本文主要是介绍一文彻底搞懂大模型 - RAG(检索、增强、生成),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近这一两周看到不少互联网公司都已经开始秋招提前批面试了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
- 《大模型面试宝典》(2024版) 正式发布
喜欢本文记得收藏、关注、点赞。文末技术交流
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种结合了信息检索技术与语言生成模型的人工智能技术。该技术通过从外部知识库中检索相关信息,并将其作为提示(Prompt)输入给大型语言模型(LLMs),以增强模型处理知识密集型任务的能力,如问答、文本摘要、内容生成等。
RAG模型由Facebook AI Research(FAIR)团队于2020年首次提出,并迅速成为大模型应用中的热门方案。

__一、__检索增强生成(RAG)
什么是RAG?RAG(Retrieval-Augmented Generation,检索增强生成),RAG是一种 AI 框架,它将传统信息检索系统(例如数据库)的优势与生成式大语言模型 (LLM) 的功能结合在一起。
LLM通过将这些额外的知识与自己的语言技能相结合,可以撰写更准确、更具时效性且更贴合具体需求的文字。
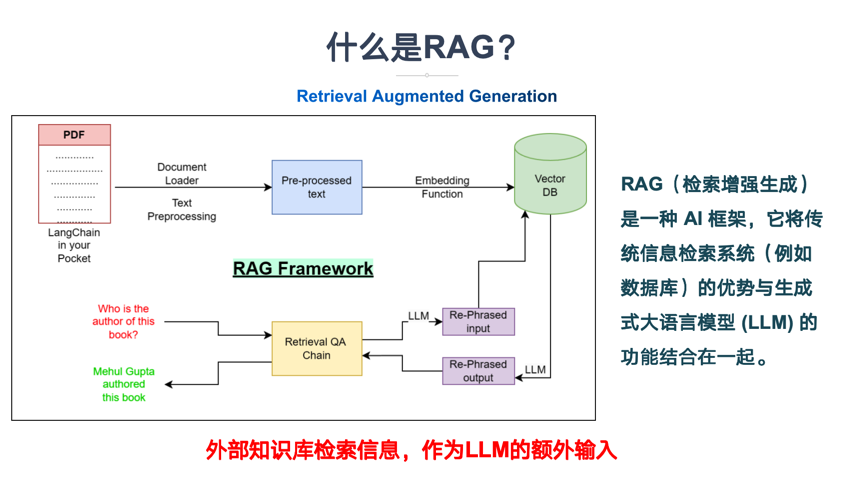
什么是RAG?
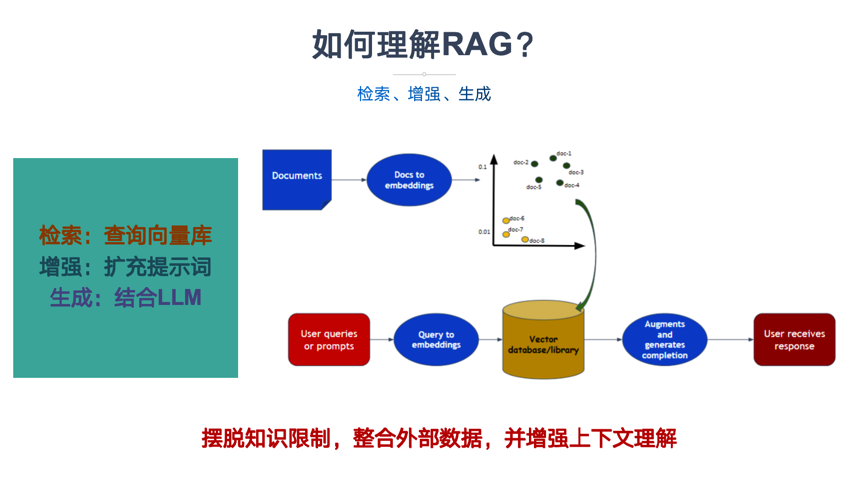
如何理解RAG?通过上一个问题,我们知道了什么是RAG?了解到RAG是一种结合了信息检索、文本增强和文本生成的自然语言处理(NLP)的技术。
RAG的目的是通过从外部知识库检索相关信息来辅助大语言模型生成更准确、更丰富的文本内容。那我们如何理解RAG的检索、增强和生成呢?
-
检索:检索是RAG流程的第一步,从预先建立的知识库中检索与问题相关的信息。这一步的目的是为后续的生成过程提供有用的上下文信息和知识支撑。
-
增强:RAG中增强是将检索到的信息用作生成模型(即大语言模型)的上下文输入,以增强模型对特定问题的理解和回答能力。这一步的目的是将外部知识融入生成过程中,使生成的文本内容更加丰富、准确和符合用户需求。通过增强步骤,LLM模型能够充分利用外部知识库中的信息。
-
生成:生成是RAG流程的最后一步。这一步的目的是结合LLM生成符合用户需求的回答。生成器会利用检索到的信息作为上下文输入,并结合大语言模型来生成文本内容。
RAG的“检索、增强、生成”,谁增强了谁,谁生成了答案,主语很重要。是从知识库中检索到的问答对,增强了LLM的提示词(prompt),LLM拿着增强后的Prompt生成了问题答案。
如何使用RAG?了解了什么是RGA,同步也理解了RAG的检索、增强和生成。那我们如何使用RAG呢?接下来以RAG搭建知识问答系统具体步骤为例,来讲解如何使用RAG?
- 数据准备与知识库构建:
-
收集数据:首先,需要收集与问答系统相关的各种数据,这些数据可以来自文档、网页、数据库等多种来源。
-
数据清洗:对收集到的数据进行清洗,去除噪声、重复项和无关信息,确保数据的质量和准确性。
-
知识库构建:将清洗后的数据构建成知识库。这通常包括将文本分割成较小的片段(chunks),使用文本嵌入模型(如GLM)将这些片段转换成向量,并将这些向量存储在向量数据库(如FAISS、Milvus等)中。
- 检索模块设计:
-
问题向量化:当用户输入查询问题时,使用相同的文本嵌入模型将问题转换成向量。
-
相似度检索:在向量数据库中检索与问题向量最相似的知识库片段(chunks)。这通常通过计算向量之间的相似度(如余弦相似度)来实现。
-
结果排序:根据相似度得分对检索到的结果进行排序,选择最相关的片段作为后续生成的输入。
- 生成模块设计:
-
上下文融合:将检索到的相关片段与原始问题合并,形成更丰富的上下文信息。
-
大语言模型生成:使用大语言模型(如GLM)基于上述上下文信息生成回答。大语言模型会学习如何根据检索到的信息来生成准确、有用的回答。
大家可以结合自己的业务领域知识,开始搭建医疗、法律、产品知识问答。先搭建Demo,然后工作中不断完善知识库问答对。

二、RAG的原理、流程及架构
RAG工作原理是什么?大型语言模型(LLM)面临两个问题,第一个问题是LLM会产生幻觉,第二个是LLM的知识中断。
-
知识截止:当 LLM 返回的信息与模型的训练数据相比过时时。每个基础模型都有知识截止,这意味着其知识仅限于训练时可用的数据。
-
幻觉:当模型自信地做出错误反应时,就会发生幻觉。
检索增强生成 (RAG) 摆脱了知识限制,整合了外部数据,从外部知识库中检索相关信息,增强模型的生成能力。
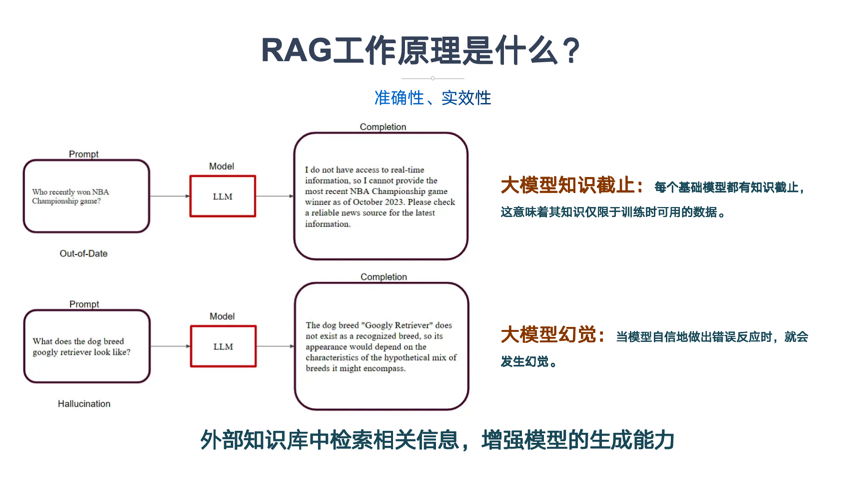
RAG工作流程是什么?通过检索增强技术,将用户查询与索引知识融合,利用大语言模型生成准确回答。
-
知识准备:收集并转换知识文档为文本数据,进行预处理和索引。
-
嵌入与索引:使用嵌入模型将文本转换为向量,并存储在向量数据库中。
-
查询检索:用户查询转换为向量,从数据库中检索相关知识。
-
提示增强:结合检索结果构建增强提示模版。
-
生成回答:大语言模型根据增强模版生成准确回答。
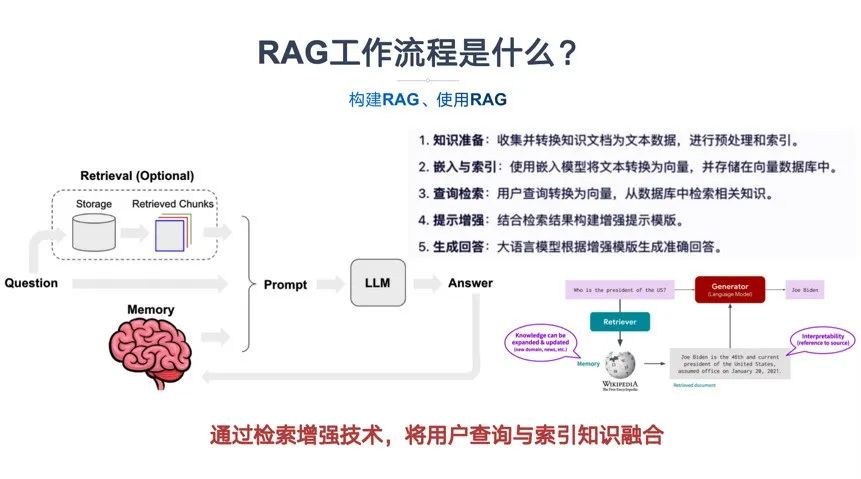
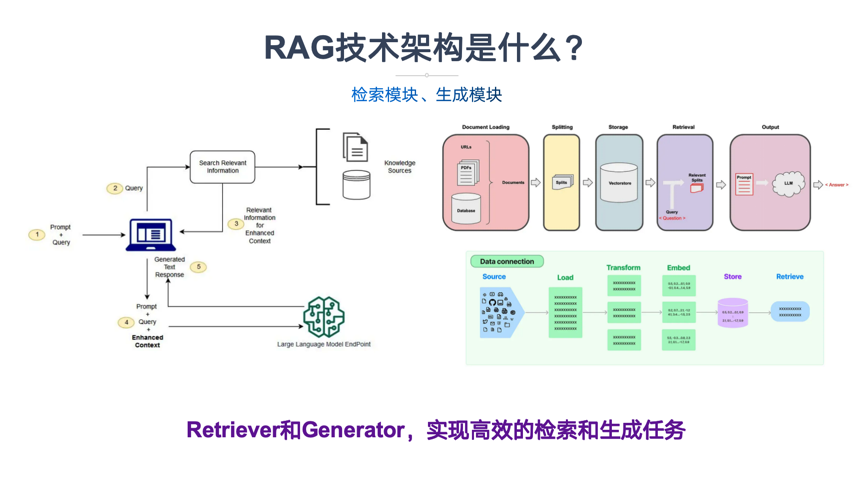
RAG技术架构是什么?RAG技术架构主要由两个核心模块组成,检索模块(Retriever)和生成模块(Generator)。
- 检索模块(Retriever):
-
文本嵌入:使用预训练的文本嵌入模型(如GLM)将查询和文档转换成向量表示,以便在向量空间中进行相似度计算。
-
向量搜索:利用高效的向量搜索技术(如FAISS、Milvus等向量数据库)在向量空间中检索与查询向量最相似的文档或段落。
-
双塔模型:检索模块常采用双塔模型(Dual-Encoder)进行高效的向量化检索。双塔模型由两个独立的编码器组成,一个用于编码查询,另一个用于编码文档。这两个编码器将查询和文档映射到相同的向量空间中,以便进行相似度计算。
- 生成模块(Generator):
-
强大的生成模型:生成模块通常使用在大规模数据上预训练的生成模型(如GLM),这些模型在生成自然语言文本方面表现出色。
-
上下文融合:生成模块将检索到的相关文档与原始查询合并,形成更丰富的上下文信息,作为生成模型的输入。
-
生成过程:生成模型根据输入的上下文信息,生成连贯、准确且信息丰富的回答或文本。
结合高效的检索模块(Retriever)与强大的生成模型(Generator),实现基于外部知识增强的自然语言生成能力。
技术交流

通俗易懂讲解大模型系列
-
重磅消息!《大模型面试宝典》(2024版) 正式发布!
-
重磅消息!《大模型实战宝典》(2024版) 正式发布!
-
做大模型也有1年多了,聊聊这段时间的感悟!
-
用通俗易懂的方式讲解:大模型算法工程师最全面试题汇总
-
用通俗易懂的方式讲解:不要再苦苦寻觅了!AI 大模型面试指南(含答案)的最全总结来了!
-
用通俗易懂的方式讲解:我的大模型岗位面试总结:共24家,9个offer
-
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
-
用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
-
用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
-
用通俗易懂的方式讲解:在 CPU 服务器上部署 ChatGLM3-6B 模型
-
用通俗易懂的方式讲解:ChatGLM3-6B 部署指南
-
用通俗易懂的方式讲解:使用 LangChain 封装自定义的 LLM,太棒了
-
用通俗易懂的方式讲解:基于 Langchain 和 ChatChat 部署本地知识库问答系统
-
用通俗易懂的方式讲解:Llama2 部署讲解及试用方式
-
用通俗易懂的方式讲解:一份保姆级的 Stable Diffusion 部署教程,开启你的炼丹之路
-
用通俗易懂的方式讲解:LlamaIndex 官方发布高清大图,纵览高级 RAG技术
-
用通俗易懂的方式讲解:为什么大模型 Advanced RAG 方法对于AI的未来至关重要?
-
用通俗易懂的方式讲解:基于 Langchain 框架,利用 MongoDB 矢量搜索实现大模型 RAG 高级检索方法
参考文献:
[1] https://betterprogramming.pub/fine-tuning-your-embedding-model-to-maximize-relevance-retrieval-in-rag-pipeline-2ea3fa231149
[2] https://github.com/weaviate/recipes/blob/main/integrations/llamaindex/retrieval-augmented-generation/naive_rag.ipynb
[3] https://medium.com/towards-data-science/retrieval-augmented-generation-rag-from-theory-to-langchain-implementation-4e9bd5f6a4f2
[4] https://github.com/run-llama/llama_index
[5] https://github.com/weaviate/recipes/blob/main/integrations/llamaindex/retrieval-augmented-generation/advanced_rag.ipynb
这篇关于一文彻底搞懂大模型 - RAG(检索、增强、生成)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








