self专题
![[LeetCode] 238. Product of Array Except Self](/front/images/it_default.jpg)
[LeetCode] 238. Product of Array Except Self
题:https://leetcode.com/problems/product-of-array-except-self/description/ 题目 Given an array nums of n integers where n > 1, return an array output such that output[i] is equal to the product of all

【Live Archive】6393 Self-Assembly【强连通】
传送门:【Live Archive】6393 Self-Assembly 题目分析: 假设我们只用到向上或者向右的块,这样我们只要找到一个回路使得某个块可以和第一个块一样,那么我们就相当于找到了一个循环,这样就可以无限循环了。 但是我们要怎样去找这么一个环?考虑到必须是对应字母 X+,X− X^+,X^-才能建边,然后一个环中一定是多个一对一对的这样的对应字母组成的。 可以发现块的数量那么
【网络安全】Self XSS + 文件上传CSRF
未经许可,不得转载。 文章目录 正文发现反射点实现XSS跨站请求伪造 (CSRF) 与文件上传结合POC 正文 在目标网站 target.com 的“联系我们”表单中,我注意到一个文件上传选项。 我最初输入了一个随机字符串,如 123xss,结果发现服务器没有对这个字符串进行足够的处理,比如转义或过滤,而是将其直接反射到网页中并展示给用户。 于是,我尝试注入XSS

在Yolov8中model.export后self.export=false问题(记录)
遇到一个问题是自己创建了新的Detect检测头,但是在导出模型时,想要修改输出格式,在yolo中可以通过if self.export:来修改网络的返回值格式 当使用model.export()导出时,理论上会自动将export设置为True 但是在实际中发现export=false,于是通过调试发现在ultralytics/engine/exporter.py中 for m in model
Self-study Python Fish-C Note20 P64to65
类和对象 (part 3) 本节主要介绍 类和对象的多态和鸭子类型、私有变量和 __slots__(原视频P64-65)\ 多态 多态是面向对象编程的三大特征之一,另外两个是封装和继承。多态是指同一个运算符、函数或对象,在不同场景下具有不同作用效果的情况。 Python 是一门动态语言,多态本来就是 Python的一种特性。 比如: 加号:两边都是数字的时候就是执行算术运算(相加),如果两边
详解PyTorch中的`remove_self_loops`函数及其在图神经网络中的应用
remove_self_loops 引言什么是自环?`remove_self_loops`函数简介函数的基本用法为什么要移除自环?`remove_self_loops`的实际应用 引言 在图神经网络(GNN)的研究与应用中,数据预处理是实现高效和精确模型的关键步骤之一。remove_self_loops函数在这一过程中扮演了重要角色。本文将深入探讨这一函数的定义、作用以及在

【王树森】RNN模型与NLP应用(9/9):Self-Attention(个人向笔记)
前言 上节课讲到的attention用到了Seq2Seq模型上,而Attention并不局限与Seq2Seq模型,而是可以用在所有RNN模型上。Self-attention在原论文中用到了LSTM上,而本节课做了简单的替换:换成了 Simple RNN。 SimpleRNN + Self-Attention 下面的 h 0 h_0 h0 为初始状态,是一个全0向量 无 Self-A

Self-Attention Generative Adversarial Networks解读+部分代码
Self-Attention Generative Adversarial Networks解读+部分代码 引言 这篇是文章是Ian goodfellow他们的新工作,在GAN中引入Attention。 在文章的摘要中作者主要突出了三点。 Self-Attention Generative Adversarial Network(SAGAN)是一个注意力驱动,长范围 关联模型(a
Js中window.parent ,window.top,window.self详解
在应用有frameset或者iframe的页面时,parent是父窗口,top是最顶级父窗口(有的窗口中套了好几层frameset或者iframe),self是当前窗口, opener是用open方法打开当前窗口的那个窗口。 window.self 功能:是对当前窗口自身的引用。它和window属性是等价的。 语法:window.self 注:window、self、windo
![[SimCLR v2] Big Self-Supervised Models are Strong Semi-Supervised Learners](https://i-blog.csdnimg.cn/direct/4cc9701420354cecb5eba7197a705453.png)
[SimCLR v2] Big Self-Supervised Models are Strong Semi-Supervised Learners
1、目的 借助无监督预训练来提升半监督学习的效果 2、方法 1)unsupervised/self-supervised pretrain -> task-agnostic -> big (deep and wide) neural network可以有效提升准确性
python中的类中属性元素加self.和不加self.的区
如果不加self,表示是类的一个属性(可以通过“类名.变量名”的方式引用),加了表示是类的实例的一个属性(可以通过“实例名.变量名”的方式引用)。 比如: In [17]: class Test(object): ....: val = 1 ....: ....: def __init__(self): ....:
使用GitHub Actions的Self-hosted runner
登录github网站选择项目点击Settings按钮,进入设置页面点击actions/runners进入Runners页面点击New self-hosted runner按钮进入新增页面选择相应配置,生成相应的命令,在内网机器上运行 下载: # Create a folder$ mkdir actions-runner && cd actions-runner# Download the l
python __setitem__(self)和__getitem__(self)
Python中除了可以使用内建的类型,如list,tuple,dict,还可以创建自己的对象来实现像这些内建类型的访问,不过需要在定义类的时候对一些魔法方法逐一实现。 如下: [python] view plain copy print ? class DictDemo: def __init__(self,key,value):
python __len__(self)详解
__len__如果一个类表现得像一个list,要获取有多少个元素,就得用 len() 函数。要让 len() 函数工作正常,类必须提供一个特殊方法__len__(),它返回元素的个数。例如,我们写一个 Students 类,把名字传进去:class Students(object):def __init__(self, *args):self.names = argsdef __len__(se

一文彻底搞懂Transformer - Why Self-Attention(为什么是自注意力)
Transformer 使用自注意力(Self-Attention)机制在序列处理任务中,特别是自然语言处理(NLP)领域,变得越来越流行,主要是因为它在计算复杂度、并行化能力、长距离依赖的建模能力 等多个关键方面相较于传统的循环神经网络(RNNs)和卷积神经网络(CNNs)具有显著的优势。 一、计算复杂度 计算复杂度: 自注意力机制尽管计算复杂度为O(n^2),但通过高度优化的矩阵运算库
Transformer系列-6丨LRNet和Stand-Alone Self-Attention网络解析
0. 前言 本次主要分享之前看的两篇将自注意力机制self-attention应用在视觉感知任务的文章,分别为LRNet和Stand-alone self-attention。为了深化读者的理解,本文提供了较为详细的中文注释的代码。 首先了解一下这两篇文章的背景,其都是在Vision Transformer(ViT)提出之前将transformer应用在感知任务上的尝试。尽管这些方法没有取得像

LLM agentic模式之reflection:SELF-REFINE、Reflexion、CRITIC
SELF-REFINE SELF-REFINE出自2023年3月的论文《Self-Refine: Iterative Refinement with Self-Feedback》,考虑到LLM第一次生成结果可能不是最好的输出,提出一种包括反馈(feedback)和改善(refinement)两个步骤的迭代方法来改进LLM的初始输出。 基本思路 对于输入,SELF-REFINE让LLM生成一个

【Deep Learning】Self-Supervised Learning:自监督学习
自监督学习 本文基于清华大学《深度学习》第12节《Beyond Supervised Learning》的内容撰写,既是课堂笔记,亦是作者的一些理解。 在深度学习领域,传统的监督学习(Supervised Learning)的形式是给你输入 x x x和标签 y y y,你需要训练一个基于参数 θ \theta θ的神经网络 f θ ( x ) f_\theta(x) fθ(x)使其能

MCT Self-Refine:创新集成蒙特卡洛树搜索 (MCTS)提高复杂数学推理任务的性能,超GPT4,使用 LLaMa-3 8B 进行自我优化
📜 文献卡 题目: Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B作者: Di Zhang; Xiaoshui Huang; Dongzhan Zhou; Yuqiang Li; Wanli OuyangDOI: 10.48550/a
CVPR2023论文速览自监督Self-Supervised相关38篇
Paper1 Self-Supervised Video Forensics by Audio-Visual Anomaly Detection 摘要原文: Manipulated videos often contain subtle inconsistencies between their visual and audio signals. We propose a video foren
oc学习笔记1——self,super
self: self和java中的this,比较类似,但oc中的self比java中的this要强大。 1.self在对象方法(以-(减号)开头的方法)中,表示当前的实例对象。 2.self在类方法(以+(加号)开头的方法中),表示当前类 super: 调用当前方法的父类方法(类方法或对象方法), 使用的场景:子类只是想覆盖父类中的某个方法,并且只是对父类方法的拓展,在父类

Advanced RAG 08:使用 Self-RAG 打造高质量、可追溯的 RAG System
编者按: RAG 技术通过检索并利用外部知识源,能够较为有效地提升生成内容的准确性和多样性。然而,经典 RAG 流程也存在一些不足,例如不必要的检索会浪费计算资源,并可能引入无关内容或错误信息,影响生成质量。 本文介绍了 Self-RAG 这一技术,通过引入 Reflection Tokens,语言模型能够根据具体需求动态决定是否检索外部知识,从而大大减少了不必要的检索操作。与此同时,Self-

Transformer中的Self-Attention和Multi-Head Attention
2017 Google 在Computation and Language发表 当时主要针对于自然语言处理(之前的RNN模型记忆长度有限且无法并行化,只有计算完ti时刻后的数据才能计算ti+1时刻的数据,但Transformer都可以做到) 文章提出Self-Attention概念,在此基础上提出Multi-Head Atterntion 下面借鉴霹雳吧啦博主的视频进行学习: Se
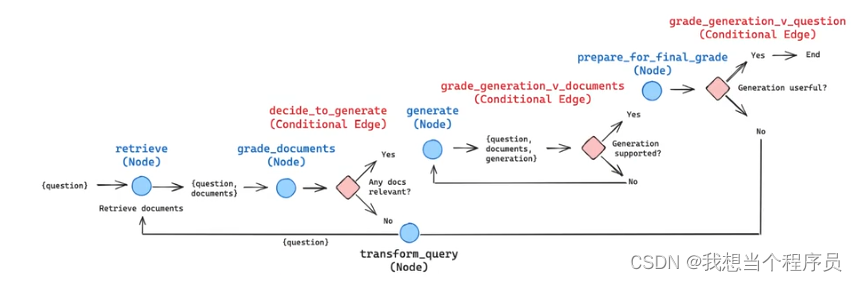
【AI开发】CRAG、Self-RAG、Adaptive-RAG
先放一张基础RAG的流程图 https://blog.langchain.dev/agentic-rag-with-langgraph/ 再放一个CRAG和self-RAG的LangChain官方博客 Corrective RAG(CRAG) 首先需要知道的是CRAG的特色发生在retrieval阶段的最后开始,即当我们获得到了近似的document(或者说relevant snippet
Self Dividing Numbers问题及解法
问题描述: A self-dividing number is a number that is divisible by every digit it contains. For example, 128 is a self-dividing number because 128 % 1 == 0, 128 % 2 == 0, and 128 % 8 == 0. Also, a
SGU 108. Self-numbers 2 离线+位优化
可以像筛选法那样标记 但是内存最多只能开1024的int数组 我用了位优化 用一个int 32 位标记32个数字 接下来就离线 排个序 算出第k大的哪个数 #include <cstdio>#include <cstring>#include <algorithm>using namespace std;int a[10000000/32];struct node{int x, y,