本文主要是介绍RT-DETR 详解之 Uncertainty-minimal Query Selection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
在上一章博客中博主已经完成查询去噪向量构造部分的讲解(DeNoise)在本篇博客中,我们将进行Uncertainty-minimal Query Selection创新点的讲解。
Uncertainty-minimal Query Selection是RT-DETR提出的第二个创新点,其作用是在训练期间约束检测器对高 IOU 的特征产生高分类分数,对低 IOU 的特征产生低分类分数。从而使得模型根据分类分数选择的 Top-K 特征对应的预测框同时具有髙分类分数和高 IOU 分数。
如下图,这是RT-DETR所作的一个分析,其中蓝色代表使用查询选择后的结果,可以看到其随着IOU分数变高,其分类分数也较高,而绿色代表原方法,可以看到IOU分数高的分类分数并不高。

这部分其实对应的是输入到Decoder中的数据处理部分,即位于rt_decoder.py中的_get_decoder_input方法中
代码分析
进入_get_decoder_input方法后,首先进行的是构造Anchor,对应的是_generate_anchors方法
构造Anchor
_generate_anchors方法的输入参数为各个特征图的维度大小spatial_shapes
其代码如下,该方法原理和YOLOv1的思想很类似,每个像素点产生一个Anchor,如第一层特征图中有100x100个Anchor,第二层特征图中有50x50个Anchor。

生成的grid_x,grid_y 以及 grid_xy 的值

anchors.append(torch.concat([grid_xy, wh], -1).reshape(-1, h * w, 4))将宽高和中心点坐标拼接在一起,最终获得三层特征图内的 Anchor

最终,会根据我们设置的一个阈值来选择出一部分Anchor

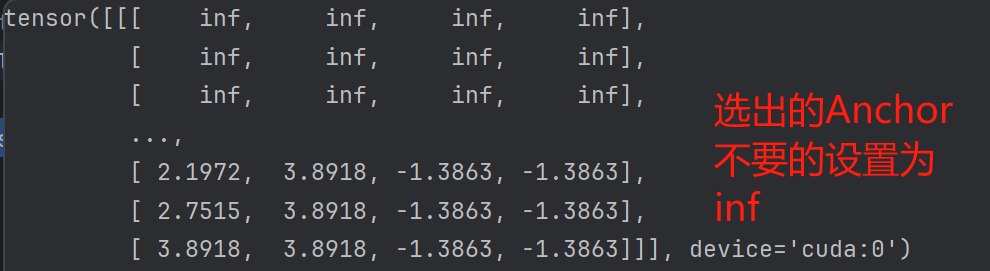
这里可以认为是生成Anchor先验,RT-DETR认为目标更多的集中在中心区域,即中心区域的特征更容易产生高IOU,而到了最后一个特征图,由于语义特征非常丰富,所以近似会认为所有特征都很有用,故而全部选择了。

Topk查询向量选择
继续进行Decoder输入数据的构造,通过一系列方法,在根据类别选择Top-k输入Decoder的特征向量的过程中,就可以选出相对IOU分数也较高的查询向量了。具体操作如下:
首先,将Encoder输出的特征图进行进一步处理:
output_memory = self.enc_output(memory)
memory:torch.Size([4, 13125, 256])
output_memory:torch.Size([4, 13125, 256])
RT-DETR对分类头与预测框头进行了解耦,首先将该特征图(output_memory)输入分类头,获取分类结果(这里是初筛Encoder的结果,为下一步选择Topk特征做准备)
enc_outputs_class = self.enc_score_head(output_memory)

随后将特征图(output_memory)输入回归头,并于先前构造的anchor相结合:
enc_outputs_coord_unact = self.enc_bbox_head(output_memory) + anchors
回归头的构造如下,其输出维度为4,对应 (x y w h)。
ModuleList((0-1): 2 x Linear(in_features=256, out_features=256, bias=True)(2): Linear(in_features=256, out_features=4, bias=True)
)


最终,将其进行Topk选择,选择的数量为300(num_queries)
_, topk_ind = torch.topk(enc_outputs_class.max(-1).values, self.num_queries, dim=1)
选择出的top_ind即选中的特征图的索引。

最后,按照先前的分类结果(top_ind)从回归结果中选出Topk个结果。
关于torch的gather函数的用法可以参考这篇文章:
torch.gather用法
我们可以看到此时的input为enc_outputs_coord_unact ,其维度为1,代表纵向,按列取整,此时索引为topk_ind展平后的结果,已知topk_ind为(4,300),博主举了一个简单案例来展示这个过程:

上述部分的完整代码如下:

最终,获得筛选后的enc_topk_bboxes的特征维度为torch.Size([4, 300, 4]),通过上述过程,在进行特征向量选择的过程中,由于anchor在构造时具有倾向性,即多位于一些中心点区域,因此其anchor具有高IOU,在最后选择时,再选择这里面分类分数高的特征,从而选择高分类分数与高IOU分数的特征。
我的理解
至此,我们来最终分析一下其原理:其相较于DETR类其他方法初始随机设置查询向量(如DAB-DETR的box query一般初始为0,可认为是先验 anchor),这里RT-DETR则在Anchor初始化时给定了的假设,即目标大多位于中心区域,认为这部分的特征能够产生较高IOU的查询向量,在完成anchor初始化后,并将该anchor与Encoder得到的anchor相加,得到Encoder最终输出的anchor(enc_output_coord_unact),注意,每轮训练或者推理过程中的产生的先验anchor是固定的,即每次先验条件是相同的,但它会与Encoder得到的anchor结合后,即给定训练倾向,最终也就导致Encoder逐步产生一些具有高IOU的特征。
最终输出结果
最终将Encoder得到的特征图生成的查询向量与查询降噪生成的查询向量结合起来,输入Decoder进行下一步的操作。
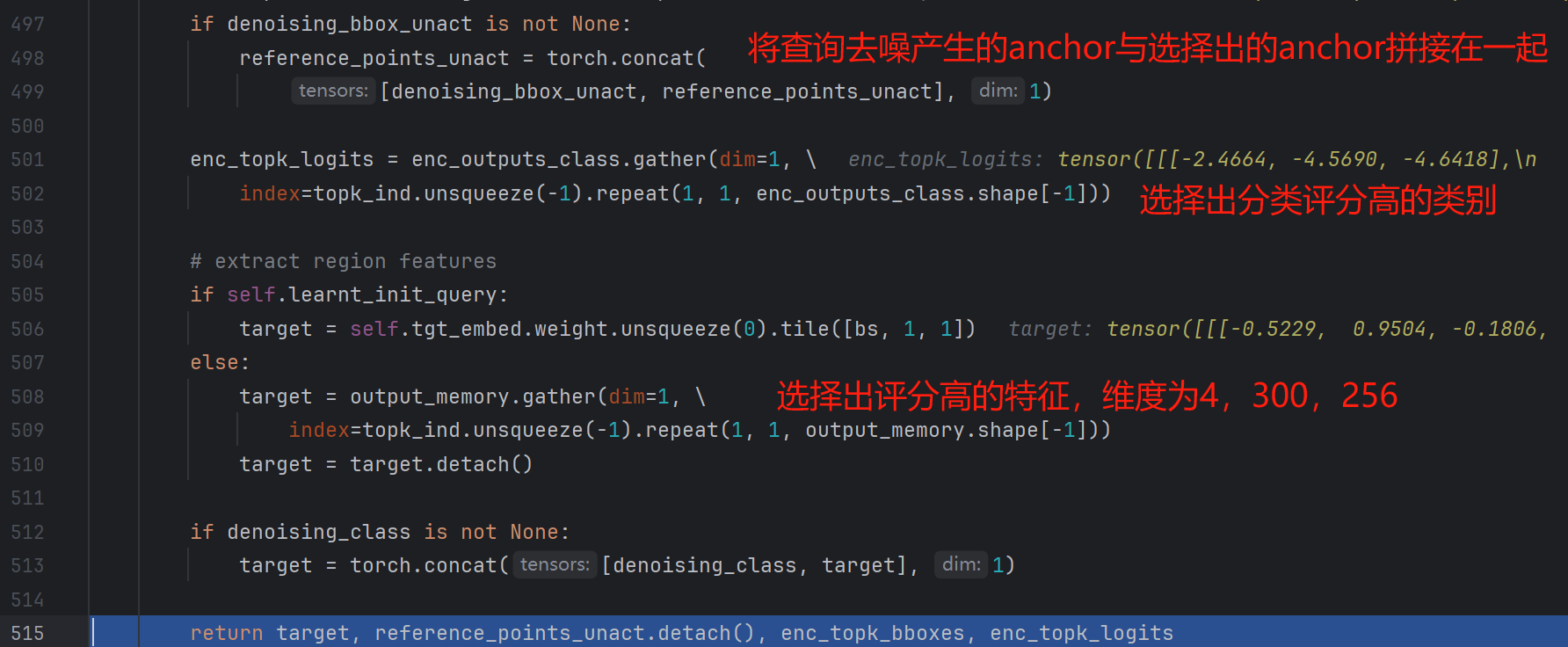
最终将选择出的300与查询去噪构造的198结合起来,得到(4,498,256)的特征。
最终得到的返回值如下:
return target, reference_points_unact.detach(), enc_topk_bboxes, enc_topk_logits
这个target就是用于输入Decoder的特征。



至此,完成了Uncertainty-minimal Query Selection过程。
这篇关于RT-DETR 详解之 Uncertainty-minimal Query Selection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






