retrieval专题

Retrieval-based-Voice-Conversion-WebUI模型构建指南
一、模型介绍 Retrieval-based-Voice-Conversion-WebUI(简称 RVC)模型是一个基于 VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)的简单易用的语音转换框架。 具有以下特点 简单易用:RVC 模型通过简单易用的网页界面,使得用户无需深入了

DBeaver 连接 MySQL 报错 Public Key Retrieval is not allowed
DBeaver 连接 MySQL 报错 Public Key Retrieval is not allowed 文章目录 DBeaver 连接 MySQL 报错 Public Key Retrieval is not allowed问题解决办法 问题 使用 DBeaver 连接 MySQL 数据库的时候, 一直报错下面的错误 Public Key Retrieval is
![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)
[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval
引言 今天带来北京智源研究院(BAAI)团队带来的一篇关于如何微调LLM变成密集检索器的论文笔记——Making Large Language Models A Better Foundation For Dense Retrieval。 为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。 密集检索需要学习具有区分性的文本嵌入,以表示查询和文档之间的语义关系。考虑到大语言模

Behavior Retrieval: Few-Shot Imitation Learning by Querying Unlabeled Datasets
发表时间:13 May 2023 论文链接:https://readpaper.com/pdf-annotate/note?pdfId=1900983943467731200¬eId=2446646993511259136 作者单位:Stanford University Motivation:使机器人能够以数据有效的方式学习新的视觉运动技能仍然是一个未解决的问题,有无数的挑战。解决这

论文翻译:Benchmarking Large Language Models in Retrieval-Augmented Generation
https://ojs.aaai.org/index.php/AAAI/article/view/29728 检索增强型生成中的大型语言模型基准测试 文章目录 检索增强型生成中的大型语言模型基准测试摘要1 引言2 相关工作3 检索增强型生成基准RAG所需能力数据构建评估指标 4实验设置噪声鲁棒性结果负面拒绝测试平台结果信息整合测试平台结果反事实鲁棒性测试平台结果 5 结论 摘要

Retrieval-Augmented Generation for Large Language Models A Survey
Retrieval-Augmented Generation for Large Language Models: A Survey 文献综述 文章目录 Retrieval-Augmented Generation for Large Language Models: A Survey 文献综述 Abstract背景介绍 RAG概述原始RAG先进RAG预检索过程后检索过程 模块化RAGMo

Interleaving Retrieval with Chain-of-Thought Reasoning for ... 论文阅读
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions 论文阅读 文章目录 Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-S

Retrieval-Augmented Generation for Large Language Models: A Survey论文阅读
论文:https://arxiv.org/pdf/2312.10997.pdf github:https://github.com/Tongji-KGLLM/ RAG-Survey 简介 大语言模型常常制造虚假事实,在处理特定领域或高度专业化的查询时缺乏知识。例如,当所需信息超出模型训练数据的范围或需要最新数据时,LLM可能无法提供准确的答案。这一限制在将生成型人工智能部署到现实世界的生产

PARTICULAR OBJECT RETRIEVAL WITH INTEGRAL MAX-POOLING OF CNN ACTIVATIONS阅读笔记
不久前看到一篇paper,感觉效果虽然不是特别好,但是对于图像检索和目标识别的后续工作特别有启发意义,所以大致记录一下阅读笔记,以此激励自己学习。 近年来,基于CNN的图像表征已经为图像检索提供了很有效的描述子,超越了很多由预训练CNN模型的到的短向量表示。然而这些方法和模型不适用于几何感知重排,仍然会被一些依赖于精确的特征匹配,几何重排或者查询扩展的传统图像检索所超越。所以本文的工作利用CNN

现代信息检索2-----布尔检索(Boolean Retrieval)
下面我们进入正式的学习,希望这个系列会对自己有用,同样对你也有用!加油…… 布尔检索(Boolean Retrieval),布尔对于我们来说对比较熟悉,就是不是0就是1。顾名思义,布尔检索肯定跟0,1分不开了。剩下的我还是按照ppt顺序,娓娓道来吧。 1.信息检索: Information Retrieval (IR) is finding material (usually docume
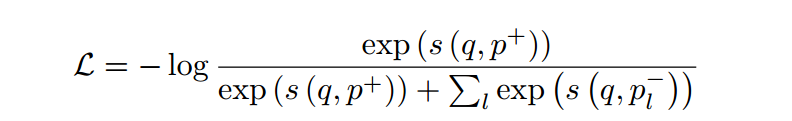
信息检索(36):ConTextual Masked Auto-Encoder for Dense Passage Retrieval
ConTextual Masked Auto-Encoder for Dense Passage Retrieval 标题摘要1 引言2 相关工作3 方法3.1 初步:屏蔽自动编码3.2 CoT-MAE:上下文屏蔽自动编码器3.3 密集通道检索的微调 4 实验4.1 预训练4.2 微调4.3 主要结果 5 分析5.1 与蒸馏检索器的比较5.2 掩模率的影响5.3 抽样策略的影响5.4 解码器

【RAG 博客】Small-to-Big Retrieval
Blog:Advanced RAG 01: Small-to-Big Retrieval ⭐⭐⭐⭐ Code:https://colab.research.google.com/github/sophiamyang/demos/blob/main/advanced_rag_small_to_big.ipynb Small-to-Big Retrieval 技术试图解决这样一个矛盾:更大的

milvus image retrieval
以图搜图 安装部署 sudo docker pull milvusdb/milvus:0.11.0-gpu-d101620-4c44c0 启动 sudo docker run --name milvus_gpu_0.11.0 \-p 19530:19530 \-p 19121:19121 \-v /home/$USER/milvus/db:/var/lib/milvus/db \-v /
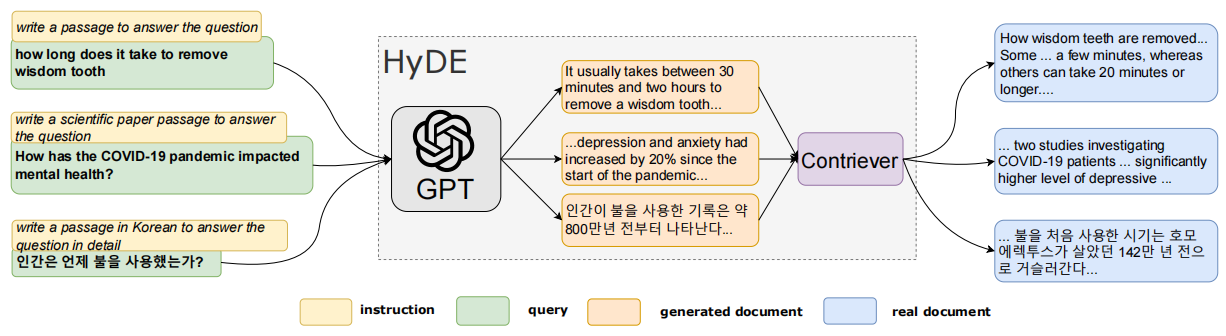
【IR 论文】HyDE:让 LLM 对 query 做查询改写来改进 Dense Retrieval
论文:Precise Zero-Shot Dense Retrieval without Relevance Labels ⭐⭐⭐⭐ CMU, ACL 2023, arXiv:2212.10496 Code: github.com/texttron/hyde 文章目录 论文速读总结 论文速读 在以往的 dense retrieval 思路中,需要对 input quer
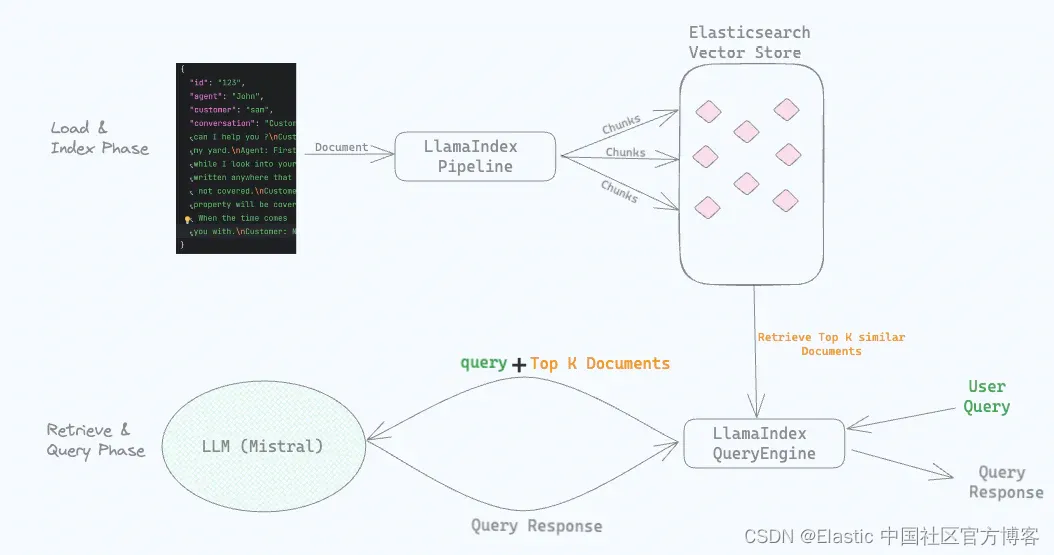
RAG (Retrieval Augmented Generation) 结合 LlamaIndex、Elasticsearch 和 Mistral
作者:Srikanth Manvi 在这篇文章中,我们将讨论如何使用 RAG 技术(检索增强生成)和 Elasticsearch 作为向量数据库来实现问答体验。我们将使用 LlamaIndex 和本地运行的 Mistral LLM。 在开始之前,我们将先了解一些术语。 术语解释: LlamaIndex 是一个领先的数据框架,用于构建 LLM(大型语言模型)应用程序。LlamaIndex

Springboot项目从Nacos读取MySQL数据库配置错误:Public Key Retrieval is not allowed
🌹作者主页:青花锁 🌹简介:Java领域优质创作者🏆、Java微服务架构公号作者😄 🌹简历模板、学习资料、面试题库、技术互助 🌹文末获取联系方式 📝 往期热门专栏回顾 专栏描述Java项目实战介绍Java组件安装、使用;手写框架等Aws服务器实战Aws Linux服务器上操作nginx、git、JDK、VueJava微服务实战Java 微服务实战,Spring
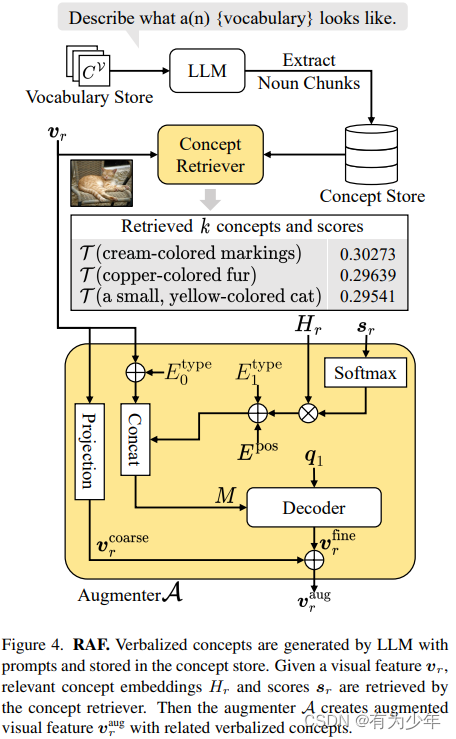
CVPR 2024 | Retrieval-Augmented Open-Vocabulary Object Detection
CVPR 2024 - Retrieval-Augmented Open-Vocabulary Object Detection 论文:https://arxiv.org/abs/2404.05687代码:https://github.com/mlvlab/RALF原始文档:https://github.com/lartpang/blog/issues/13 本文提出了一种新的开放词汇目标检测

解决java项目连接mysql报错~Public Key Retrieval is not allowed
问题产生原因 一般是jdbc连接数据库时出现的场景曾经更换过mysql也可能出现此问题,常见于mysql5.7及8以上版本当禁用 SSL/TLS 协议传输后,客户端会使用服务器的公钥进行传输,默认情况下客户端不会主动去找服务器拿公钥,进而会出现错误。当前用户在服务器端没有登录缓存的情况下,客户端没有办法拿到服务器的公钥。 问题解决 在 JDBC 连接串后加入&allowPublicKeyRe
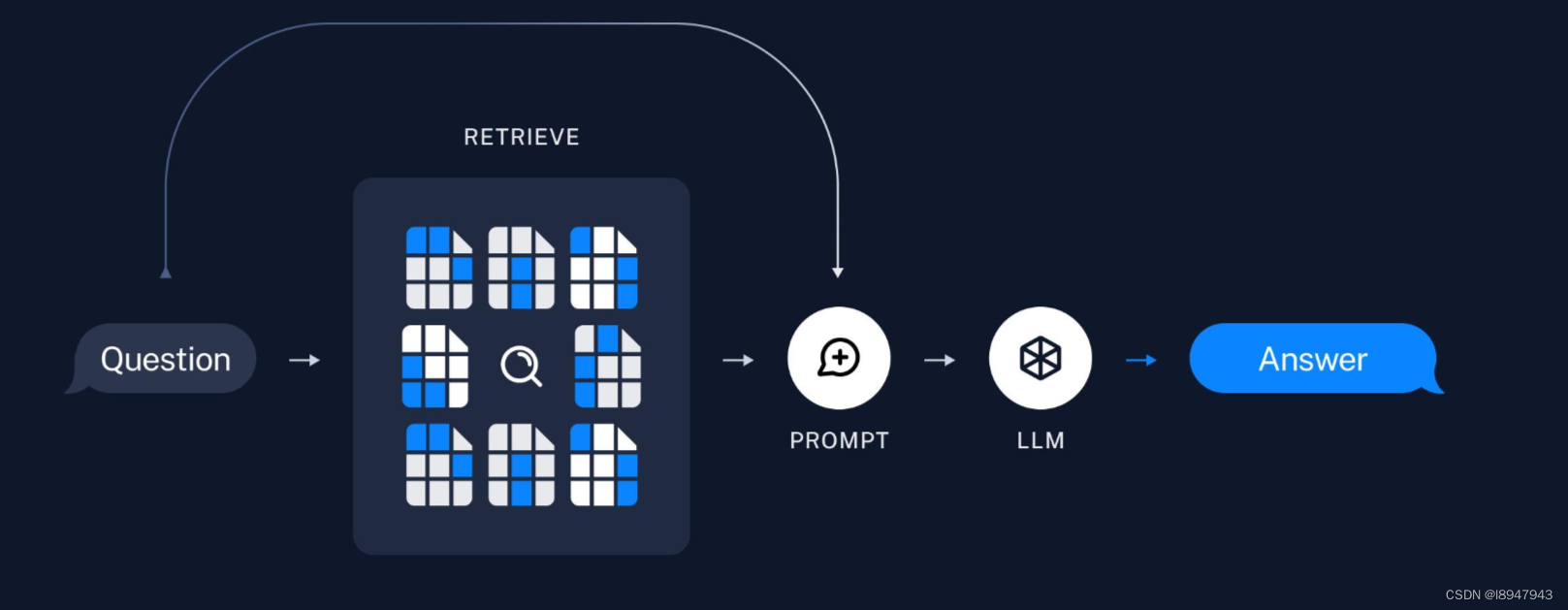
什么是检索增强生成(Retrieval-Augmented Generation,RAG)
什么是RAG? 检索增强生成(Retrieval-Augmented Generation,RAG),是指为大模型提供外部知识源的概念。能够让大模型生成准确且符合上下文的答案,同时能够减少模型幻觉。 用最通俗的语言描述:在已有大模型的基础上,外挂一个知识库,让大模型学习这个知识库后,回答的内容与知识库更为相关,与实际业务场景更加贴切,符合我们的需求。 为什么要用RAG? 模型知识局限
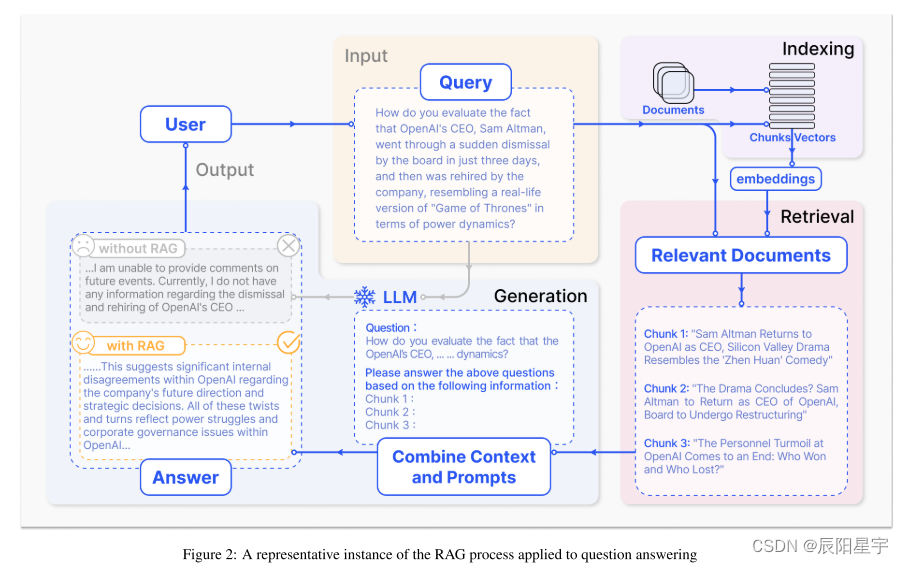
【检索增强】Retrieval-Augmented Generation for Large Language Models:A Survey
本文简介 1、对最先进水平RAG进行了全面和系统的回顾,通过包括朴素RAG、高级RAG和模块化RAG在内的范式描述了它的演变。这篇综述的背景下,更广泛的范围内的法学硕士研究RAG的景观。 2、确定并讨论了RAG过程中不可或缺的核心技术,特别关注“检索”、“生成”和“增强”方面,并深入研究了它们的协同作用,阐明了这些组件如何复杂地协作以形成一个有凝聚力和有效的RAG框架。 3、构建了一个全面的

论文:Term-Weighting Approaches in Automatic Text Retrieval翻译笔记(自动文本检索中的术语加权方法)
文章目录 论文标题:自动文本检索中的术语加权方法摘要1. 自动文本分析2. 词权重规范3. 术语加权实验4 推荐4.1 查询向量4.2 文档向量 论文标题:自动文本检索中的术语加权方法 论文链接:https://www.cs.colostate.edu/~howe/cs640/papers/salton_termWeighting.pdf 在自动文本检索中,术语加权

LangChain核心模块 Retrieval——文档加载器
Retrieval 许多LLM申请需要用户的特定数据,这些数据不属于模型训练集的一部分,实现这一目标的主要方法是RAG(检索增强生成),在这个过程中,将检索外部数据,然后在执行生成步骤时将其传递给LLM。 LangChain 提供了 RAG 应用程序的所有构建模块 - 从简单到复杂。文档的这一部分涵盖了与检索步骤相关的所有内容 - 例如数据的获取。这包含了几个关键模块: Docu

LangChain核心模块 Retrieval——文本分割
Text Splitters 文本分隔 检索的关键部分时仅获取文档的相关部分,主要任务之一是将大文档分割为更小的块。 最简单的例子是,将长文档分割成更小的块,以适合模型的上下文窗口。 LangChain 有许多内置的文档转换器,可以轻松地拆分、组合、过滤和以其他方式操作文档。 理想情况下,希望将语义相关的文本片段保留在一起。“语义相关”的含义可能取决于文本的类型。下面展示了实现此目的的几
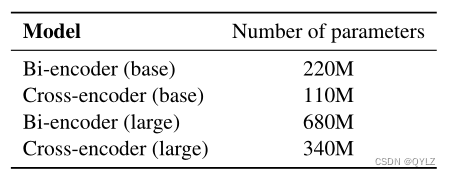
论文:Scalable Zero-shot Entity Linking with Dense Entity Retrieval翻译笔记(实体链接)
文章目录 论文标题:通过密集实体检索实现可扩展的零镜头实体链接摘要1 引言2 相关工作3 定义和任务制定4 方法4.1 双编码器4.2 交叉编码器4.3 知识蒸馏 5 实验5.1 数据集5.2 评估设置和结果5.2.1 零点实体链接5.2.2 tackbp-20105.2.3 WikilinksNED Unseen-Mentions 5.3 知识蒸馏 6 定性分析7 结论A 训练细节和超参数
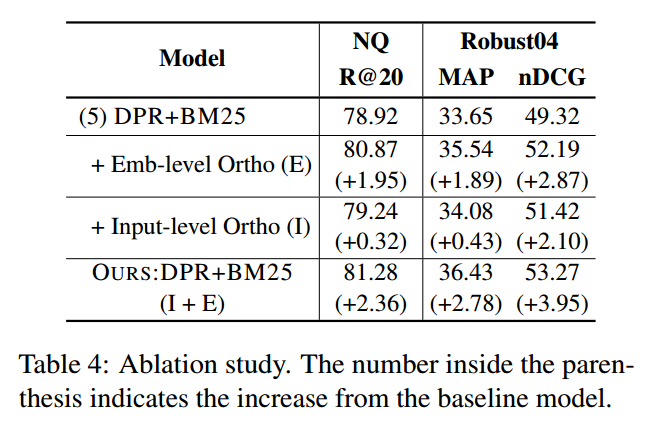
信息检索(十三):On Complementarity Objectives for Hybrid Retrieval
On Complementarity Objectives for Hybrid Retrieval 摘要1. 引言2. 相关工作2.1 稀疏和密集检索2.2 互补性 3. 提出方法3.1 Ratio of Complementarity (RoC)3.2 词汇表示(S)3.3 语义表示(D)3.4 互补目标 4. 实验4.1 实验设置4.2 实验结果4.2.1 RQ1:正交性的有效性4.2
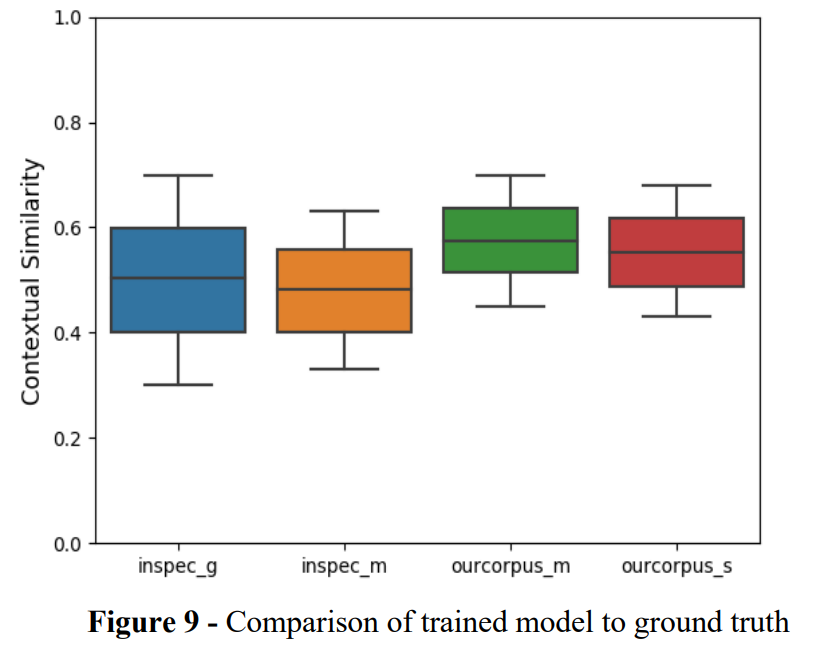
Self-supervised Contextual Keyword and Keyphrase Retrieval with Self-Labelling
文章目录 题目摘要方法数据集实验 题目 通过自我标记进行自我监督的上下文关键字和关键词短语检索 论文地址:https://www.preprints.org/manuscript/201908.0073/v1 项目地址:https://github.com/naister/Keyword-OpenSource-Data 摘要 在本文中,我们提出了一