selection专题

Failed to pull selection解决办法
今天在使用DDMS导出文档到PC端的时候,明明在file explorer里面有文件,导出时候就是失败,出现了“Failed to pull selection”错误。百度了一下,还是重启Eclipse最靠谱。

王立平--Failed to push selection: Read-only file system
往android模拟器导入资源,失败。提示:只读文件、 mnt是只读文件。应点击sdcard,,在导入

【机器学习 sklearn】特征筛选feature_selection
特征筛选更加侧重于寻找那些对模型的性能提升较大的少量特征。 继续沿用Titannic数据集,这次试图通过特征刷选来寻找最佳的特征组合,并且达到提高预测准确性的目标。 #coding:utf-8from __future__ import divisionimport sysreload(sys)sys.setdefaultencoding('utf-8')import timest

ATSS论文要点总结(Adaptive Training Sample Selection)
“ATSS” 全称为 “Adaptive Training Sample Selection”,意为自适应训练样本选择,相关论文的主要内容如下: 核心观点:在目标检测中,anchor-based 和 anchor-free 检测器性能差异的关键在于正负样本的定义方式。如果训练过程中使用相同的正负样本定义,两者性能将无明显差异。基于此,作者提出 ATSS 方法,根据目标的统计特征自动选择正负样本,
2024牛客暑期多校训练营7 D.Interval Selection(异或哈希+双指针)
原题链接:D.Interval Selection 题目大意: 给你一个长度为 n n n 的数组 a a a,定义一个区间 [ l , r ] [l,r] [l,r] 内的连续子数组为好的,当且仅当这个子数组内的所有元素 a l , a l + 1 , . . . , a r a_{l},a_{l+1},...,a_{r} al,al+1,...,ar 在当前区间中恰好
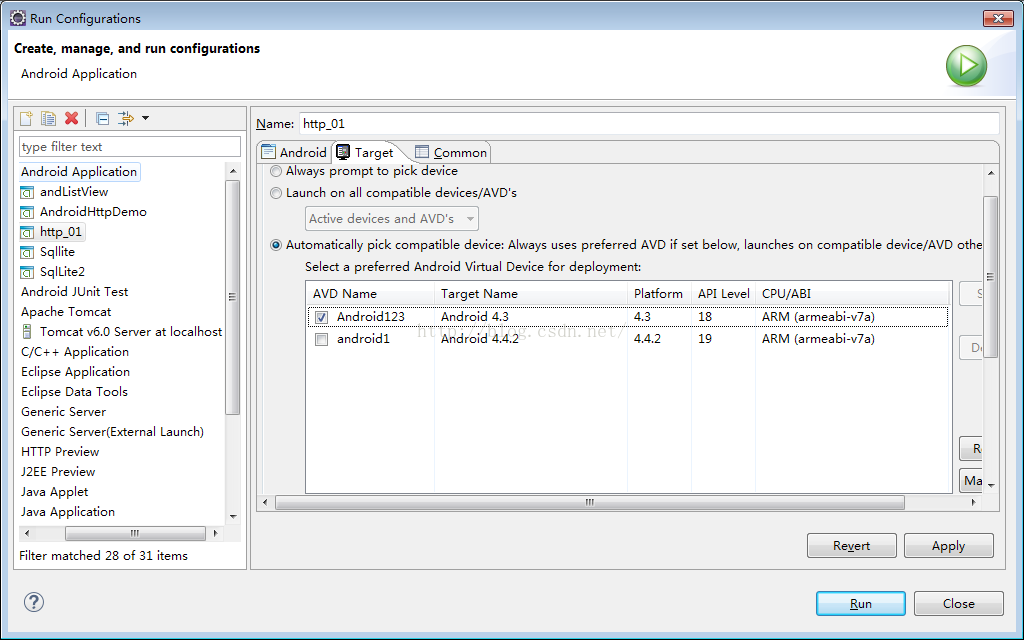
the selection cannot be launched,and there are no recent launches
刚学android开发,运行项目是提示 the selection cannot be launched,and there are no recent launches 经过百度之后, 处理方法: 第一步: 进入工程——>properties-->run/debug setting 删除所有 第二步: 点击运行那个小三角,进行Android配置 选择
CSS的::selection使用方法
请选择本页面文本看看:http://hovertree.com/h/bjaf/38hq6y9d.htmCSS改变默认文本选中的颜色的方法 一般情况下在网页里的文本我们用鼠标选中的时候都是蓝色的,这个默认颜色也是可以更改的,本文我们学习如何使用CSS3实现改变默认文本选中的颜色。以我的系统举例(xp 默认主题),浏览器上页面文字选中后默认的背景色是一种蓝色, 不同浏览器的颜色有些许差异,但大致相同

RT-DETR 详解之 Uncertainty-minimal Query Selection
引言 在上一章博客中博主已经完成查询去噪向量构造部分的讲解(DeNoise)在本篇博客中,我们将进行Uncertainty-minimal Query Selection创新点的讲解。 Uncertainty-minimal Query Selection是RT-DETR提出的第二个创新点,其作用是在训练期间约束检测器对高 IOU 的特征产生高分类分数,对低 IOU 的特征产生低分类分数。从而

element中table的selection-change监听改变的那条数据的下标
<el-table ref="table" :loading="loading" :data="tableData" @selection-change="handleSelectionChange"></el-table> 当绑定方法selection-change,当选择项发生变化时会触发该事件 // 多选框选中数据handleSelectionChange(selection) {
【记录43】el-table @selection-change 数据回显、条件约束、历史回显清除
场景 在其他地方设置好人员,到对应的页面直接在表格中复选设置好的人员。解决方案用到selection-change方法 <el-button @click="EchoClick()">回显设置好的人</el-button><el-table ref="choeck" :data="TableData" @selection-change="SelectionChange" id="noAll
论文笔记:A Gated Self-attention Memory Network for Answer Selection
作者:陈宇飞 单位:燕山大学 论文地址:https://www.aclweb.org/anthology/D19-1610/ 论文代码:https://github.com/laituan245/StackExchangeQA 目录 一、研究问题二、解决思路三、模型设计3.1 The gated self-attention mechanism3.2 Combining w
elementUI type=“selection“多选框选中 删除 回显 赋值问题 回显数组改变选中状态未改变
业务需求: 点击查询弹列表框 勾选列表选项保存 可删除可重新查询列表添加 遇到的问题:删除之后查询列表selection回显问题 解决:@row-click配合:reserve-selection="true"使用 <el-tableref="refPlanTable":data="refPlanTableData"tooltip-effect="dark":max-heigh
【数据结构与算法】选择算法 selection
选择算法指的是解决选出序列中第n大的元素。比如中位数。 方法如下: 1.使用priorityqueue,维持size为k,如果queue的size小于k,则直接加入,否则看最小的元素能否比得过,比得过就剔除最小元素,加入新元素,比不过就看后面的元素,最后返回堆顶元素即可。这里需要使用最小堆。 public int findKthMax(int[] array, int k){Prior
用pycharm出现,ImportError: No module named model_selection
首先,先说明,本人出现这个问题,是因为需要使用 train_test_split 方法,具体的引用是: from sklearn.model_selection import train_test_split 出现了这个错误: ImportError: No module named model_selection 在网上查了下,大致了解到问题的原因,大神给的一件是,我的sklearn版本
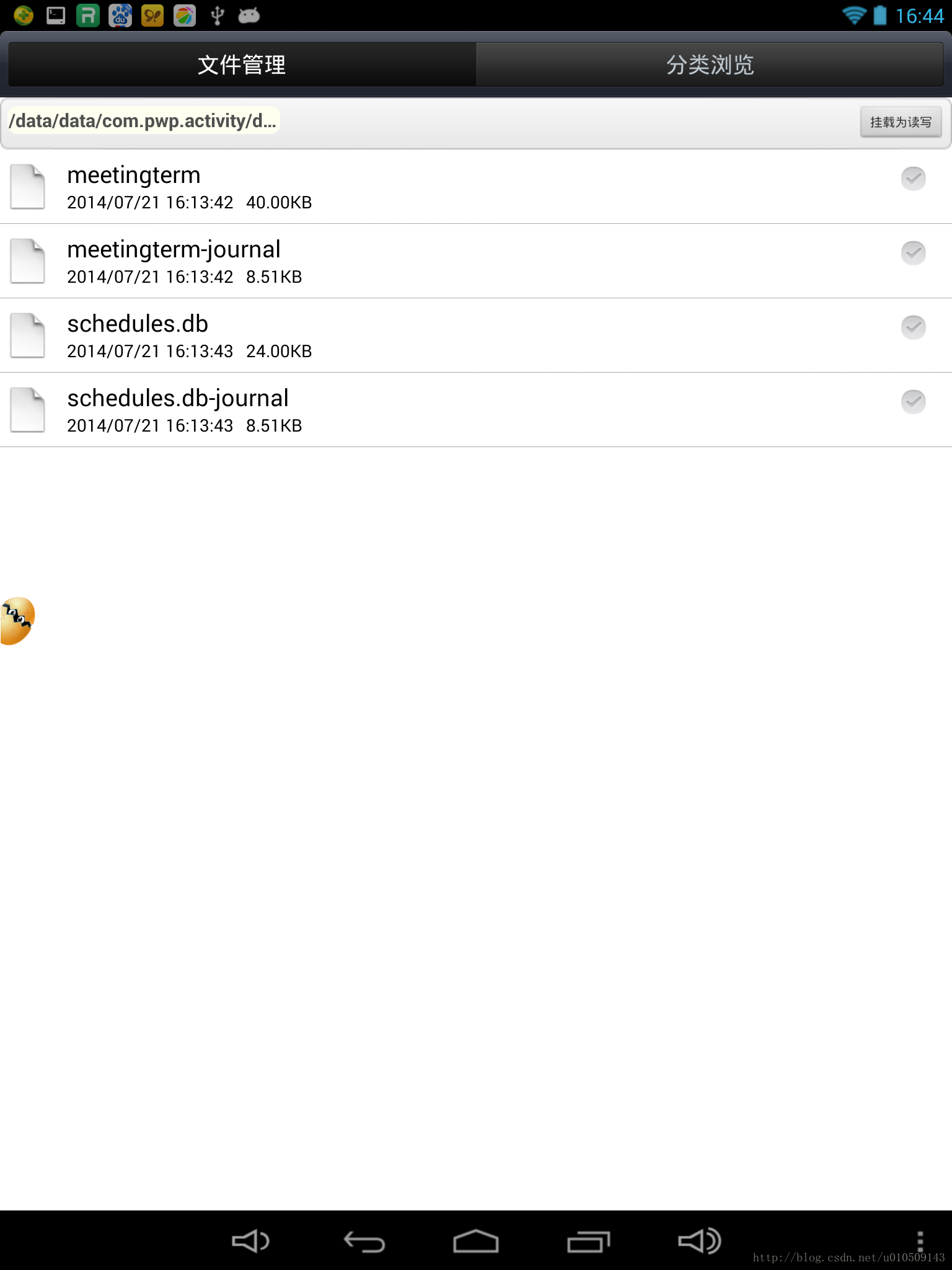
显示data 文件夹但是打不开 以及Failed to pull selection 解决方案;
显示data 文件夹但是打不开, 1 我下 adb shell-su -chmod 777/data -chmod 777/data/data; 总是报错permission denied; 后来 我插拔了一下; 重新root 一下; 安装了re管理器; 找到data /data 进行权限的授予.就好了; [2014-07-21 16:35:11] Failed to pul
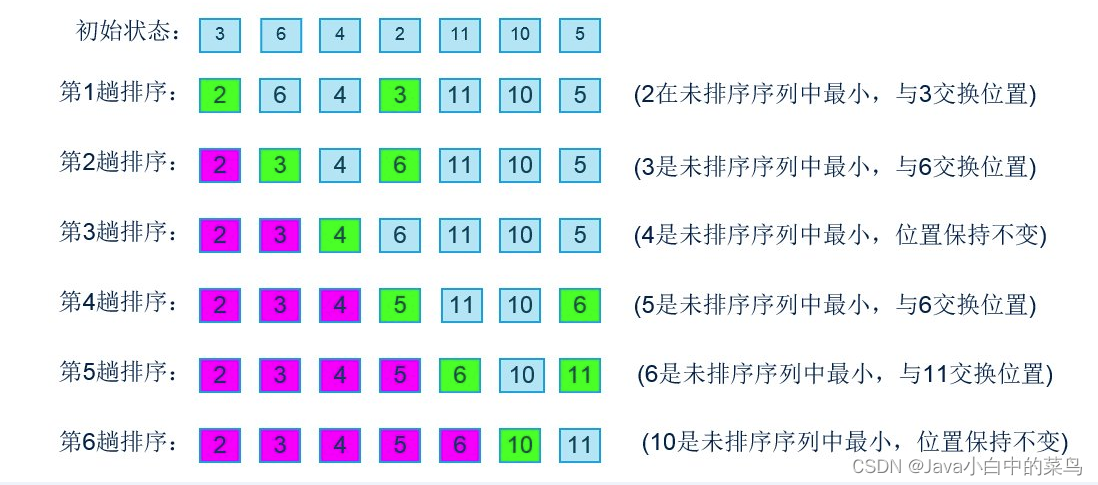
排序-选择排序(selection sort)
选择排序(selection sort)的工作原理非常简单:开启一个循环,每轮从未排序区间选择最小的元素,将其放到已排序区间的末尾。选择排序的主要特点包括: 时间复杂度: 无论最好、最坏还是平均情况,选择排序的时间复杂度均为O(n^2),其中n是列表长度。这是因为每一轮都需要遍历剩余的未排序元素来寻找最小值,共需进行n-1轮比较。 空间复杂度: 选择排序是原地排序算法,除了用于交换的临时变量外
![[深度学习论文笔记][AAAI 18]Accelerated Training for Massive Classification via Dynamic Class Selection](https://img-blog.csdn.net/2018052520261694?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTAxNTg2NTk=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
[深度学习论文笔记][AAAI 18]Accelerated Training for Massive Classification via Dynamic Class Selection
[AAAI 18] Accelerated Training for Massive Classification via Dynamic Class Selection Xingcheng Zhang, Lei Yang, Junjie Yan, Dahua Lin from CUHK & SenseTime paper link Motivation 这篇文章研究当分类器分类个数非常

LLVM Instruction Selection 笔记
Instruction Selection 所处阶段 注:上图来源于 Welcome to the back-end: The LLVM machine representation 可以看到 SelectionDAG 架在 LLVM IR 和 LLVM MIR 之间,在此之前 machine independent optimization 已经完成。之后基本上就进入了 machine
如果的打开Word文档是Visible参数设为false你会得不到Selection实体
以下是异常重现代码: using System;using System.Collections.Generic;using System.Linq;using System.Text;using System.Windows;using System.Windows.Controls;using System.Windows.Data;using System.Windows
[tensorflow] sklearn包中label_binarize和model_selection.train_test_split
sklearn文档: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.label_binarize.html#sklearn.preprocessing.label_binarize sklearn.preprocessing.label_binarize 类的顺序被保留: from skl
机器学习之特征选择(Feature Selection)
1 引言 特征提取和特征选择作为机器学习的重点内容,可以将原始数据转换为更能代表预测模型的潜在问题和特征的过程,可以通过挑选最相关的特征,提取特征和创造特征来实现。要想学习特征选择必然要了解什么是特征提取和特征创造,得到数据的特征之后对特征进行精炼,这时候就要用到特征选择。本文主要介绍特征选择的三种方法:过滤法(filter)、包装法(wrapper)和嵌入法(embedded)。 特征提取

Python+selenium自动化之29----EC模块之element_located_selection_state_to_be
上一篇介绍selenium中一个模块expected_conditions判断文本是否存在的方法text_to_be_present_in_element。如果有多个选择框需要验证是否被勾选或取消勾选,就需要用到本篇文章介绍的方法element_located_selection_state_to_be。 实例还是结合腾讯企业邮箱的使用。 源码element_located_selection
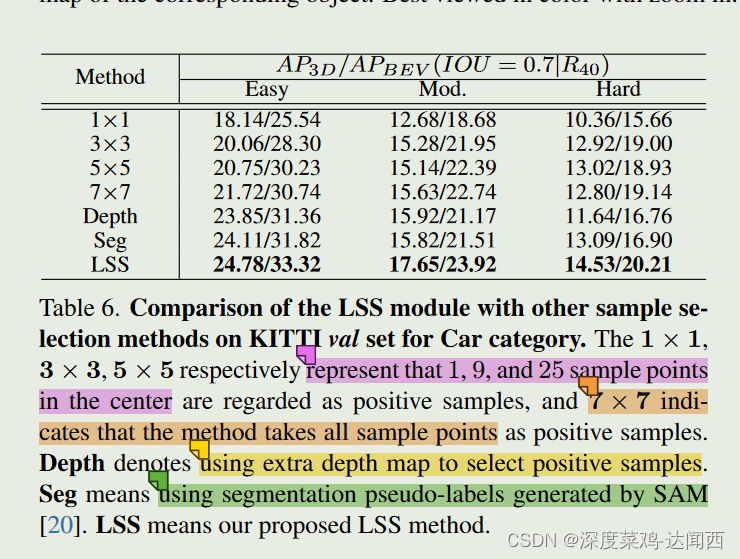
论文笔记 - :MonoLSS: Learnable Sample Selection For Monocular 3D Detection
论文笔记✍MonoLSS: Learnable Sample Selection For Monocular 3D Detection 📜 Abstract 🔨 主流做法+限制 : 以前的工作以启发式的方式使用特征来学习 3D 属性,没有考虑到不适当的特征可能会产生不利影响。 🔨 本文做法: 本文引入了样本选择,即只训练合适的样本来回归 3D 属性。 为了自适应地选择样本,

【论文阅读】Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network
目录 一、简介二、方法1. 任务: 多轮对话回复选择2. 模型架构attention 模块Representation:Matching:Aggregation: 三、实验1. 数据集2. 评价指标3. 实验设置4. 实验结果 四、结果分析1. 实验结果分析2. 注意力可视化3. 错误分析 一、简介 研究了使用依赖信息来匹配回复和它的多回合上下文,以两种方式扩展了Tr

图像分割论文阅读:Adaptive Context Selection for Polyp Segmentation
这篇论文的主要内容是关于一种用于息肉分割的自适应上下文选择网络(Adaptive Context Selection Network,简称ACSNet) 1,模型的整体结构 模型的整体结构基于编码器-解码器框架,并且包含了三个关键模块:局部上下文注意力模块(LCA)、全局上下文模块(GCM)和自适应选择模块(ASM)。 2,LCA模块 它的主要目的是在合并浅层特征时,通过挖掘硬样本来引

论文阅读——Efficient and Robust Feature Selection via Joint L2,1-Norms Minimization
一、前言 最近因为对结构化多任务学习,以及对带范数目标函数求解的学习,一直都很想求解带L2,1范数的目标函数(其实这只是个过程),针对这样的不光滑目标函数,梯度下降法并不合适。 虽然sklearn中的MultiTaskLasso也是这样的目标函数,并且使用了坐标下降法来求解,但是当目标函数中的损失函数也用L2,1范数时我又懵圈了。 正当我琢磨是不是能把两部分合在一起求解一个L2,1范数时(其