本文主要是介绍读《Reasoning with Heterogeneous Graph Alignment for Video Question Answering》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
主要的视频问题回答(VQA)方法是基于细粒度表示或特定于模型的注意机制。他们通常分别处理视频和问题,然后将不同模式的表示输入后续的后期融合网络(决策层融合?)。虽然这些方法使用一种模态的信息来增强另一种模态,但它们忽略了在统一模态中整合模态间和模态内的相关性。
本文提出了一个深度异构对视频图对齐网络。从四个步骤来探索网络架构:表示、融合、对齐和推理。在我们的网络中,模态间信息和模态内信息可以在异构图上同时对齐和交互,并用于跨模态推理。
1.引言
视频问题回答(VideoQA)旨在通过给出视频和相关文本问题自动推断正确答案,涉及来自两个领域的异构数据,即时空视频内容和语言中的单词序列,试图揭示视频内容和单词语义之间潜在的相关性,这可以被视为模态间的相关性。
适当结合视频中的相关性或单词序列之间的依赖性确实有助于提高VideoQA的性能,这可以看作是利用了内相关性。一种常见的做法是分别使用基于RNN的编码器对视频和单词序列进行编码,进一步也有提出了异构记忆来融合视觉特征,同时设计了另一个记忆来处理问题
大多数情况下要以更灵活的方式整合模态间和模态内的相关性(也称为异构关系),可能进一步有利于VideoQA的推断
首先建立视频中单词和视觉区域之间的语义关系,然后定位动作。此外,我们需要具有语义相似性的模态间对齐来找出时间推理后的动作。然而,目前的VideoQA方法缺乏一个统一的模型来同时建模和推理模态间和模态内关系。
2.相关
2.1 VQA
(Wang et al. 2018; Gao et al. 2018;Fan et al. 2019; Kim et al.
2019)应用了动态记忆网络,通过更好的表征和融合策略来增强智力
但现有的方法侧重于多模态表示和融合,关于对齐和推理的工作仍然很少。
2.2 多模态信息融合
早期融合包括向量拼接、元素加法和元素乘法。然后将输出投影到一个联合空间中,然后接下游神经网络
注意机制被认为是增强模式间交互作用,避免噪声的有效方法。
共同注意机制被认为是另一种有效的解决方案,之前的工作(Nguyen and Okatani 2018; Gao et al. 2019; Yu et al. 2019;Li et al. 2019)提出了各种针对特定任务的结构
双线性池也是通过计算外部乘积来融合多模态向量的有效途径,并提供了两个向量的所有元素之间的乘法交互作用。
3.方法
认为每个单词和每个视频拍摄都包含相同的语义信息,并且可以集成到一个统一的模块中。
设计了一个包括全局和局部融合在内的并行架构。为了联合建模视觉和语言因素(镜头或单词),首先获得了上下文的视觉和语言表征。
通过一个模块化的共注意嵌入操作,将视觉和语言向量嵌入到一个公共空间中。
在接下来的异构图推理部分,首先提出一种对齐策略来获得加权邻接矩阵,然后利用邻接矩阵构造一个多模态交叉推理的多层图卷积网络。
3.1视觉上和语言上的上下文表示
三维卷积(C3D) (Tran et al. 2015)
(反正就是提前通过两种卷积提取出来视频的视觉特征)拼接视觉特征再投影到统一空间
语义特征也提前准备好,然后和视觉特征分别通过GRU学习上下文聚合时间提高推理能力
3.2跨模态节点融合和对齐
除了识别和记忆视觉和语义内容,还需要学习联合空间中不同模态之间的交互作用。(这不是还没到联合空间呢吗?)
可以认为共注意机制是一种视觉通道和文本通道之间的跨模态融合和对齐方法,以一种模态作为线索,通过语义相似性来确定另一种模态。(看了下代码大概是通过两个模态间的什么掩码乘积得到)
共同注意机制根据Q和K的兼容性函数计算V的加权和,并且两个模态特征交替作为Q。自注意是同一组Q和K的一种特殊情况。(算是解释多头注意力QKV的意思吗?说是相似性什么的,仔细一看Q和K的计算其实就有点余弦相似度的意思?)
记MQ、MK、MV,有(经典公式)
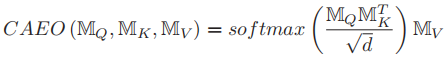
这里Q和K对应不同模态,K和V是同一模态。通过计算两种模式之间的相似性并执行软选择,将Q的信息嵌入到K的特征空间中。
对共注意嵌入操作(CAEO)的一个合理的解释是软最近邻soft nearest neighbors理论(Goldberger et al. 2005)。首先缩放为具有unit norm
(归一化?应该就是对应这里有的layernorm)的softmax点积操作相当于余弦相似性(还真是),而soft KNN在欧式距离上使用softmax值。该操作的意义在于,对于Q中的每个向量,取V向量的加权和作为其软最近邻。因此,CAEO的输出可以看作是V空间中的向量,但也嵌入了Q的信息。
从语言空间转变到视觉空间。
从视觉空间转变到语言空间。
(这俩其实就是对视觉和语义作为Q和K的排列组合作为单射)
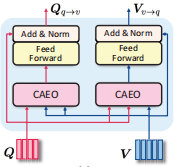
共注意力转变。
用于学习融合和对齐的双射
伪孪生(Pseudo-siamese)共注意力转换
(伪孪生区别于孪生就是权值不共享,线性变换是独立的)
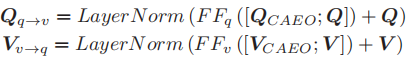
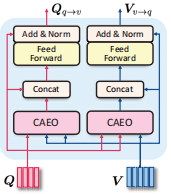
孪生共注意力转变
3.3异构图推理
交叉嵌入的视觉因素(视频拍摄)和语言因素(单词)具有协调的语义信息,可以在图结构的神经网络中进行交互推理。
基于之前的表示和融合步骤,可以得到语言模态和视觉模态的两个交叉嵌入特征,这里构建一个无向异构图,每个视频拍摄和每一个问题词作为一个节点。属性矩阵就是两个矩阵的拼接
跨模态对齐的邻接矩阵。
边权初始化,形式化为邻接矩阵,是图的一个重要的先验知识。因为一个问题倾向于关注视频的局部而不是整体,而视觉和语言因素在各自的模式中也权重不平等。
而通过分别对两个模态做变换后求乘积得到相似度矩阵,可以学习模态间的异构点和模态内的同构点(really?)
异构图的推理
最近的VQA研究 (Teney, Liu, and van den Hengel 2017; Norcliffe-Brown, Vafeias, and Parisot 2018)指出,图卷积网络可以有效地进行模态内推理。这些方法通常将图像区域的特征作为图节点
(图结构表达?),并在不同区域之间建立基于图的推理模型。
于是通过AXW图卷积再通过自注意力池得到经过局部推理后反映潜在的跨模态关系的局部结果向量的局部分布(好玄学啊,凭啥得到的结果有这能耐?)
3.4全局和局部信息融合
由于图结构推理模块更关注局部因素之间的交互作用,因此它在一定程度上失去了全局语义信息的集成能力(平滑现象吗?)。
3.5答案预测与评价
这篇关于读《Reasoning with Heterogeneous Graph Alignment for Video Question Answering》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





