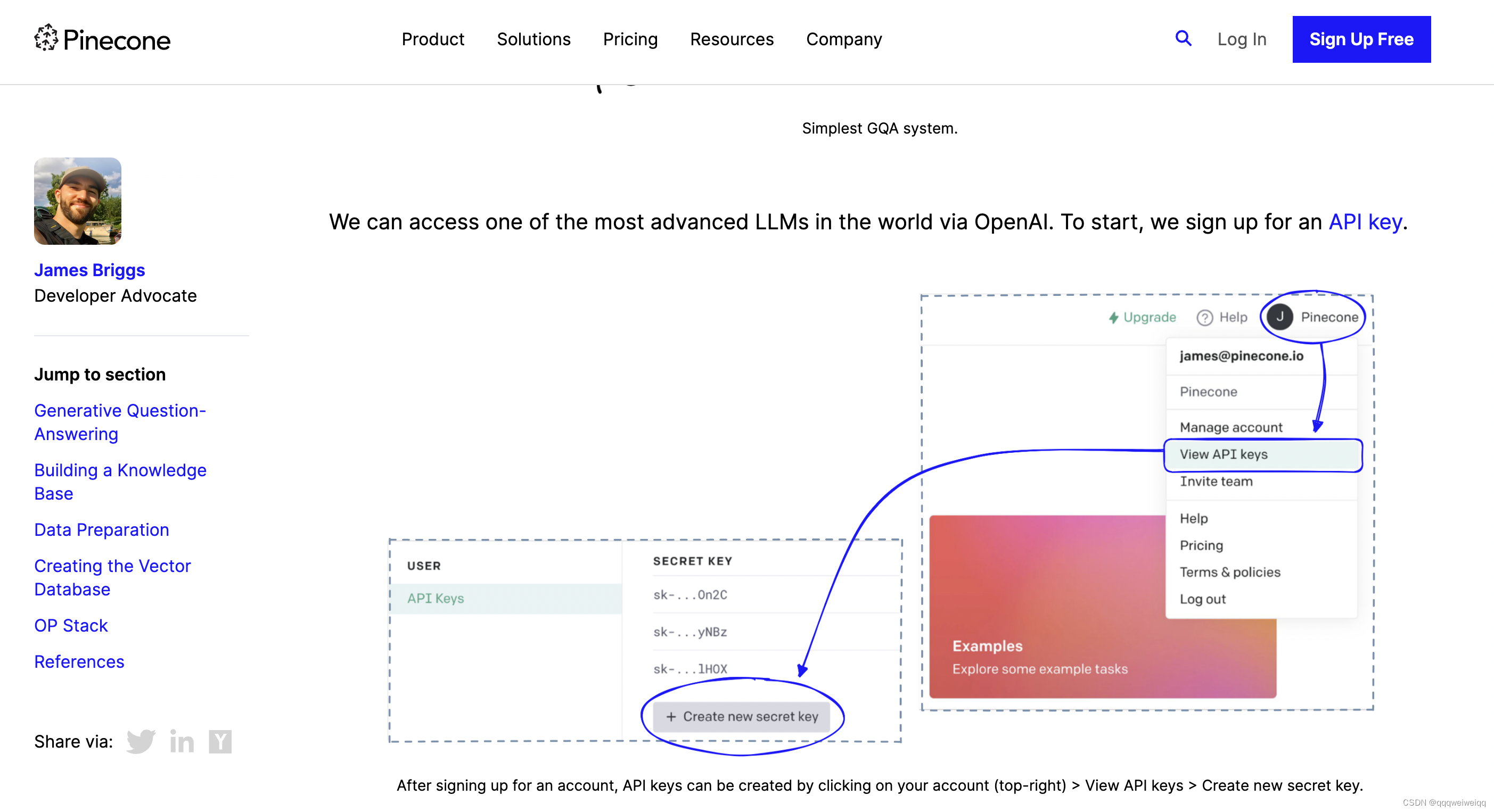
基于kbqa 的复旦大学论文解释 learning question answering over QA corpora and knowledge bases(二)
我们表示第i项其中,,所以,所以我们建立了QA与X的似然线性关系, (13) 最大似然估计QA就是等价最大似然估计X,(2)通过边际化联合概率,得到,基于总体的模板t和谓语p,似然如公式(14),我们阐述整个过程如图4,
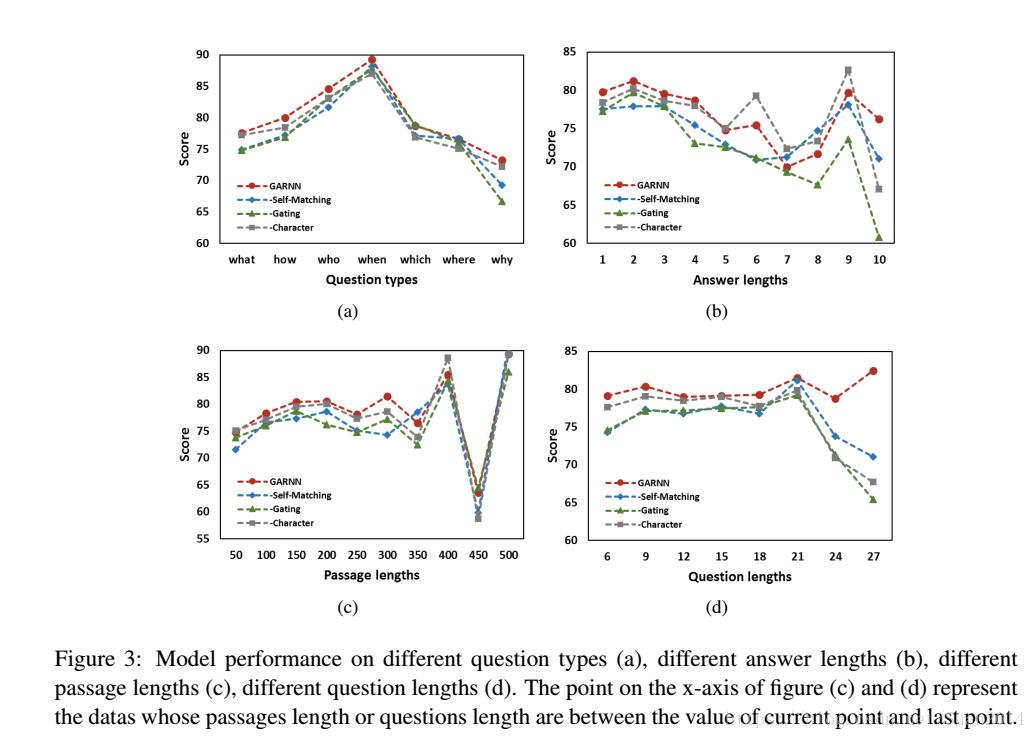
Gated Self-Matching Networks for Reading Comprehension and Question Answering论文笔记
原文下载链接 摘要 检索式问答系统试图从文档中获取问题的答案。一般步骤是先从一众文档中检索相关文档,然后再进一步检索文档回答问题。本文解决的是后一步,即阅读理解式的问答系统。文章基于端到端的多层神经网络模型从篇章中获取答案。 模型分为四部分:一是使用多层双向神经网络编码问题和篇章的语义向量表示;二是使用门注意力机制得到问题感知的篇章的语义向量表示;三是通过 Self-Matching 注意力
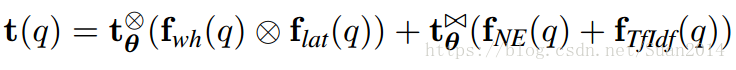
Discriminative Information Retrieval for Question Answering Sentence Selection论文笔记
原文下载地址 摘要 该算法提出场景:text-based QA,即给定一段文字说明,提出问题,从文字说明中找出相应答案作答。 text-based QA算法的主要步骤包含三个:1)获取可能包含答案的段落;2)候选段落的重排;3)提取信息选择答案 本文的算法主要是解决第一个步骤 算法 算法主要框架: 预处理:将文字说明切成一

Scene Understanding for Autonomous Driving Using Visual Question Answering
摘要 本文研究了dot-products存在于自我注意机制作为自动驾驶的可解释性技术的可行性。一个视觉问题识别(VQA)框架实现了三种类型的问题有关的道路标志和交通灯的存在或不存在。该模型进行评估的编码单模态和多模态编码:标准版本和修改版本的学习跨模态编码器表示从变压器(LXMERT)框架。我们提出的两个模型架构的问答任务的数值结果,与整体准确率分别为79.7%和78.5%,整体F1分数分别为0

(reading)Revisiting Visual Question Answering Baselines
阅读后收获:对于VQA,使用MLP model,将I-Q-A作为输入做caption效果要好于以I-A作为输入,将I-A作为输入做caption效果要好于以Q-A作为输入,将Q-A作为输入做caption效果要好于以A作为输入,但是仅仅以A作为输入,在Visual7W telling task中就可以达到50.7%的准确性,说明了仅仅学习A分布的bias就可以取得不错的效果。另外结合不断填充扩

论文笔记:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
论文链接:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering Bottom-Up Attention Model 本文的bottom up attention 模型在后面的image caption部分和VQA部分都会被用到。 这里用的是object detection领域
【论文阅读笔记】Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering.
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering. 2018-CVPR P. Anderson, X. He, C. Buehler, D. Teney, M. Johnson, S. Gould, and L. Zhang. 什么是“自上而下”,“自下而上”? 类比人类视觉
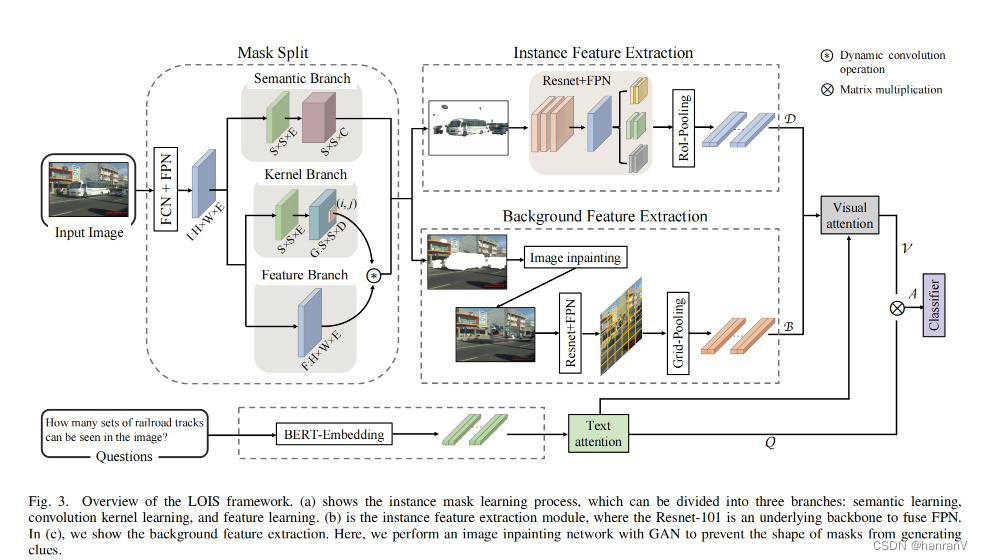
LOIS: Looking Out of Instance Semanticsfor Visual Question Answering
目录 一、论文速读 1.1 摘要 1. 2 论文概要总结 二、论文精度 2.1 论文试图解决什么问题? 2.2 论文中提到的解决方案之关键是什么? 2.3 用于定量评估的数据集是什么?代码有没有开源? 2.4 这篇论文到底有什么贡献? 2.5 下一步呢?有什么工作可以继续深入? 一、论文速读 论文arxiv链接 1.1 摘要 视觉问答(VQA)作为

论文阅读Ask Me Anything: Free-form Visual Question Answering Based on Knowledge from External Sources
Ask Me Anything: Free-form Visual Question Answering Based on Knowledge from External Sources 目前开始更关注于含有外部知识的视觉问答,鉴于这方面的论文和博客较少,就自己写了一篇。内容如有不妥,欢迎评论指正。 文章链接:https://openaccess.thecvf.com/content_cvp

Ask Me Anything:Free-form Visual Question Answering Based on Knowledge from External Sources
这篇文章将自动生成的图像描述与一个外部的Knowledge bases相融合,对问题进行预测。图像描述生成主要来自于image captions集,并且从Knowledge bases提取基于文本的外部知识。框架图: 给定图像-问答对,首先利用CNN提取图像的Attributes集合。这些Attributes涉及范围很广,包括object,scenes,action,modifie

CVPR 2019 Progressive Attention Memory Network for Movie Story Question Answering
动机 人类具有先天的认知能力,可以从不同的感觉输入中推断出5W和1H的问题,这些问题涉及who,what,when,where,why以及how,在机器上复制这种能力一直是人类的追求。 近年来,关于问题回答(QA)的研究已成功地受益于深度神经网络,并显示出对textQA,imageQA,videoQA的显着改进。 本文考虑了电影故事QA ,旨在通过观察与时间对齐的视频和字幕后回答有关电影内容
论文阅读-DISTILLING KNOWLEDGE FROM READER TORETRIEVER FOR QUESTION ANSWERING
论文链接:https://arxiv.org/pdf/2012.04584.pdf 目录 方法 交叉注意机制 交叉注意力得分作为段落检索的相关性度量 用于段落检索的密集双编码器 将交叉注意力分数提取到双编码器 数据集 方法 我们的系统由两个模块组成,即检索器和阅读器,遵循开放域问答的标准管道。 给定一个输入问题,这些模块用于分两步生成答案

【VQA文献阅读】(CVPR2019)Answer Them All! Toward Universal Visual Question Answering Models ——直观了解最新VQA数据集
【VQA文献阅读】(CVPR2019)Answer Them All! Toward Universal Visual Question Answering Models ——直观了解最新VQA数据集 前言:有些文献虽然不是综述,但其中多多少少都有介绍数据集的情况,对目前公开的VQA数据集有了详细的介绍,可以起到类似综述的效果,让读者能更好的对现有数据集有更加直观的认识,其功用类似综述,该文章

【文献阅读】VQA入门——Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge
本人在读研一,想要学习多模态这一块的工作。我在这里记录下我看的第一篇论文《Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge》的看后总结。若有不当之处,请斧正! 论文地址:https://arxiv.org/abs/1708.02711 在介绍论文之前,先给大家讲一下什么叫做VQA VQ
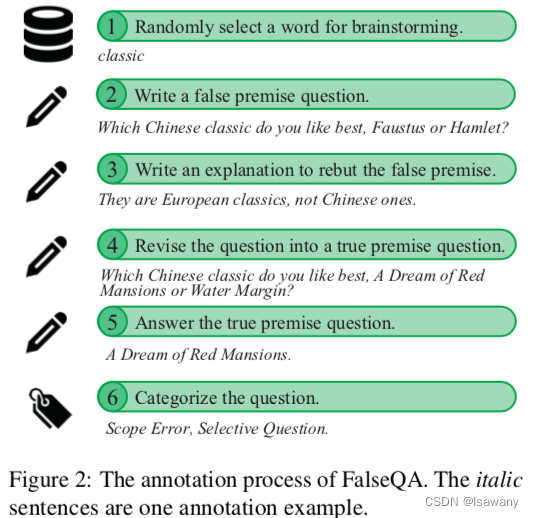
论文笔记--Won’t Get Fooled Again: Answering Questions with False Premises
论文笔记--Won’t Get Fooled Again: Answering Questions with False Premises 1. 文章简介2. 文章概括3 文章重点技术3.1 大模型面对FPQs的表现3.2 False QAs数据集3.3 训练和评估 4. 文章亮点5. 原文传送门 1. 文章简介 标题:Won’t Get Fooled Again: Answer
Evaluating Open-Domain Question Answering in the Era of Large Language Models
本文是LLM系列文章,针对《Evaluating Open-Domain Question Answering in the Era of Large Language Models》的翻译。 大语言模型时代的开放域问答评价 摘要1 引言2 相关工作3 开放域QA评估4 评估开放域QA模型的策略5 正确答案的语言分析6 CuratedTREC上的正则表达式匹配7 结论 摘要 词汇