本文主要是介绍Advanced RAG 08:使用 Self-RAG 打造高质量、可追溯的 RAG System,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
编者按: RAG 技术通过检索并利用外部知识源,能够较为有效地提升生成内容的准确性和多样性。然而,经典 RAG 流程也存在一些不足,例如不必要的检索会浪费计算资源,并可能引入无关内容或错误信息,影响生成质量。
本文介绍了 Self-RAG 这一技术,通过引入 Reflection Tokens,语言模型能够根据具体需求动态决定是否检索外部知识,从而大大减少了不必要的检索操作。与此同时,Self-RAG 通过特殊的训练流程,使生成的内容不仅通顺自然,与事实知识相符,甚至还可以追溯知识源。
当然,Self-RAG技术训练过程相对复杂,在生成阶段也融入了诸多特殊机制,在一定程度上增加了推理成本。不过,本文作者也提出了优化 Self-RAG 的一些建议,如简化 Reflection Tokens 设计、探索不同模型大小的影响等,指明了一些技术发展方向。
作者 | Florian June
编译 | 岳扬
本文从一个常见的生活场景入手:参加开卷考试。我们通常会采用以下两种作答策略:
- 方法一: 对于熟悉的题目,直接快速作答;对于不熟悉的题目,快速翻阅参考书,找到相关部分,在脑海中整理分类和总结后,再在试卷上作答。
- 方法二: 每一个题目都需要参考书本进行解答。先找到相关部分,在脑海中进行整合和总结后,再到试卷上书写答案。
显然,方法一更受考生青睐,是首选方法。方法二不仅耗时,还有可能引入无关的或错误的信息,导致出现混淆和错误,甚至在考生原本擅长的领域也不例外。
然而,方法二是经典的 RAG (检索->整合->生成)流程 [1],而方法一则代表 Self-RAG 流程[2],本文将进一步探讨这个问题。
01 Overview
图 1 将 RAG 和 Self-RAG[2] 的主要流程进行了比较:

图 1:Overview of Self-RAG 。Self-RAG(右)的主要功能为检索(retrieve)、评判(critique)和生成(generate),使生成的文本内容不仅通顺流畅,而且与事实知识相符,并且可以追溯到原始知识源。资料来源:https://arxiv.org/pdf/2310.11511.pdf
Self-RAG 主要由三大步骤组成:
- 按需检索(Retrieval as Needed) : 当模型需要检索信息时,例如查询"美国各州的名字是怎么来的?"(图 1 右上方)时,模型输出中会包含一个 [Retrieve] token,表示需要检索与 Query 相关的内容。相反,当被要求写 “写一篇主题为 ‘记忆中深刻的暑假’ 的文章”(图 1 右下方)时,模型会选择直接生成答案,无需进行检索。
- 以并行方式生成内容(Parallel Generation) : 模型会同时使用提示词(prompt)和检索到的内容来生成模型输出。在整个过程中,有三种 reflection tokens (译者注:用于指示模型在生成过程中应该执行哪些操作、效果如何的token,比如前文的 [Retrieve]。)会显示检索内容的相关性如何。
- 内容的评估和选择: 对步骤 2 中生成的内容进行评估,并选择最佳文档段落作为输出。
请注意,上述模型是经过特殊训练的,其训练过程将在本文后续部分进行讨论。
02 Reflection Tokens 的介绍
如图 2 所示,与 RAG 相比,self-RAG 框架的不同之处在于它在生成过程中使用了 reflection tokens 进行更精确的控制。

图 2:Self-RAG 中使用的四种 reflection tokens 。每种类型都使用多个 tokens 来表示其输出值(output)。底部三行是三类 critique tokens ,粗体字表示这一类中最理想的 critique tokens 。x、y、d 分别表示输入(input)、输出(output)和相关段落(relevant passage)。来源:Self-RAG[2]
一般来说,self-RAG 会做出四种不同的判断:
- [Retrieve] : 决策过程,决定是否从资源 R 中检索额外信息。
- [IsREL] : 相关性检查,确定给定数据 d 是否包含解决问题 x 所需的信息。
- [IsSUP] : 验证过程,检查数据 d 中是否有依据支持所生成回复 y 中的内容。
- [IsUSE] : 输出结果是分数数值(数值范围 1-5 ),其中 5 代表所生成的回复对问题的解决有用程度最高。
在 RAG 系统中,检索是一个必须进行的固定步骤,无论条件如何,都要进行检索。相比之下,self-RAG 引入了 reflective tokens ,使 LLM 更具适应性(adaptable)和智能性(intelligent)。在文本生成过程中,如果 LLM 遇到了需要额外信息支持的不确定区域,它会在遇到 reflective token 时暂停执行文本生成任务,系统会执行一次快速而精确的信息检索操作,最后 LLMs 会利用新获取的信息继续完成当前的文本生成任务。
03 Code Explanation 通过解读代码了解 self-RAG
为了直观地理解 Self-RAG 过程,我们需要首先查看、检查代码,然后详细讨论模型的训练过程。
Self-RAG 这种技术是开源的[3],知名的开源 Python 库 Langchain[4] 和 LlamaIndex 都分别实现了 Self-RAG 功能。本文将以 LlamaIndex 库中 Self-RAG 的具体技术实现[5]作为参考进行说明。
3.1 环境配置
首先,进行环境配置。
(base) Florian@instance-1:~$ conda create -n llamaindex python=3.11(base) Florian@instance-1:~$ conda activate llamaindex(llamaindex) Florian@instance-1:~$ pip install llama-index(llamaindex) Florian@instance-1:~$ pip install huggingface-hub(llamaindex) Florian@instance-1:~$ huggingface-cli login
安装完成后,LlamaIndex 的版本信息如下,请确认:
llama-index 0.10.20llama-index-core 0.10.20.post2
下载论文提供的 Llama2-7B 模型,模型大小约为 4.08G。
(llamaindex) Florian@instance-1:~$ huggingface-cli download m4r1/selfrag_llama2_7b-GGUF selfrag_llama2_7b.q4_k_m.gguf --local-dir "YOUR_DOWNLOAD_MODEL_DIR" --local-dir-use-symlinks False(llamaindex) Florian@instance-1:~$ ls "YOUR_DOWNLOAD_MODEL_DIR"
selfrag_llama2_7b.q4_k_m.gguf
3.2 测试代码
测试代码如下。首次执行时需要下载 SelfRAGPack[5]。
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"from llama_index.core import Document, VectorStoreIndex
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.readers import SimpleDirectoryReader
from pathlib import Path# Option: download SelfRAGPack
# The first execution requires the download of SelfRAGPack.
# Subsequent executions can comment this out.
from llama_index.core.llama_pack import download_llama_pack
download_llama_pack("SelfRAGPack","./self_rag_pack")from llama_index.packs.self_rag import SelfRAGQueryEngine# The directory where the Llama2 model was previously downloaded and saved.
download_dir = "YOUR_DOWNLOAD_MODEL_DIR"# Create testing documents
documents = [Document(text="A group of penguins, known as a 'waddle' on land, shuffled across the Antarctic ice, their tuxedo-like plumage standing out against the snow."),Document(text="Emperor penguins, the tallest of all penguin species, can dive deeper than any other bird, reaching depths of over 500 meters."),Document(text="Penguins' black and white coloring is a form of camouflage called countershading; from above, their black back blends with the ocean depths, and from below, their white belly matches the bright surface."),Document(text="Despite their upright stance, penguins are birds that cannot fly; their wings have evolved into flippers, making them expert swimmers."),Document(text="The fastest species, the Gentoo penguin, can swim up to 36 kilometers per hour, using their flippers and streamlined bodies to slice through the water."),Document(text="Penguins are social birds; many species form large colonies for breeding, which can number in the tens of thousands."),Document(text="Intriguingly, penguins have excellent hearing and rely on distinct calls to identify their mates and chicks amidst the noisy colonies."),Document(text="The smallest penguin species, the Little Blue Penguin, stands just about 40 cm tall and is found along the coastlines of southern Australia and New Zealand."),Document(text="During the breeding season, male Emperor penguins endure the harsh Antarctic winter for months, fasting and incubating their eggs, while females hunt at sea."),Document(text="Penguins consume a variety of seafood; their diet mainly consists of fish, squid, and krill, which they catch on their diving expeditions."),
]index = VectorStoreIndex.from_documents(documents)# Setup a simple retriever
retriever = VectorIndexRetriever(index=index,similarity_top_k=10,
)model_path = Path(download_dir) / "selfrag_llama2_7b.q4_k_m.gguf"
query_engine = SelfRAGQueryEngine(str(model_path), retriever, verbose=True)# No retreival example
response = query_engine.query("Which genre the book pride and prejudice?")# Retreival example
response = query_engine.query("How tall is the smallest penguins?")
测试代码运行结果如下(大部分 llama_cpp 的调试信息已被删除):
...
...
Model metadata: {'tokenizer.ggml.add_eos_token': 'false', 'tokenizer.ggml.eos_token_id': '2', 'general.architecture': 'llama', 'llama.rope.freq_base': '10000.000000', 'llama.context_length': '4096', 'general.name': 'LLaMA v2', 'tokenizer.ggml.add_bos_token': 'true', 'llama.embedding_length': '4096', 'llama.feed_forward_length': '11008', 'llama.attention.layer_norm_rms_epsilon': '0.000010', 'llama.rope.dimension_count': '128', 'tokenizer.ggml.bos_token_id': '1', 'llama.attention.head_count': '32', 'llama.block_count': '32', 'llama.attention.head_count_kv': '32', 'general.quantization_version': '2', 'tokenizer.ggml.model': 'llama', 'general.file_type': '15'}
Using fallback chat format: Nonellama_print_timings: load time = 4887.53 ms
llama_print_timings: sample time = 11.29 ms / 22 runs ( 0.51 ms per token, 1947.76 tokens per second)
llama_print_timings: prompt eval time = 4887.46 ms / 24 tokens ( 203.64 ms per token, 4.91 tokens per second)
llama_print_timings: eval time = 5883.27 ms / 21 runs ( 280.16 ms per token, 3.57 tokens per second)
llama_print_timings: total time = 10901.84 ms / 45 tokens
Final answer: The book "Pride and Prejudice" is a romantic novel by Jane Austen.
...
...
llama_print_timings: load time = 4887.53 ms
llama_print_timings: sample time = 11.74 ms / 20 runs ( 0.59 ms per token, 1703.29 tokens per second)
llama_print_timings: prompt eval time = 7473.66 ms / 37 tokens ( 201.99 ms per token, 4.95 tokens per second)
llama_print_timings: eval time = 5414.34 ms / 19 runs ( 284.96 ms per token, 3.51 tokens per second)
llama_print_timings: total time = 13076.88 ms / 56 tokens
Input: ### Instruction:
How tall is the smallest penguins?### Response:
[Retrieval]<paragraph>Penguins consume a variety of seafood; their diet mainly consists of fish, squid, and krill, which they catch on their diving expeditions.</paragraph>
Prediction: [Relevant]The height of the smallest penguin species can vary depending on the species.[No support / Contradictory][Utility:5]
Score: 1.4213598342974367
10/10 paragraphs doneEnd evaluation
Selected the best answer: [Relevant]The smallest penguin species is the Little Blue Penguin (also known as the Fairy Penguin), which can grow to be around 40 centimeters (16 inches) in height.[Fully supported][Utility:5]
Final answer: The smallest penguin species is the Little Blue Penguin (also known as the Fairy Penguin), which can grow to be around 40 centimeters (16 inches) in height.
我们可以看到,第一个 query 不需要执行检索操作,而第二个 query 已进行了检索操作并进行了输出内容的评估。
理解测试代码的关键在于弄清楚类 SelfRAGQueryEngine[6] 的实现,现在我们来深入探讨一下这个类。
3.3 类 SelfRAGQueryEngine
首先来看看构造函数[7],它主要用于使用 llama_cpp 加载 Llama2-7B 模型。
class SelfRAGQueryEngine(CustomQueryEngine):"""Simple short form self RAG query engine."""llm: Any = Field(default=None, description="llm")retriever: BaseRetriever = Field(default=None, description="retriever")generate_kwargs: Dict = Field(default=None, description="llm generation arguments")verbose: bool = Field(default=True, description="Verbose.")def __init__(self,model_path: str,retriever: BaseRetriever,verbose: bool = False,model_kwargs: Dict = None,generate_kwargs: Dict = None,**kwargs: Any,) -> None:"""Init params."""super().__init__(verbose=verbose, **kwargs)model_kwargs = model_kwargs or _MODEL_KWARGSself.generate_kwargs = generate_kwargs or _GENERATE_KWARGStry:from llama_cpp import Llamaexcept ImportError:raise ImportError(_IMPORT_ERROR_MSG)self.llm = Llama(model_path=model_path, verbose=verbose, **model_kwargs)self.retriever = retriever
接下来,我们将介绍处理 query 的相关函数[8]。其主要流程如图 3 所示:
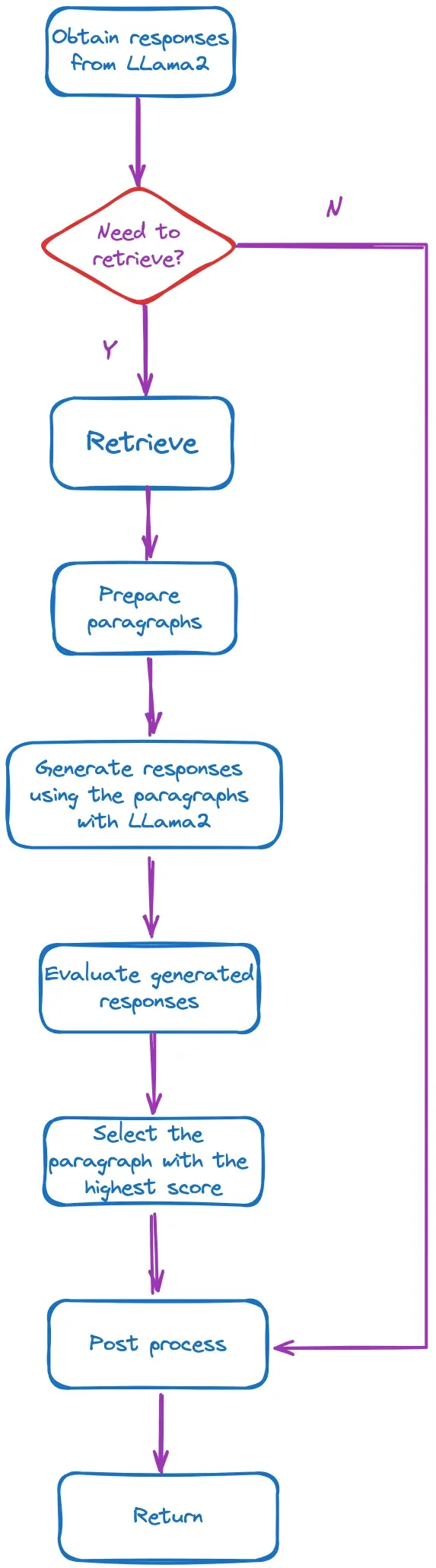
图 3:query 处理功能的主要流程。图片由作者提供。
关键部分已作注释,以便读者更好地理解。
def custom_query(self, query_str: str) -> Response:"""Run self-RAG."""# Obtain responses using the Llama2 model.response = self.llm(prompt=_format_prompt(query_str), **_GENERATE_KWARGS)answer = response["choices"][0]["text"]source_nodes = []# Determine if a retrieval is necessary.if "[Retrieval]" in answer:if self.verbose:print_text("Retrieval required\n", color="blue")# The step 1 of Figure 1, retrieve as needed.documents = self.retriever.retrieve(query_str)if self.verbose:print_text(f"Received: {len(documents)} documents\n", color="blue")paragraphs = [_format_prompt(query_str, document.node.text) for document in documents]if self.verbose:print_text("Start evaluation\n", color="blue")# Step 2 and 3 in Figure 1, generate in parallel and evaluate # (the code does not implement parallelism)critic_output = self._run_critic(paragraphs)paragraphs_final_score = critic_output.paragraphs_final_scorellm_response_per_paragraph = critic_output.llm_response_per_paragraphsource_nodes = critic_output.source_nodesif self.verbose:print_text("End evaluation\n", color="blue")# Select the paragraph with the highest score and return it.best_paragraph_id = max(paragraphs_final_score, key=paragraphs_final_score.get)answer = llm_response_per_paragraph[best_paragraph_id]if self.verbose:print_text(f"Selected the best answer: {answer}\n", color="blue")answer = _postprocess_answer(answer)if self.verbose:print_text(f"Final answer: {answer}\n", color="green")return Response(response=str(answer), source_nodes=source_nodes)
从代码中可以看到,图 1 中的三个步骤都有所体现。然而,LlamaIndex 的 self-RAG 功能并未实现并行化。感兴趣的读者可以查看 self._run_critic 函数了解更多信息,该函数也处理与各种 reflection tokens 相对应的分数。
04 如何训练 Llama2–7B 模型
我们以前曾多次使用过 Llama2-7B 模型,本文来探讨一下如何获取和训练该模型。
4.1 训练目标
使语言模型能够生成包含 reflection tokens 的文本。
4.2 两个模型
在训练过程中,需要使用两个模型:批判模型(critic model) C 和生成模型(generator model) M。批判模型 C 主要生成 M 所需的已经标注好的用于有监督学习任务的数据(supervision data)。
然而,在推理过程中,只需使用模型 M,不需要批判模型 C。
4.3 批判模型 C
批判模型(critic model)经过训练可生成 reflection tokens 。使用该模型是为了在任务输出中能够离线插入 reflection tokens ,从而更新训练语料库(training corpus)。
手动为每个文本段落标注 reflection tokens 的成本非常高。Self-RAG 利用 GPT-4 根据不同 reflection token 的定义、输入和输出,为每个 reflection token 分配唯一的特定指令,从而高效地完成数据标注任务。例如,[retrieval] token 会指导模型在进行内容评估时是否需要检索外部文档。
获得训练数据 D_critic 后,我们就可以基于传统的、基于条件的语言模型(standard conditional language model)构建用于训练机器学习模型的目标函数,如下所示:
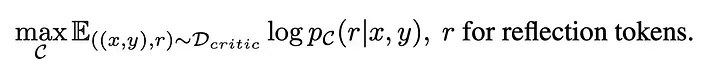
批判模型 C 可以用任何预训练的语言模型进行初始化和进一步微调。 例如,它可以直接使用与生成模型相同的预训练模型(如Llama 2 7B)进行初始化。
4.4 生成模型 M
图 4 显示了在 Self-RAG 框架中如何收集用于训练生成模型(Generator)的 supervision data(译者注:已经标注好的用于有监督学习任务的数据) 。给定一对输入输出(x, y),self-RAG 使用检索器和批判模型对原始的模型输出 y 进行标注,从而创建 supervision data(译者注:已经标注好的用于有监督学习任务的数据) 。对于 y 中的每个段落 yt(yt ∈ y):

图4:收集生成模型(generator)的训练数据。图中的每次条件判断都是通过批判模型 C 执行的。该图片由作者提供,灵感来源于 Self-RAG[2] section 3.2.2 。
请注意,图 4 中的每次条件判断都是通过批判模型 C 执行的。获得的训练数据如图 5 所示:

图 5:Self-RAG 训练示例。左边的例子不需要进行外部检索,而右边的例子需要检索外部文档,因此插入了相关文档段落。来源:Self-RAG[2]。
获得训练数据 D_gen 后,我们就可以构建用于训练语言模型的 standard next-token prediction objective function (译者注:"Standard"指这是语言模型训练中最普遍、最基础的目标函数形式。"Next-token prediction"指的是该函数的目标是预测序列中的下一个token(词元),"Objective function"即目标函数,可能是损失函数等内容。)啦,如下所示:
生成模型 M 需要预测的不仅仅是输出内容,还包括 reflection tokens 。
05 作者对 self-RAG 的见解和思考
总体来看,self-RAG 为 RAG 技术的增强和优化提供了一种全新的视角。不过,这种技术需要更复杂的训练流程,并且在内容生成阶段(generation phase) 融入了一些特殊机制,不仅生成目标输出文本,还会生成多种类型的反馈标签,并在生成时根据这些标签执行多个判断操作,这样会不可避免地会增加推理成本 。可能会严重影响重视实时性能要求的项目。
此外,该框架还有很大的优化空间。为激发进一步的讨论和创新,这里有一些建议:
- 如何优化 reflection tokens 。 Self-RAG 设计了四种 reflection tokens 。除了 [Retrieve] token 之外,其他三个([IsREL]、[IsSUP]、[IsUSE])都有一定的相似性。可以考虑使用更少的 reflection tokens ,或者设计表示其他语义的 reflection tokens ,这可能是一个值得探索的优化方向。
- 为什么批判模型(critic model)要使用大语言模型(LLM)呢? 我认为这可能是由于像[IsUSE]这样的 token 严重依赖于常识性知识。判断某个回答的有用,是一项较小的模型可能也能够胜任的任务。然而,这些较小的模型通常仅学习了特定的训练数据,缺乏全面的知识。因此,使用LLM作为批判模型(critic model)是有道理的。
- 批判模型(critic model)模型大小的选择。 我们已经在 7B 和 13B 的模型上对 Self-RAG 进行了测试,结果非常出色。但是,如果我们切换到较小尺寸的 LLM,比如 3B ,会观察到哪些差异?同样,如果我们过渡到使用更大的 LLM ,比如 33B ,我们又能预见到多大的系统性能提升呢?
- 为什么不使用基于人类反馈的强化学习(RLHF)呢? 该论文建议在特定任务示例数据(task examples)上训练目标语言模型。然后使用离线但是批判模型对这些数据进行增强(使用 reflection tokens),与 RLHF 相比,训练成本大大降低。此外,self-RAG 中的 reflection tokens 使得在推理阶段的内容生成可控,而 RLHF 专注于在训练期间与人类的偏好对齐。不过,论文中没有包含任何与 RLHF 相关的对比实验。
06 Conclusion
本文从一个直观的生活场景(开卷考试)入手,介绍了 self-RAG 技术的基本流程,并辅以代码解释。文章还分享了作者的一些见解和思考。
如果你对 RAG(检索增强生成) 技术非常感兴趣,欢迎浏览、分享本系列其他文章。 : )
Thanks for reading!
Julian Yip
Multi-Cloud Data Architect | Azure, GCP, Databricks Certified | ML and MLOps Practitioner
END
参考资料
[1]https://medium.com/ai-in-plain-english/a-brief-introduction-to-retrieval-augmented-generation-rag-b7eb70982891
[2]https://arxiv.org/pdf/2310.11511.pdf
[3]https://github.com/AkariAsai/self-rag
[4]https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_self_rag.ipynb?ref=blog.langchain.dev
[5]https://github.com/run-llama/llama_index/tree/v0.10.20/llama-index-packs/llama-index-packs-self-rag
[6]https://github.com/run-llama/llama_index/blob/v0.10.20/llama-index-packs/llama-index-packs-self-rag/llama_index/packs/self_rag/base.py
[7]https://github.com/run-llama/llama_index/blob/v0.10.20/llama-index-packs/llama-index-packs-self-rag/llama_index/packs/self_rag/base.py#L174
[8]https://github.com/run-llama/llama_index/blob/v0.10.20/llama-index-packs/llama-index-packs-self-rag/llama_index/packs/self_rag/base.py#L245
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接:
https://ai.gopubby.com/advanced-rag-08-self-rag-c0c5b5952e0e
这篇关于Advanced RAG 08:使用 Self-RAG 打造高质量、可追溯的 RAG System的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





