本文主要是介绍Discriminative Information Retrieval for Question Answering Sentence Selection论文笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文下载地址
摘要
该算法提出场景:text-based QA,即给定一段文字说明,提出问题,从文字说明中找出相应答案作答。
text-based QA算法的主要步骤包含三个:1)获取可能包含答案的段落;2)候选段落的重排;3)提取信息选择答案
本文的算法主要是解决第一个步骤
算法
算法主要框架:
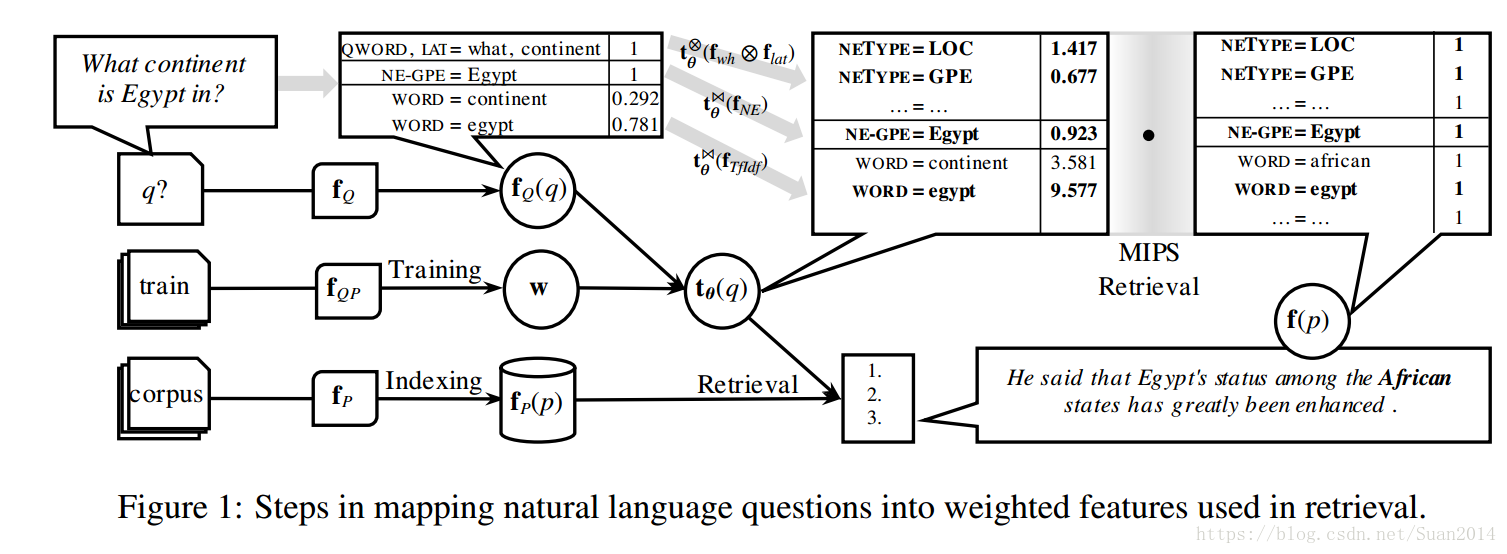
预处理:将文字说明切成一句一句,每句都作为第一步的候选集,设,假设query为q,得分函数为F(q,p),IR系统(即上述三个步骤的第一步)的目标是检索出前k个p,目标函数为:
(1)
设为query q的特征,
为候选集p的特征,
是由
和
合成的(query, candidate)对的特征:
(2)
训练权重向量,使得优化目标为:
,转为:
(3),这样
相当于将query q提取特征后,先进行query expansion再采用点积与获选集计算相似度得分。下边将如何提取特征
特征
特征向量f中的一个项表示为“(KEY = value,weight)”,并且特征向量可以被视为一组这样的元组,写f(KEY = value)= weight表示特征作为关联数组的关键,θX是训练模型中特征X的权重θ。
1.问题特征
:问题词,如问题是how many,则(QWORD=how many, 1)添加到特征向量中;
:词汇答案类型(LAT),如果query有问题词:“what”或“which”这个问题的LAT被定义为问题词之后的第一个名词短语(NP)。 例如,“What is the city of brotherly love?”,该元组为(LAT = city,1)
:所有的命名实体,如:(NE-PERSON=Margaret Thatcher,1)
:tf-idf ,如
2.段落特征(即候选句特征)
:词袋,段落中任何不同的x都会产生一个特征
:命名实体类型。如果段落包含人名,则将生成(NETYPE = PERSON,1特征
特征向量算法
1.合成
首先要实现公式2,对任何的query特征向量fQ(q)= {(ki = vi,wi)},(wi≤1)和,定义两个操作:
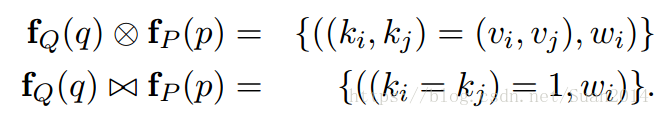
ki=kj表示ki和kj的值相同。
C定义:

2.映射
定义:,
,
则上式公式(3)中的t(theta)(q)得到表达
至此,通过(query, candidate)对进行训练获取theta值即可
这篇关于Discriminative Information Retrieval for Question Answering Sentence Selection论文笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








