本文主要是介绍【论文浅尝】Porting Large Language Models to Mobile Devices for Question Answering,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Introduction
移动设备上的大型语言模型(LLM)增强了自然语言处理,并支持更直观的交互。这些模型支持高级虚拟助理、语言翻译、文本摘要或文本中关键术语的提取(命名实体提取)等应用。
LLMs的一个重要用例也是问答,它可以为大量的用户查询提供准确的和上下文相关的答案。由于典型智能手机的处理能力有限,当前移动设备上的LLM查询在云中处理,LLM输出被发送回设备。这是ChatGPT应用程序和大多数其他LLM支持的聊天应用程序的标准工作流程。
但是有些情况是不可取的,例如,对于在连接有限或互联网流量受到严格监控和监视的地区工作的记者而言(例如在专制政权中)。在这种情况下,处理必须在设备上完成。
因此,在这项工作中,我们演示了如何将LLM高效地移植到移动设备上,以便它们可以在移动设备上以交互速度本地运行。
LLM framework for on-device inference
最初,我们试图通过tensorflow Lite(TF Lite)框架在移动设备上本地进行LLM推理,因为它是最流行的on device推理框架。但是对于LLM来说,Hugging Face模型上可用的几乎所有微调模型都只提供PyTorch权重,因此必须转换为TFLite。结果发现比较困难。
因此,我们选择了llama.cpp framework ,这是一个非常灵活且自包含的C++框架,用于在各种设备上进行LLM推断。它可以在CPU或GPU/CUDA上运行最先进的模型,如Llama/Llama 2、Vicuna或Mistral,并提供大量选项(例如设置温度、上下文大小或采样方法)。它支持各种低于8位的量化方法(每个参数从2位到6位),这对于在内存有限的智能手机上运行具有数十亿参数的模型至关重要。
为了构建llama.cpp框架的C++库和可执行文件,需要一个标准的Linux构建工具链,包括终端(shell)、命令行工具、CMake/Make、C/C++编译器和链接器等等。对于Android,幸运的是,通过Termux app 可以获得这样的构建工具链。它可以通过Android开源软件包管理器F-Droid 安装,不需要root访问设备。
安装Termux后,我们在那里打开一个控制台,并通过Termux软件包管理器pkg安装必要的工具(如wget、git、cmake、clang编译器)。我们还在PC上安装了Android屏幕镜像软件scrcpy,这样我们就可以直接在PC上控制设备并镜像其屏幕。
为了构建llama.cpp二进制文件,我们现在从各自的github repo中克隆其最新源代码。我们调用CMake生成Makefile并通过Make命令构建所有二进制文件。我们通过在CPU上进行模型推理来编译二进制文件。
Model selection and prompt format
在Hugging Face model hub上,有许多预训练的大型语言模型可用,这些模型在网络架构、模型大小、训练/微调过程以及数据集和任务方面各不相同。
经过一些实验,我们选择了具有30亿个参数的Orca-Mini-3B模型。它在最近的智能手机上以交互速度运行,并通过Orca方法的模仿学习进行微调,从而对用户查询提供体面的响应。我们采用一个量化模型,每个参数约为5.6位,在器件上大约占用2.2 GB的CPU RAM。
提示格式如下例所示:

Experiments and evaluation
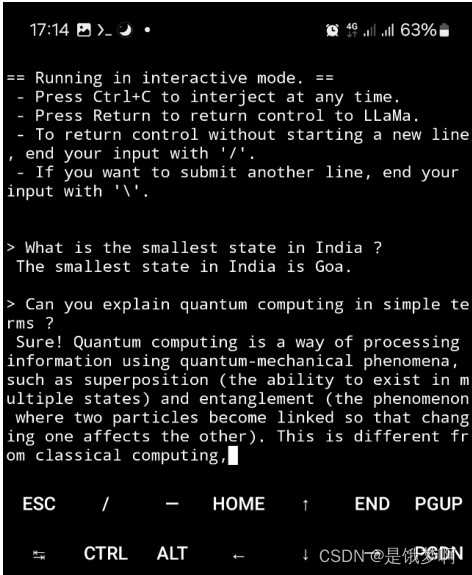
我们对所选模型进行了主观评估,测试了该模型对与政治、地理、历史等不同主题相关的用户查询的响应。从测试中我们可以推断出该模型为大多数用户查询提供了准确而忠实的答案。当然,像每个LLM一样,它有时会产生幻觉(提供错误信息)。下图1显示了用于直接聊天的LLM应用程序的输出示例。LLM为来自不同领域的问题提供正确答案。
该模型的输出生成速度足以在三星Galaxy S21智能手机上进行互动聊天。
这篇关于【论文浅尝】Porting Large Language Models to Mobile Devices for Question Answering的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)


