本文主要是介绍[深度学习论文笔记][AAAI 18]Accelerated Training for Massive Classification via Dynamic Class Selection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
[AAAI 18] Accelerated Training for Massive Classification via Dynamic Class Selection
Xingcheng Zhang, Lei Yang, Junjie Yan, Dahua Lin
from CUHK & SenseTime
paper link
Motivation
这篇文章研究当分类器分类个数非常大的时候,如何高效训练分类器的问题。在网络的输出层,Softmax分类器会对每一个类产生一个输出。因此输出层的参数量、占用的空间和计算量是和分类个数呈正相关的。当在某些实际应用场景下,如人脸识别、自然语言处理等,其分类个数(如人的身份数量、单词种类数)会非常大,以至于使网络的输出层的参数多到无法存储在显卡中,而且无法承受如此量级的计算。这篇文章针对这个问题提出一点观察结果和一个解决该问题的方案。其分析和观察的结果是:
- 对于一个输入样本,其输出概率只集中在少量的类别中,可以称这些类别为活跃类(active class);
- 在同一迭代过程中,回传梯度主要受这些活跃类影响,其他类别的贡献很小。
因此一个解决方案便是前向和反向过程中只计算和这些活跃类相关的东西。本文提出的解决方案便是如何动态搜索得到这些活跃类到底是哪些。下面就详细介绍这篇文章的分析和观察的细节,以及解决方案的内容。
An Empirical Study of Softmax
作者通过实验来验证其关于Softmax概率分布的分析结论。为此提出了两个新的概念,
- top K累积概率:将输出的概率向量里最大的K个值相加(k=1,100,1000),其结果往往接近于1;
- 归一化的top K梯度累积能量:虽然名字很拗口,但是其实质是输出层所有梯度与top K类产生的梯度的余弦相似度,用来衡量top K类产生的梯度占所有梯度的比例。
作者在MS-Celeb-1M数据库上训练人脸识别网络,下图为统计结果。可见活跃类确实在产生的概率(图中(a))和回传的梯度(图中(b))上都占主导作用。

Selective Softmax
在上个图中,即便K=1000,其top K类仍占总类别数很小的比例(如MS-Celeb-1M中只占1.5%)。因此在训练过程中能针对不同的样本找到对应的活跃类是降低计算和存储代价的关键。
对一个输入特征x,输出层的权重矩阵为W。寻找top K类即是找到W中和这些活跃类关联的k个列向量。因为每个活跃类的概率由 wix w i x 得到,且最终的结果都很大,因此搜索活跃类过程可以转化为对W的列项量 wi w i 进行聚类。最终选取可以使 wix w i x 结果最大的那一类。
Hashing Forest
为了快速实现聚类,作者使用了构建哈希树的方法,即不停将各个列向量二分类,构建两个叶子节点。之后在叶子节点上递归二分类,继续二分叶子节点,直至每个叶子节点的向量个数小于某个值。
每次对W的列向量二分类的操作如下:
- 随机抽取两个列向量 wi,wj w i , w j ,求两个向量的平均作为分类基准 h=wi+wj2 h = w i + w j 2 ;
- 将每个向量同该分类基准向量作点积 wTih w i T h ,依据点积结果大于0与否将其放到左、右子节点中;
- 当待操作的叶子节点向量个数小于某个值的时候,停止操作。
因为构建每个哈希树存在随机因素,实际使用中可以并行构建多个哈希树,组成森林以提高可靠性。
当给定输入特征x,查找top K类对应的权重向量时,搜索过程从哈希树的根节点开始。每次搜索的时候,x都会和分类基准向量作点积,同样根据结果大于0与否决定选择左节点还是右节点。该过程直到搜索抵达某个叶子节点位置。
Adaptive Allocation
在训练过程中,所搜活跃类的过程中有三个变量需要进行控制:
- 每次搜索活跃类的个数M;
- 构建哈希树的个数L;
- 重新构建哈希森林的间隔迭代次数T。
其中M和L决定了搜索活跃类的可靠性,T的存在是因为权重W在训练过程中也在不停变化。三个变量的选取也决定了算法的速度。作者认为随着网络迭代,模型逐渐趋稳,因此当迭代次数增加时:
- M要满足top M类的概率和大于一个门槛,该门槛线性增加;
- T线性减少;
- L线性增加。
对于一个训练batch,其选取的活跃类是各个输入选取得到的活跃类的集成。
Experiment
作者在几个不同的大型人脸数据集上进行了训练,来验证本文提出方案的有效性。
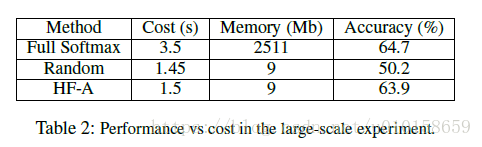
同时也展示了几个重要参数的敏感性。举其中一例,作者在MS-Celeb-1M和Megaface合并的数据集上训练ResNet-101模型进行人脸识别,总类别数达到了75万。其对比结果如下图所示,本文提出的方法较传统训练方法和随机选取“伪”活跃类的方法相比都很大优势:
这篇关于[深度学习论文笔记][AAAI 18]Accelerated Training for Massive Classification via Dynamic Class Selection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



