本文主要是介绍【AI开发】CRAG、Self-RAG、Adaptive-RAG,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
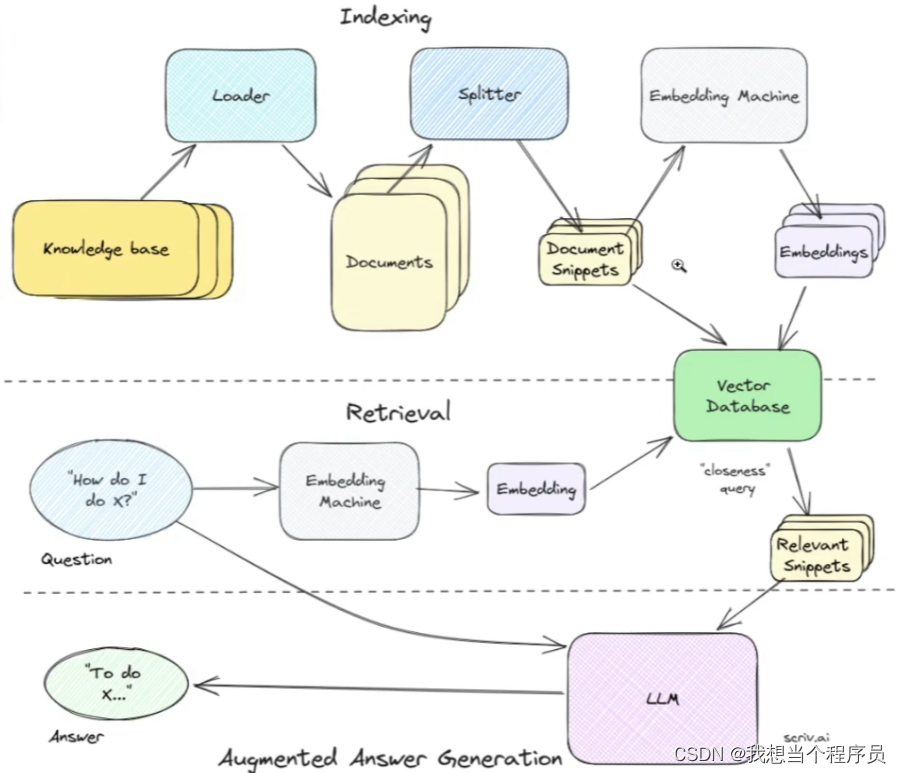
先放一张基础RAG的流程图
https://blog.langchain.dev/agentic-rag-with-langgraph/
再放一个CRAG和self-RAG的LangChain官方博客
Corrective RAG(CRAG)
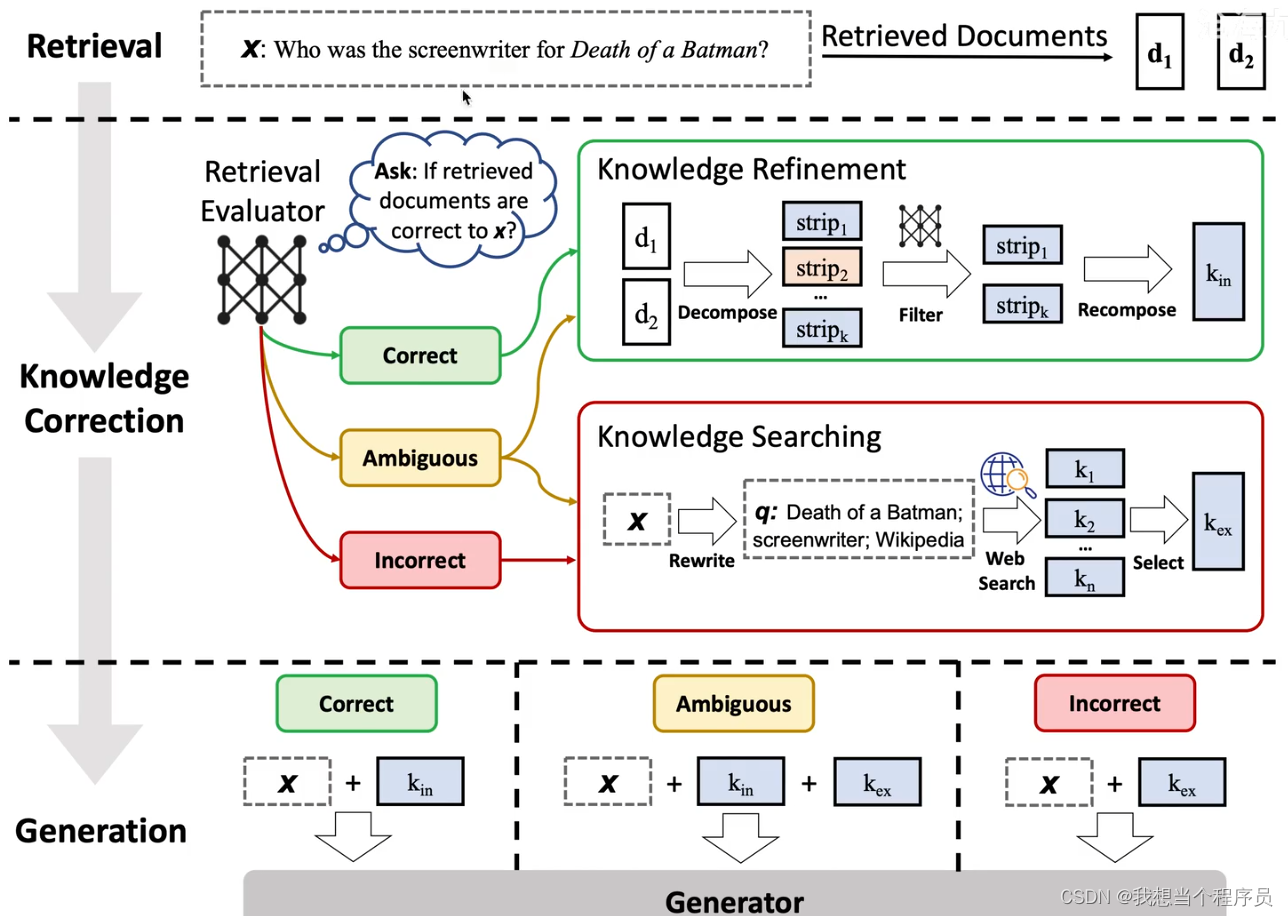
首先需要知道的是CRAG的特色发生在retrieval阶段的最后开始,即当我们获得到了近似的document(或者说relevant snippets)之后。
然后我们会进入一个额外的环节,叫Knowledge Correction。在这里呢我们会先对retrieval得到的每一个相关切片snippets进行evaluate,评估一下我们获取到的snippet是不是对问的问题有效?(此处重点:evaluator也是一个LLM)
然后会有三种情况:
- Correct:那就直接进行RAG的正常流程。(不过图中是加了进一步的优化)
- Incorrect:那就直接丢弃掉原来的document,直接去web里搜索相关信息
- Ambiguous:对于模糊不清的,就两种方式都要
那么在最后的generation部分,也是根据三种不同的情况分别做处理。
- 之前是correct,那现在就直接拼接问题和相关文档
- 之前是incorrect,那现在就直接拼接问题和web获取的信息
- 之前是ambiguous,那现在就拼接三个加起来
以上是CRAG的原始大概逻辑,但在langchain中对此进行了简化:
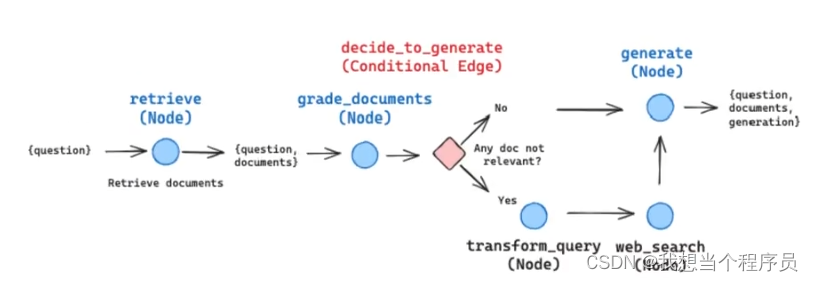
在Langchain中只存在两种情况,即当incorrect的时候,直接就去web上search了(先经过一个transform_query对问题进行重写,变成更适合web搜索的形式)
Self-RAG
和CRAG的核心都是self-reflective,即当我发现结果不是那么有效时,我要通过环回溯到之前的步骤去优化。
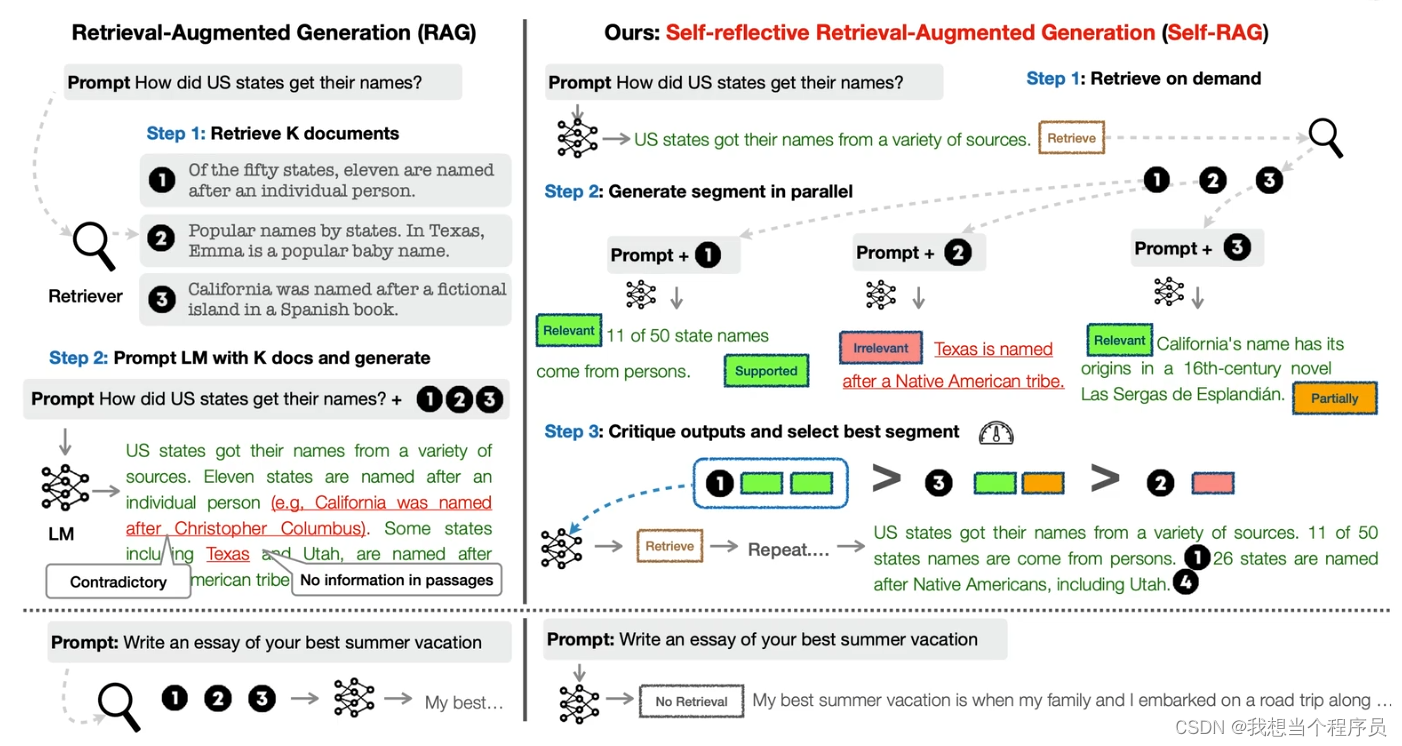
和CRAG不一样的是,selfRAG的流程是从最开始进行的,大概流程:
- 先判断问题是不是需要retrieval,如上图右下角,此处的问题是写一篇essay,那其实根本没必要去retrieval,直接放入LLM就行
- 当问题需要检索的时候,我们会将得到的每个document snippet分别判断
①是否有关relevant:
如果无关,那就不进行第②步。
如果有关:
②如果有关,那是否支持support,或者部分支持partial support,或者不支持 - 当我们对所有snippets都判断后,按照相关性进行排序,然后依次送到LLM中去进行最后的步骤。
- 在最后生成后还有一次评估,总共三次。
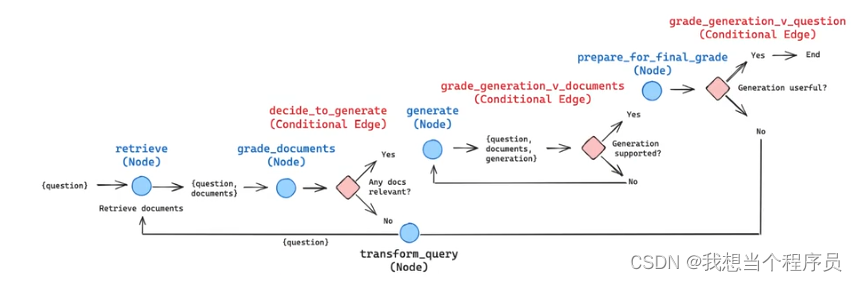
这是用LangChain(LangGraph)做self-RAG的流程图,如果能自己动手画出来这个图,知道什么时候是哪个节点,什么时候是哪种边,就说明真正学会了。
推荐个b站up:沧海九粟
我的很多文章都是看他的视频做的
Adaptive RAG
这个我就不写了,有篇博客写的很好
https://blog.csdn.net/qq_45668004/article/details/138199143
总结一下就是:self-RAG里面的令牌大多都是关于判断得到的某个东西合不合要求,从而进行不一样的action。而Adaptive里面的令牌相当于一个分类器,把问题分类成几种类型,每种类型对应不同复杂程度的RAG模型
这篇关于【AI开发】CRAG、Self-RAG、Adaptive-RAG的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








