rag专题

我的第2个AI项目-RAG with Gemma hosted on HuggingFace and Weaviate in DSPy
目录 项目简介概述时间kaggle地址主要工作和收获技术栈数据集模型表现 未来项目说明思路和原则为什么不把现在的项目做深一点?博客风格转变 bug修复版本兼容问题 项目简介 概述 本项目简要介绍了如何使用 DSPy 构建一个简单的 RAG 管道,且利用了托管在 Hugging Face 上的 Gemma LLM模型 和 Weaviate 向量数据库。 时间 2024.09

jmeter压力测试,通过LLM利用RAG实现知识库问答,NEO4J部署,GraphRAG以知识图谱在查询时增强提示实现更准确的知识库问答(9/7)
前言 这周也是杂七杂八的一天(高情商:我是一块砖,哪里需要往哪里搬),首先是接触了jemter这个压力测试工具,然后帮公司的AIGC项目编写使用手册和问答手册的第一版,并通过这个平台的智能体实现知识库问答的功能展示,以及部分个人扩展和思考(NEO4J创建知识图谱的GraphRAG)。 Jmeter Jmeter是一个压力测试工具,一开始导师叫我熟悉的时候我还说

深入RAG优化:BGE词嵌入全解析与Landmark Embedding新突破
前面已经写过一篇关于Embedding选型的文章,《如何高效选择RAG的中文Embedding模型?揭秘最佳实践与关键标准!》,主要介绍通过开源网站的下载量和测评效果选择Embedding模型。 一、Embedding选型建议与结果 选型建议: 1、大部分模型的序列长度是 512 tokens。8192 可尝试 tao-8k,1024 可尝试 stella。 2、在专业数据领域上,嵌入

langchain 《斗破苍穹》智谱 RAG 问题搜索
目录 代码 项目介绍 模型对比实验 分块方法对比 检索方法对比 结果 10条问题 15条问题 局限性 代码 https://github.com/5zjk5/prompt-engineering/tree/master 项目介绍 《斗破苍穹》小说 RAG 问答,爬虫爬取整部小说章节,并分别保存到不同的数据源中。 txt,pdf,markdown,word。

提升LLM结果:何时使用知识图谱RAG
通过知识图谱增强 RAG 可以帮助检索,使系统能够更深入地挖掘数据集以提供详细的响应。 有时,检索增强生成 (RAG) 系统无法深入文档集以找到所需的答案。我们可能会得到泛泛的或肤浅的回复,或者我们可能会得到回复,其中 RAG 系统检索到的细节很少,然后用不相关或不正确的信息填补空白——这被称为“幻觉”。 深度知识库和文档集可能包含我们用 RAG 提示回答问题所需的所有信息,但 RAG 系统

使用Cloudflare构建RAG应用;端到端语音开源大模型;AI幻灯片生成器,等六个开源项目
✨ 1: Cloudflare RAG 如何使用Cloudflare构建一个完整的RAG应用,结合多种搜索技术和AI服务。 Cloudflare RAG(Retrieval Augmented Generation)是一个全栈示例,展示如何使用 Cloudflare 构建 RAG 应用程序。该项目结合了 Cloudflare Workers、Pages、D1、KV、R2、AI Gate

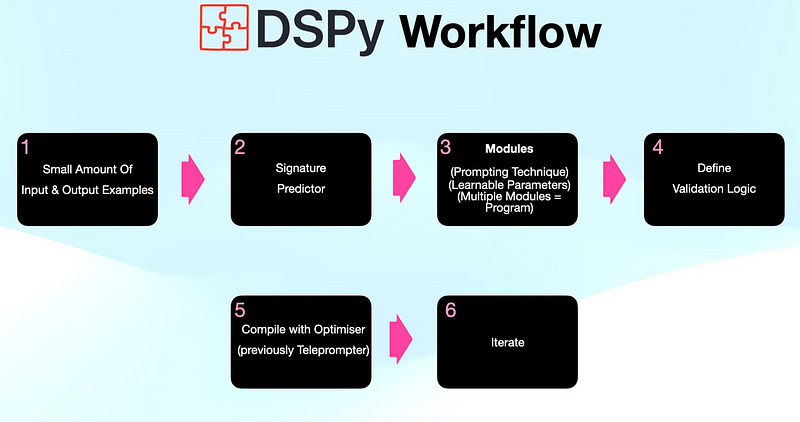
LlamaIndex结合DSPy,进一步优化RAG系统
大家好,本文将介绍如何运用LlamaIndex和DSPy这两个工具来构建和优化检索增强型生成(Retrieval-Augmented Generation, RAG)系统。通过这两个框架的无缝结合,不仅能够简化开发过程,还能显著提高RAG系统的整体性能。接下来,将详细解析LlamaIndex与DSPy如何高效协同,带来1+1>2的效果。 1.LlamaIndex LlamaIndex 是用于构

增强RAG:选择最佳的嵌入和重排模型
对于如何选择最佳的嵌入模型和重排模型,给出了详细的步骤和代码。 在构建检索增强生成(RAG)管道时,关键组件之一是检索器。我们有多种嵌入模型可供选择,包括 OpenAI、CohereAI 和开源的sentence transformers。此外,还有来自 CohereAI 和sentence transformers的几种重排器可供选择。 但是,在所有这些选项中,我们如何确定最佳组合以获得顶级

企业级RAG应用优化整合贴【上】:数据索引阶段的8个必知技巧 |建议收藏
基于大模型的RAG应用,一个普遍的认识是: 做原型很简单,投入生产很难 为什么我的RAG应用很难按预期工作?在之前的文章中我们曾经陆续的对RAG应用优化做过零星与局部的探讨,如融合检索、查询转换、多模态处理、Agentic RAG等。接下来我们将结合之前的方法与实践,总结形成更完整的企业级RAG应用的优化建议以供参考。 本篇将首先专注在RAG应用的索引阶段: 让数据更容易被拆分成可理解的

Ollama拉起本地模型以及rag系统部署。
什么是 Ollama ? Ollama 是一个简明易用的本地大模型运行框架。能在本地启动并运行 Llama、qwen、Gemma 及其他大语言模型,没有GPU资源照样可以拉起模型,和LocalAI 比较类似,但是加载模型更容易。 1.安装 安装后运行,执行:http://127.0.0.1:11434/,返回:Ollama is running表示成功 2.拉取模型: 3.运行模型

RAG 进阶:零成本 chat_with_readthedocs
Readthedocs 是知名的文档托管平台,通常用于免费存放 GitHub 和 GitLab 的项目文档。当项目文档较多时,简单的搜索难以满足读者需求,此外在 AI 2.0 时代,“主动寻找答案”这类用户体验已经逐渐落后。 本文将介绍如何基于 HuixiangDou 在 readthedocs 中做源码检索,同时不需要自备 GPU 服务器和域名。 HuixiangDou ——开源的适合群聊


9行代码开发一个基于ollama的私有化RAG
前言 OpenAI(LLM + Embedding)是使用LiteLLM + ollama模拟,具体做法如下, Llamaindex OpenAI LLM 模型默认使用的是gpt-3.5-turbo, embedding 模型默认使用的是text-embedding-ada-002, 所以这里使用litellm 配合config来模拟, 一句话介绍LiteLLM 使用OpenAI格式调用所

有手就会之使用Dify构建RAG聊天应用(基于私有知识库和搜索引擎)
之前我的文章里写的是通过langchain来构建RAG应用,对于很多人来说。langchain作为一个框架上手难度大,代码不够直观。但是通过dify你将学会可视化搭建工作流。 什么是dify? Dify 是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技
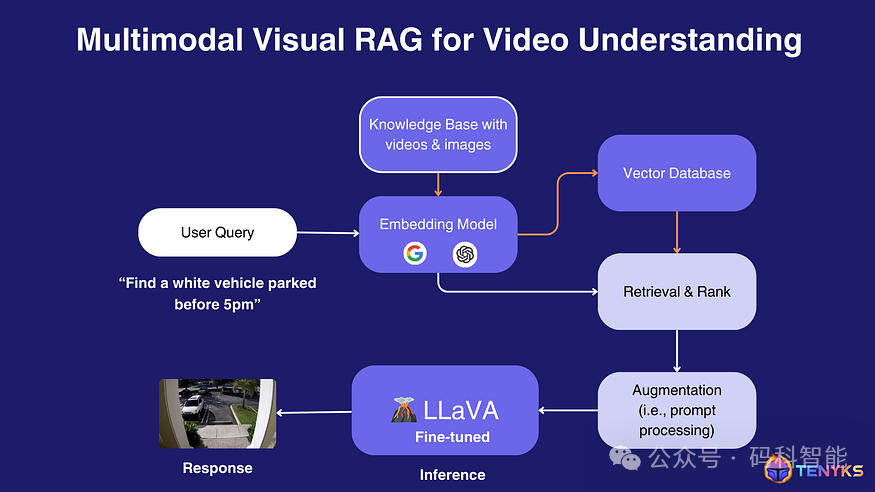
自然语言处理:第四十三章 视觉RAG:变革传统深度学习模型开发流程,开创下一代多模态视觉模型的新时代
文章链接:微信公众平台 (qq.com) 写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!! 写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!! 写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!! 我们相信视觉领域即将发生范式转变,从而产生计算机视觉管道 2.0,其中一些传统阶段(例如标记)将被可提示的基础模型所取代。 本文深入剖析了Vis

提示工程 vs 微调 vs RAG
原文地址:https://medium.com/@myscale/prompt-engineering-vs-finetuning-vs-rag-cfae761c6d06 本文由我的文章翻译智能体 、文章润色智能体、文章概括智能体和我合作整理完成 摘要: 提示工程、微调和检索增强生成(RAG)是三种主要优化大型语言模型输出的方法。提示工程简单易用,适合一般性话题,但定制性有限。微调则提

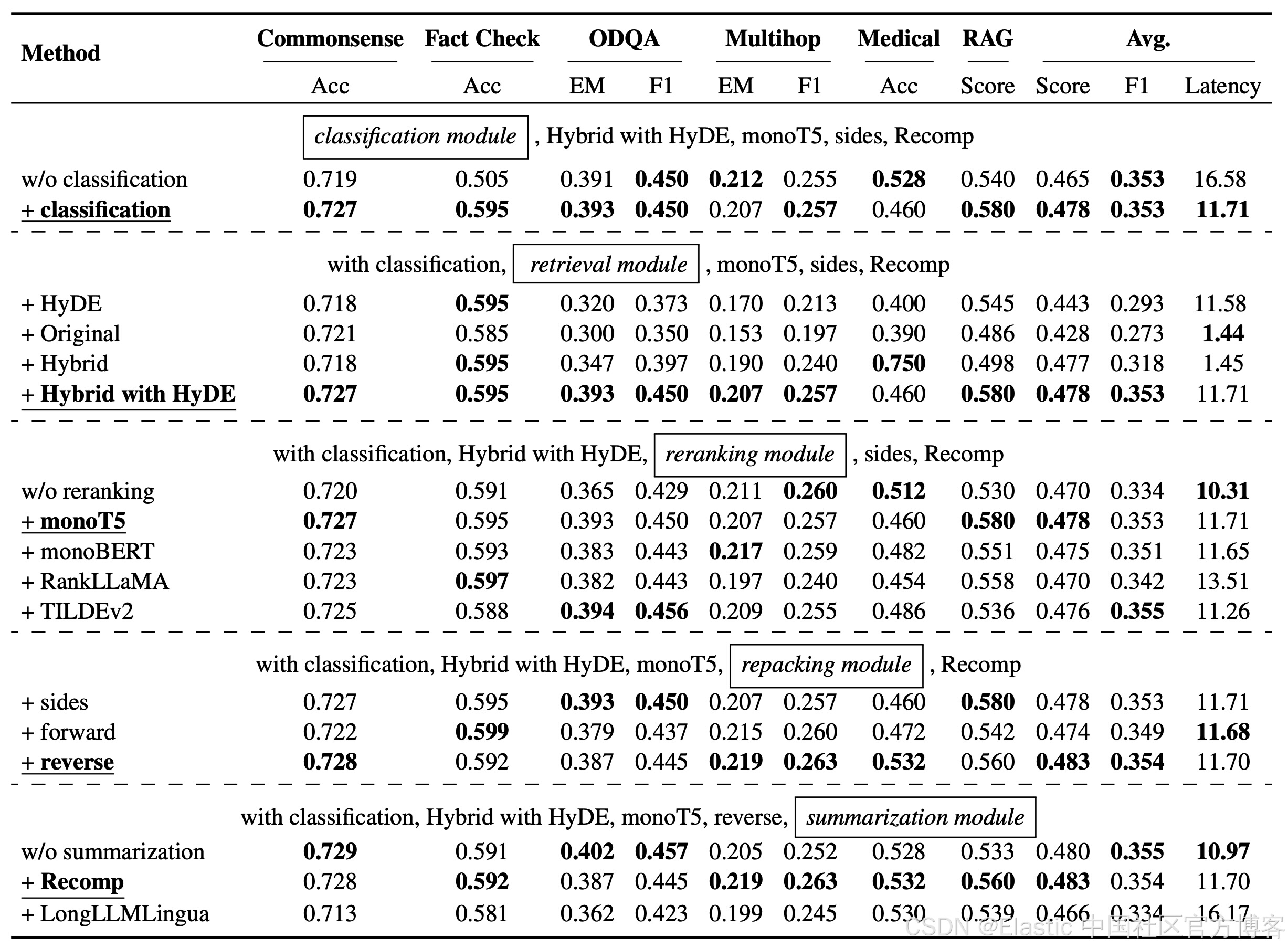
Elasticsearch 高级 RAG 技术第 2 部分:查询和测试
作者:来自 Elastic Han Xiang Choong 作者使用的 RAG 管道。 所有代码均可在 Searchlabs repo 的 advanced-rag-techniques 分支中找到。 欢迎阅读我们关于高级 RAG 技术的文章第 2 部分!在本系列的第 1 部分中,我们设置、讨论和实现了高级 RAG 管道的数据处理组件(如上所示)。 在这一部分,我们将继

一文彻底搞懂大模型 - RAG(检索、增强、生成)
最近这一两周看到不少互联网公司都已经开始秋招提前批面试了。 不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。 最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。 《大模型面试宝典》(2024版) 正式发布 喜欢本文记得收藏、关注、点赞。文末技术交流 RAG(Retrieval-Augment

Elasticsearch 高级 RAG 技术第 1 部分:数据处理
作者:来自 Elastic Han Xiang Choong 这是我们探索高级 RAG 技术的第 1 部分。单击此处查看第 2 部分! 最近的论文《寻找检索增强生成的最佳实践》通过实证评估了各种 RAG 增强技术的有效性,目的是汇集一套 RAG 的最佳实践。 王等人推荐的 RAG 流程。 我们将实施其中一些建议的最佳实践,即旨在提高搜索质量的实践(句子分块/sente

RAG噪声的设计及其对大模型问答的作用分析
有趣的大模型中RAG噪声的作用分析 大模型(LLMs)在多个任务上表现出色,但存在依赖过时知识、幻觉等问题。RAG作为一种提高LLM性能的方法,通过在推理过程中引入外部信息来缓解这些限制。 Figure 1 展示了一个来自 NoiserBench 的示例,它阐释了不同类型的 RAG 噪声对大型语言模型(LLM)的影响。这个示例通过一个具体的问题和答案的情境来说明有益噪声和有害噪声对模型性能的不

240831-Gradio之RAG文档对话工具Kotaemon的安装与配置
A. 用户界面 该项目既可以作为功能性 RAG UI,既可以用于对文档进行 QA 的最终用户,也可以用作想要构建自己的 RAG 管道的开发人员。对于最终用户:- 一个干净且简约的用户界面,用于基于RAG的QA。- 支持 LLM API 提供程序(OpenAI、AzureOpenAI、Cohere 等)和本地 LLMs(通过 ollama 和 llama-cpp-python)。- 简单

langchain结合searXNG实现基于搜索RAG
目录 一、背景 二、环境说明和安装 1.1 环境说明 2.2 环境安装 2.2.1 searXNG安装 代码实现 代码 结果输出 直接请求模型输出 编辑 参考 一、背景 大语言模型的出现带来了新的技术革新,但是大模型由于训练语料的原因,它的知识和当前实时热点存在时间差距,存在很严重的幻觉。而RAG检索增强生成能够解决这个问题,知识以prompt的

RAG最佳实践:用 ElasticSearch 打造AI搜索系统与RAG 应用全流程详解!
前面一篇文章《RAG 向量数据库:掌握 Elasticsearch 作为向量数据库的终极指南》中,介绍了使用ElasticSerach作为向量数据的安装和使用指南。 今天这篇文章将介绍如何使用 Elasticsearch 搭建AI搜索系统和RAG应用系统。 Elasticsearch 搭建 AI 搜索系统 在 Elasticsearch 中实现向量搜索涉及四个关键组件: **嵌入模型:*
TC-RAG: Turing-Complete RAG--图灵完备的检索增强
摘要: 在提升领域特定的大语言模型(LLMs)的方法中,检索增强生成(RAG)技术作为一种有前景的解决方案,可以缓解诸如幻觉、知识过时以及在高度专业化查询中专业知识有限等问题。然而,现有的RAG方法忽视了系统状态变量的引入,而系统状态变量对于确保自适应控制、检索停止和系统收敛至关重要。本文通过严格的理论证明,提出了图灵完备的RAG(TC-RAG)框架,通过引入图灵完备的系统来管理状态变量,从