本文主要是介绍增强RAG:选择最佳的嵌入和重排模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
对于如何选择最佳的嵌入模型和重排模型,给出了详细的步骤和代码。
在构建检索增强生成(RAG)管道时,关键组件之一是检索器。我们有多种嵌入模型可供选择,包括 OpenAI、CohereAI 和开源的sentence transformers。此外,还有来自 CohereAI 和sentence transformers的几种重排器可供选择。
但是,在所有这些选项中,我们如何确定最佳组合以获得顶级的检索性能?我们如何知道哪个嵌入模型最适合我们的数据?或者哪个重排器最能提升我们的结果?
在这篇博客文章中,我们将使用 LlamaIndex 的 检索评估 模块迅速确定嵌入模型和重排器模型的最佳组合。让我们开始吧!
让我们首先了解 检索评估 中可用的指标。
理解检索评估中的指标
为了衡量我们检索系统的效率,我们主要依赖于两个广泛接受的指标:命中率和平均倒数排名(MRR)。让我们深入这些指标,了解它们的重要性以及它们的工作原理。
命中率:
命中率计算在查询中正确答案出现在检索到的前k个文档中的比例。简单来说,它关乎我们的系统在前几个猜测中正确答案出现的频率。
平均倒数排名(MRR):
对于每个查询,MRR通过查看最相关文档的最高排名来评估系统的准确性。具体来说,它是所有查询中这些排名倒数的平均值。因此,如果第一个相关文档是顶部结果,倒数排名就是1;如果是第二个,倒数排名就是1/2,以此类推。
现在我们已经确定了范围并熟悉了这些指标,是时候深入实验了。为了获得实践经验,您也可以通过我们的Google Colab Notebook进行操作。
*设置环境*
!pip install llama-index sentence-transformers cohere anthropic voyageai protobuf pypdf
*设置Keys*
openai_api_key = 'YOUR OPENAI API KEY'
cohere_api_key = 'YOUR COHEREAI API KEY'
anthropic_api_key = 'YOUR ANTHROPIC API KEY'
openai.api_key = openai_api_key
*下载数据*
我们在此实验中使用Llama2论文,我们下载这篇论文。
documents = SimpleDirectoryReader(input_files=["llama2.pdf"]).load_data()node_parser = SimpleNodeParser.from_defaults(chunk_size=512)
nodes = node_parser.get_nodes_from_documents(documents)
*加载数据*
让我们加载数据。我们将使用第36页之前的内容进行实验,这排除了目录、参考文献和附录。
然后,这些数据被解析并转换为节点,这些节点代表我们想要检索的数据块。我们使用了512作为块大小。
documents = SimpleDirectoryReader(input_files=["llama2.pdf"]).load_data()node_parser = SimpleNodeParser.from_defaults(chunk_size=512)nodes = node_parser.get_nodes_from_documents(documents)
*生成问题-上下文对*
为了评估目的,我们创建了一个问答对数据集。这个数据集可以被看作是我们数据中的一组问题及其相应的上下文。为了在评估嵌入(OpenAI/CohereAI)和重排器(CohereAI)时消除偏见,我们使用Anthropic LLM生成问答对。
让我们初始化一个提示模板来生成问答对。
# Prompt to generate questions
qa_generate_prompt_tmpl = """\
Context information is below.---------------------
{context_str}
---------------------Given the context information and not prior knowledge.
generate only questions based on the below query.You are a Professor. Your task is to setup \
{num_questions_per_chunk} questions for an upcoming \
quiz/examination. The questions should be diverse in nature \
across the document. The questions should not contain options, not start with Q1/ Q2. \
Restrict the questions to the context information provided.\
"""
llm = Anthropic(api_key=anthropic_api_key)
qa_dataset = generate_question_context_pairs(nodes, llm=llm, num_questions_per_chunk=2
)
过滤掉类似这样的句子的函数— Here are 2 questions based on provided context
# function to clean the dataset
def filter_qa_dataset(qa_dataset):"""Filters out queries from the qa_dataset that contain certain phrases and the correspondingentries in the relevant_docs, and creates a new EmbeddingQAFinetuneDataset object withthe filtered data.:param qa_dataset: An object that has 'queries', 'corpus', and 'relevant_docs' attributes.:return: An EmbeddingQAFinetuneDataset object with the filtered queries, corpus and relevant_docs."""# Extract keys from queries and relevant_docs that need to be removedqueries_relevant_docs_keys_to_remove = {k for k, v in qa_dataset.queries.items()if 'Here are 2' in v or 'Here are two' in v}# Filter queries and relevant_docs using dictionary comprehensionsfiltered_queries = {k: v for k, v in qa_dataset.queries.items()if k not in queries_relevant_docs_keys_to_remove}filtered_relevant_docs = {k: v for k, v in qa_dataset.relevant_docs.items()if k not in queries_relevant_docs_keys_to_remove}# Create a new instance of EmbeddingQAFinetuneDataset with the filtered datareturn EmbeddingQAFinetuneDataset(queries=filtered_queries,corpus=qa_dataset.corpus,relevant_docs=filtered_relevant_docs)# filter out pairs with phrases `Here are 2 questions based on provided context`
qa_dataset = filter_qa_dataset(qa_dataset)
*自定义检索器*
为了确定最优的检索器,我们采用了嵌入模型和重排器的组合。最初,我们建立了一个基础的 VectorIndexRetriever。检索节点后,我们引入了重排器来进一步优化结果。值得注意的是,在这个特定的实验中,我们将 similarity_top_k 设置为10,并选择了重排器的前5个结果。然而,您可以根据您特定实验的需求自由调整此参数。我们在这里展示了使用 OpenAIEmbedding 的代码,请参考 notebook 中其他嵌入模型的代码。
embed_model = OpenAIEmbedding()
service_context = ServiceContext.from_defaults(llm=None, embed_model = embed_model)
vector_index = VectorStoreIndex(nodes, service_context=service_context)
vector_retriever = VectorIndexRetriever(index=vector_index, similarity_top_k = 10)
class CustomRetriever(BaseRetriever):"""Custom retriever that performs both Vector search and Knowledge Graph search"""def __init__(self,vector_retriever: VectorIndexRetriever,) -> None:"""Init params."""self._vector_retriever = vector_retrieverdef _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:"""Retrieve nodes given query."""retrieved_nodes = self._vector_retriever.retrieve(query_bundle)if reranker != 'None':retrieved_nodes = reranker.postprocess_nodes(retrieved_nodes, query_bundle)else:retrieved_nodes = retrieved_nodes[:5]return retrieved_nodesasync def _aretrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:"""Asynchronously retrieve nodes given query.Implemented by the user."""return self._retrieve(query_bundle)async def aretrieve(self, str_or_query_bundle: QueryType) -> List[NodeWithScore]:if isinstance(str_or_query_bundle, str):str_or_query_bundle = QueryBundle(str_or_query_bundle)return await self._aretrieve(str_or_query_bundle)custom_retriever = CustomRetriever(vector_retriever)
*评估*
为了评估我们的检索器,我们计算了平均倒数排名(MRR)和命中率这两个指标:
retriever_evaluator = RetrieverEvaluator.from_metric_names(["mrr", "hit_rate"], retriever=custom_retriever
)
eval_results = await retriever_evaluator.aevaluate_dataset(qa_dataset)
*结果*
我们将各种嵌入模型和重排器进行了测试。以下是我们考虑的模型:
嵌入模型:
- OpenAI Embedding
- Voyage Embedding
- CohereAI Embedding (v2.0/ v3.0)
- Jina Embeddings (small/ base)
- BAAI/bge-large-en
- Google PaLM Embedding
重排器::
- CohereAI
- bge-reranker-base
- bge-reranker-large
值得一提的是,这些结果为这个特定数据集和任务提供了深入的性能洞察。然而,实际结果可能会因数据特性、数据集大小以及其他变量(如chunk_size、similarity_top_k等)而有所不同。
下面的表格展示了基于命中率和平均倒数排名(MRR)指标的评估结果:
复制再试一次分享
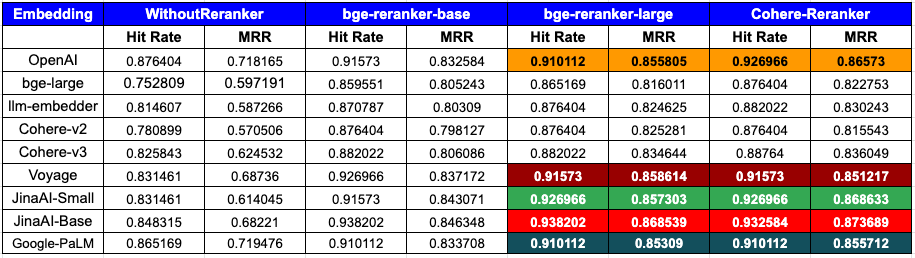
*分析:*
*按嵌入模型的性能:*
- OpenAI:展示了一流的性能,尤其是与
CohereRerank结合使用时(命中率0.926966,MRR 0.86573)和bge-reranker-large结合使用时(命中率0.910112,MRR 0.855805),表明与重排工具的兼容性很强。 - bge-large:在使用重排器时体验到显著的性能提升,最佳结果来自
CohereRerank(命中率0.876404,MRR 0.822753)。 - llm-embedder:从重排中获益匪浅,尤其是与
CohereRerank结合使用时(命中率0.882022,MRR 0.830243),这提供了显著的性能提升。 - Cohere:Cohere的最新v3.0嵌入性能优于v2.0,并且与原生
CohereRerank集成后,显著提高了其指标,拥有0.88764的命中率和0.836049的MRR。 - Voyage:具有强大的初始性能,通过
CohereRerank进一步增强(命中率0.91573,MRR 0.851217),表明对重排有很高的响应性。 - JinaAI:性能非常强,在使用
bge-reranker-large(命中率0.938202,MRR 0.868539)和CohereRerank(命中率0.932584,MRR 0.873689)时看到了显著的增益,表明重排显著提升了其性能。 - Google-PaLM:该模型展示了强大的性能,在使用
CohereRerank时有可衡量的增益(命中率0.910112,MRR 0.855712)。这表明重排为其整体结果提供了明确的提升。
*重排器的影响:*
- 无重排器:这为每种嵌入模型提供了基线性能。
- bge-reranker-base:普遍提高了所有嵌入模型的命中率和MRR。
- bge-reranker-large:这个重排器经常为嵌入模型提供最高或接近最高的MRR。对于几种嵌入,它的性能与
CohereRerank相媲美或超越了它。 - CohereRerank:在所有嵌入模型中一致性地增强了性能,通常提供了最佳或接近最佳的结果。
*重排器的必要性:*
- 数据清楚地表明了重排器在优化搜索结果中的重要性。几乎所有嵌入模型都从重排中受益,显示出提高的命中率和MRR值。
- 特别是
CohereRerank,重排器已经证明了它们将任何嵌入模型转变为具有竞争力的能力。
*总体优势:*
- 当考虑到命中率和MRR时,
penAI + CohereRerank和JinaAI-Base + bge-reranker-large/CohereRerank的组合作为顶级竞争者脱颖而出。 - 然而,
CohereRerank/bge-reranker-large重排器在不同嵌入模型中带来的持续改进使它们成为提升搜索质量的突出选择,无论使用哪种嵌入模型。
总结来说,为了在命中率和MRR上达到最佳性能,OpenAI 或 JinaAI-Base 嵌入与 CohereRerank/bge-reranker-large 重排器的组合显得尤为突出。
请注意,我们的基准测试旨在为你自己的数据提供一个可复现的脚本。尽管如此,请将这些数字视为估计值,并在解释它们时谨慎行事。
*结论:*
在这篇博客文章中,我们展示了如何使用不同的嵌入模型和重排器来评估和增强检索器的性能。以下是我们的最终结论。
- 嵌入模型:
OpenAI和JinaAI-Base嵌入模型,特别是与CohereRerank/bge-reranker-large重排器搭配使用时,为命中率和MRR设定了黄金标准。 - 重排器:重排器的影响,尤其是
CohereRerank/bge-reranker-large,怎么强调都不为过。它们在提高许多嵌入模型的MRR方面发挥了关键作用,显示了它们在使搜索结果更好的重要性。 - 基础是关键:选择适合初始搜索的正确嵌入模型至关重要;即使是最好的重排器,如果基本搜索结果不佳,也难以提供太多帮助。
- 协同工作:要从检索器中获得最佳效果,重要的是找到嵌入模型和重排器的正确组合。这项研究表明,仔细测试并找到最佳配对的重要性。
这些结论强调了在构建高效的检索系统时,嵌入模型和重排器选择的重要性,以及它们如何协同工作以提供最佳的搜索结果。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

这篇关于增强RAG:选择最佳的嵌入和重排模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




