本文主要是介绍Gated Self-Matching Networks for Reading Comprehension and Question Answering论文笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文下载链接
摘要
检索式问答系统试图从文档中获取问题的答案。一般步骤是先从一众文档中检索相关文档,然后再进一步检索文档回答问题。本文解决的是后一步,即阅读理解式的问答系统。文章基于端到端的多层神经网络模型从篇章中获取答案。
模型分为四部分:一是使用多层双向神经网络编码问题和篇章的语义向量表示;二是使用门注意力机制得到问题感知的篇章的语义向量表示;三是通过 Self-Matching 注意力机制提炼篇章的语义向量表示,从全部篇章中编码最终语义向量表示;四是利用 Pointer-network 来预测答案边界,从而得到最终答案。在 Stanford 发布的机器阅读理解比赛数据集 SQuAD 上,本文提出的模型的单模型和集成模型结果都分别排名第一。
Task 描述
对于阅读理解式的问答系统,给出了一个段落P和问题Q,我们的任务是根据在P中找到的信息预测答案A.
Gated Self-Matching Networks(门自匹配网络)
整个框架如Figure 1所示,首先,问题和段落分别由双向循环网络处理。 然后,我们将问题和段落通过门注意力的循环网络(gated attention-based recurrent networks)相匹配,从而获得该段落的问题感知表示。 之后,用自匹配注意力来整和整个段落的信息以进一步优化段落的表达,然后将其输入到输出层来预测答案的边界。

1.问题与段落编码
问题,段落
,首先将words转换成word-level的embeddings
和
以及character-level的embeddings
和
,character-level的embeddings是双向RNN的最后一个隐含状态,之所以加上character-level的embeddings,是因为其能够处理out-of-vocab(OOV)的情况,通过双向RNN(所有网络中的RNN都是采用的GRU,因为GRU和lstm的效果相当,但是计算量较小)得到Q和P的新的表达
和
:
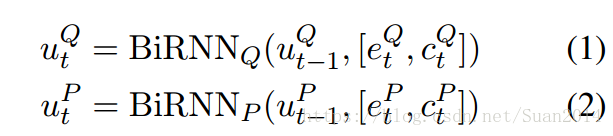
2.门注意力RNN(Gated Attention-based Recurrent Networks)
这一层的目的是将问题中的信息添加到段落的表达中:
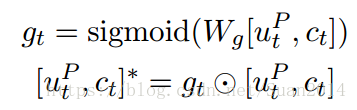
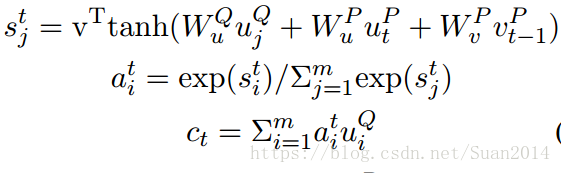
注括号内为[u_t_(P),c_t]*
V_t_(P)为新生产的段落中words的表达,请参看Figure1进行理解,门是基于当前段落word及其 attention-pooling vector of the question,其侧重于问题与当前段落word之间的关系。 门有效地模拟了阅读理解中只有部分word是和问题相关的。
3.自匹配注意力(self-Matching Attention)
通过上述操作,已经编码出了段落中的哪部分是重要的,但是这样的编码还存在的问题是:这部分重要段落缺乏上下文信息,因此这部分就是解决该问题的。该部分编码出的段落表达(请参看Figure1):
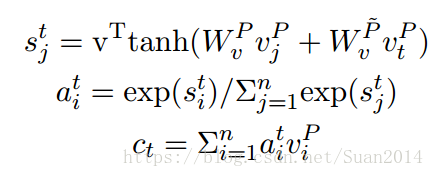
4.输出层
采用pointer network来预测答案的开始和结束位置,利用注意力机制作为选择起始位置()和结束位置(
):
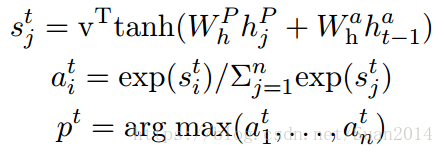
其中为pointer network的最后一个隐含层状态,pointer network的输入为基于当前预测概率
的attention-pooling vector:
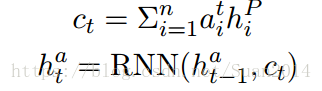
采用问题向量作为attention-pooling vector:
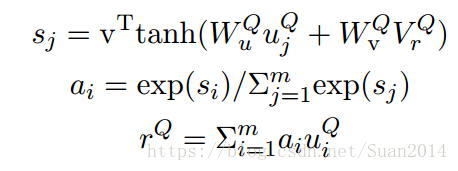
训练时,最小化真实start和end位置的负log概率之和。
实验
文章的实验做得比较充分,这里补充一些实现细节:out-of-vocab的word是用零向量表示的;采用1层双向GRU来计算character-level embeddings,3层双向RGU编码问题和段落,所有层中隐含层向量长度都设置为75,层间dropout 率为0.2,优化方法AdaDelta,初始学习率为1,和
分别为0.95和1e-6。
1.和其他算法的对比实验
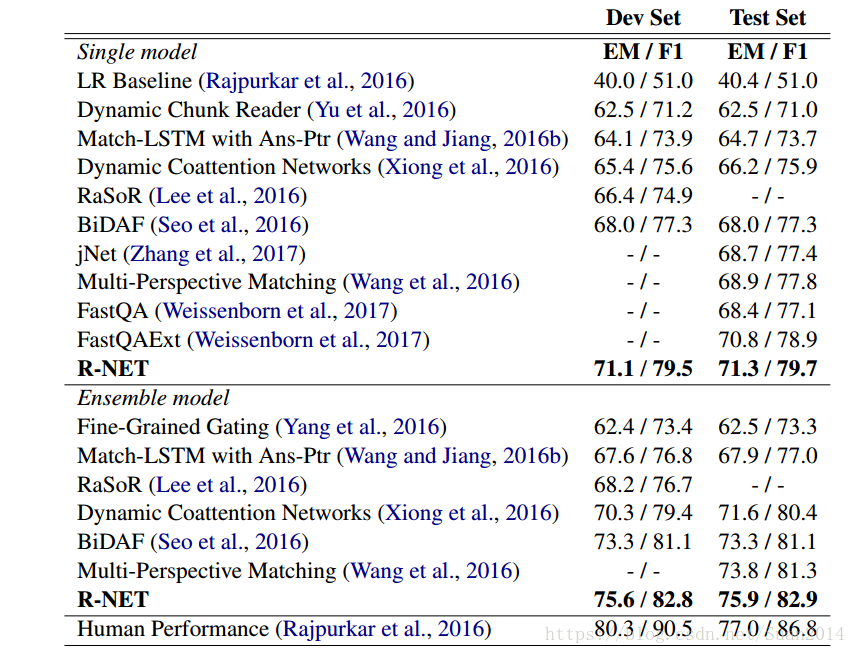
R-NET代表本文算法
2.每个部分的重要性
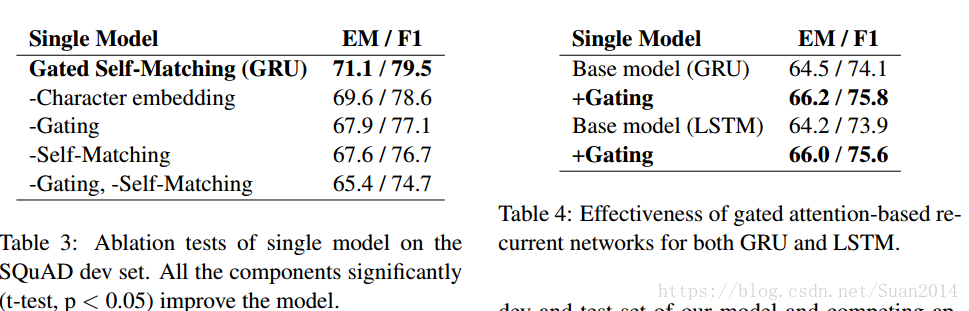
-代表去除,+代表添加,上述两个表格可以反映出本文各个部分的重要作用
3.统计发现
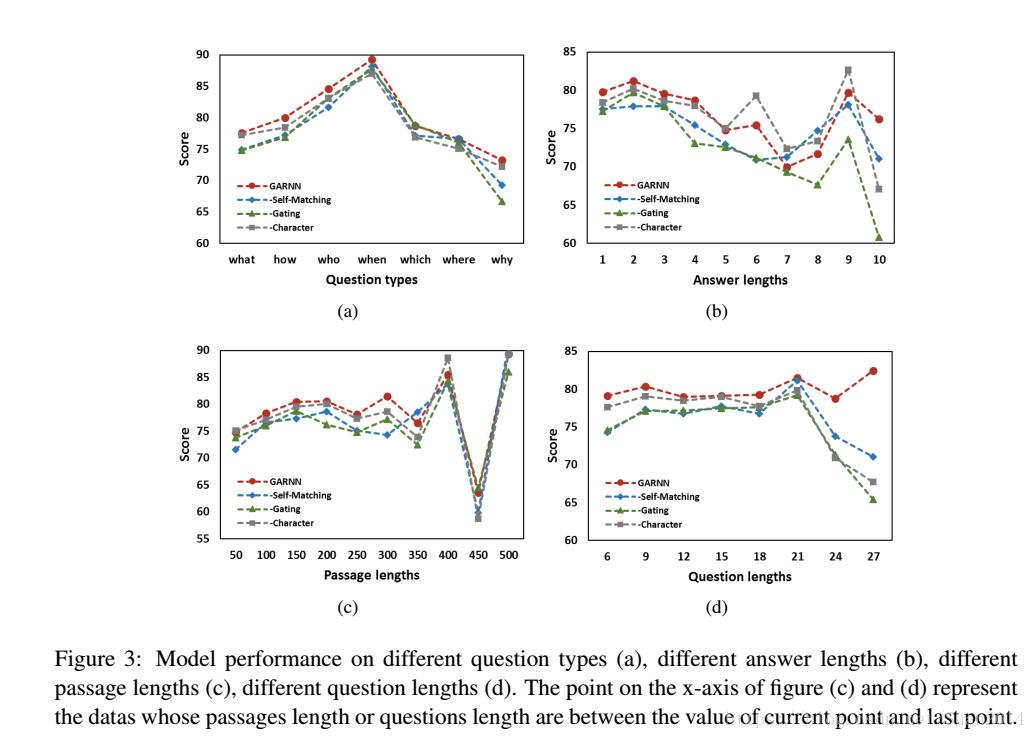
(a)可以看出问题类型为when和who时,表现较好,当为why时表现很差,这主要是因为why问题的答案是多样的;(b)可以看出,当答案很长时,表现很差,这说明答案越长越难预测;(c)和(d)可以看出整体相对稳定,当段落和问题很长时,可能表现较差,这是因为其中的有用信息所占比例较短。
这篇关于Gated Self-Matching Networks for Reading Comprehension and Question Answering论文笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






