本文主要是介绍Retrieval-Augmented Generation for Large Language Models: A Survey论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文:https://arxiv.org/pdf/2312.10997.pdf
github:https://github.com/Tongji-KGLLM/
RAG-Survey
简介
大语言模型常常制造虚假事实,在处理特定领域或高度专业化的查询时缺乏知识。例如,当所需信息超出模型训练数据的范围或需要最新数据时,LLM可能无法提供准确的答案。这一限制在将生成型人工智能部署到现实世界的生产环境中构成挑战,可能不够盲目使用黑盒LLM。
-
神经网络通过微调模型以参数化知识来适应特定领域或专有信息。虽然这种技术取得了显著成果,但它需要大量的计算资源,成本高昂,并需要专业的技术专长,使其适应性较差。参数化知识和非参数化知识发挥着不同的作用。参数化知识通过训练LLMs获得,并存储在神经网络权重中,代表了模型对训练数据的理解和概括,构成生成回应的基础。另一方面,非参数化知识存在于外部知识源中,如向量数据库,不直接编码到模型中,而是作为可更新的补充信息。非参数化知识使LLMs能够访问和利用最新或特定领域的信息,提高回应的准确性和相关性。
-
纯参数化的语言模型(LLMs)将从大量语料库中获得的世界知识存储在模型的参数中。然而,这类模型存在局限性。首先,难以保留训练语料中的所有知识,尤其是较不常见和更具体的知识。其次,由于模型参数无法动态更新,参数化知识随时间容易过时。最后,参数的扩展导致训练和推理的计算开销增加。为了解决纯参数化模型的限制,语言模型可以采用半参数化方法,通过将非参数化语料库数据库与参数化模型整合。这种方法被称为检索增强生成(RAG)。
检索增强生成(RAG)这一术语最初由[Lewis et al., 2020]引入。它结合了预训练的检索器和预训练的seq2seq模型(生成器),并进行端到端微调,以更可解释和模块化的方式捕获知识。在大型模型出现之前,RAG主要专注于端到端模型的直接优化。检索方面常见的做法是密集检索,如使用基于向量的密集通道检索(DPR),以及在生成方面训练较小的模型。由于整体参数规模较小,检索器和生成器通常会进行同步的端到端训练或微调。
LLMs仍面临幻觉、知识更新和数据相关问题。将RAG引入大型模型的上下文学习(ICL)中可以缓解上述问题,具有显著且易于实现的效果。在推理过程中,RAG动态地从外部知识源检索信息,使用检索到的数据作为参考来组织答案。这显著提高了回应的准确性和相关性,有效解决了LLMs中存在的幻觉问题。这种技术在LLM问世后迅速受到关注,已成为改善聊天机器人和使LLM更实用的最热门技术之一。通过将事实知识与LLMs的训练参数分离,RAG巧妙地结合了生成模型的强大能力和检索模块的灵活性,为纯参数化模型固有的知识不完整和不足问题提供了有效的解决方案。
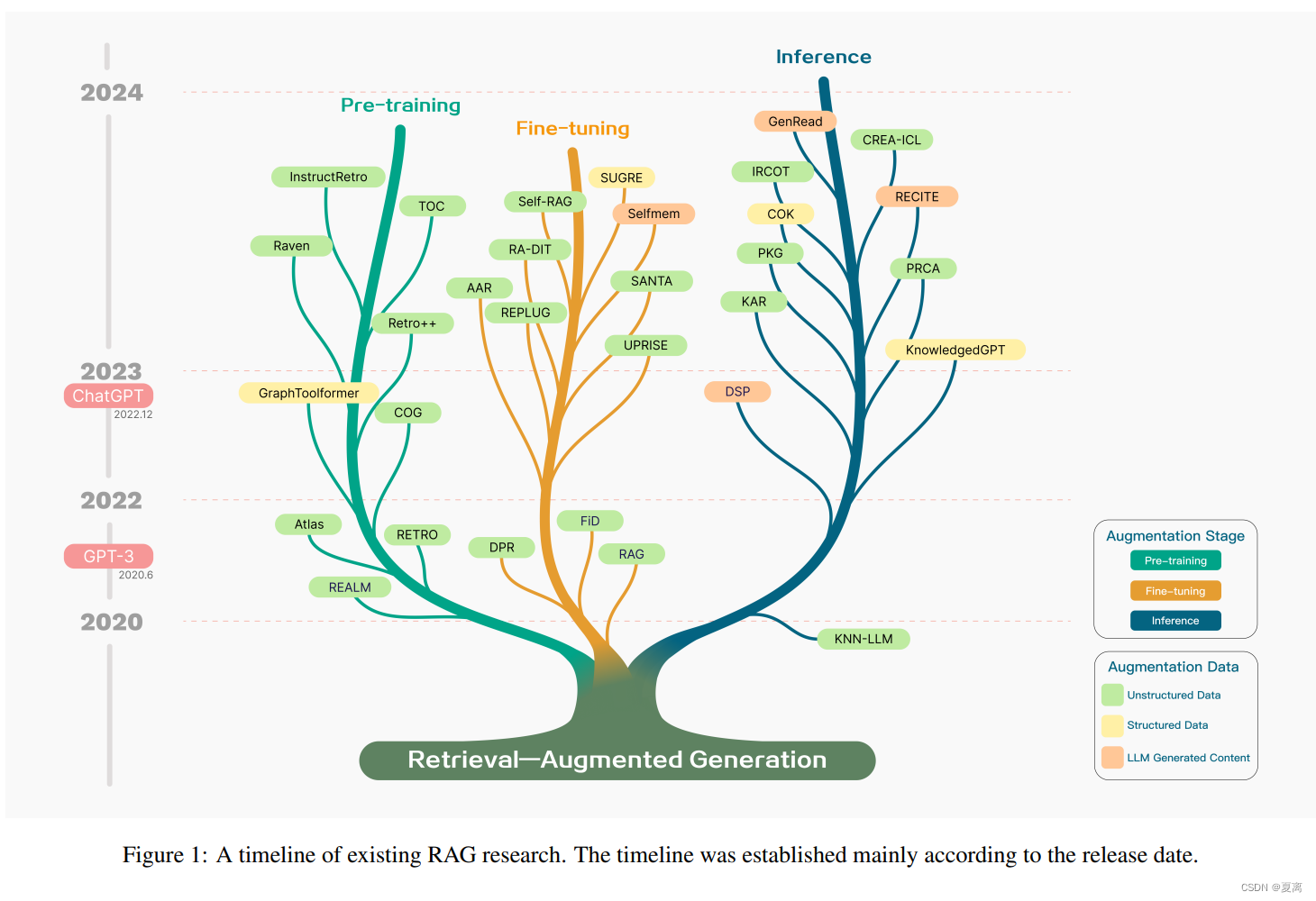
RAG发展脉络图
RAG的两个关键阶段:
- **检索阶段:**在这个阶段,系统会根据用户的问题或查询,从大量的文本文档或知识库中检索出与之相关的信息或上下文。这个过程通常涉及使用信息检索模型如BM25、DPR等来计算查询和文档之间的相似度,然后返回最相关的文档片段。
- **生成阶段:**在这个阶段,系统会利用检索到的相关文档作为上下文,驱动LLM生成回答。
RAG优势:
- RAG通过将答案与外部知识相关联来提高准确性**减少语言模型中的幻觉问题,**并使生成的回答更加准确可靠。
- 使用检索技术可以识别最新的信息。与传统相比语言模型完全依赖于训练数据,RAG保持了响应的及时性和准确性。
- 透明度是RAG的一个优势。通过引用来源,用户可以验证答案的准确性,从而增加对模型输出的信任。
- RAG具有定制功能。通过索引相关的文本语料库,可以针对不同的领域定制模型,为特定领域提供知识支持。
- 在安全和隐私管理方面,RAG凭借其在数据库中内置的角色和安全控制,可以更好地控制数据使用。相比之下,微调后的模型可能缺乏对谁可以访问哪些数据的明确管理。
- RAG的可扩展性更强。它可以处理大规模数据集而无需更新所有参数和创建训练集,从而提高了经济效率。
- RAG产生的结果更值得信赖。RAG从最新数据中选择确定性结果,而微调模型在处理动态数据时可能会出现幻觉和不准确,缺乏透明度和可信度。
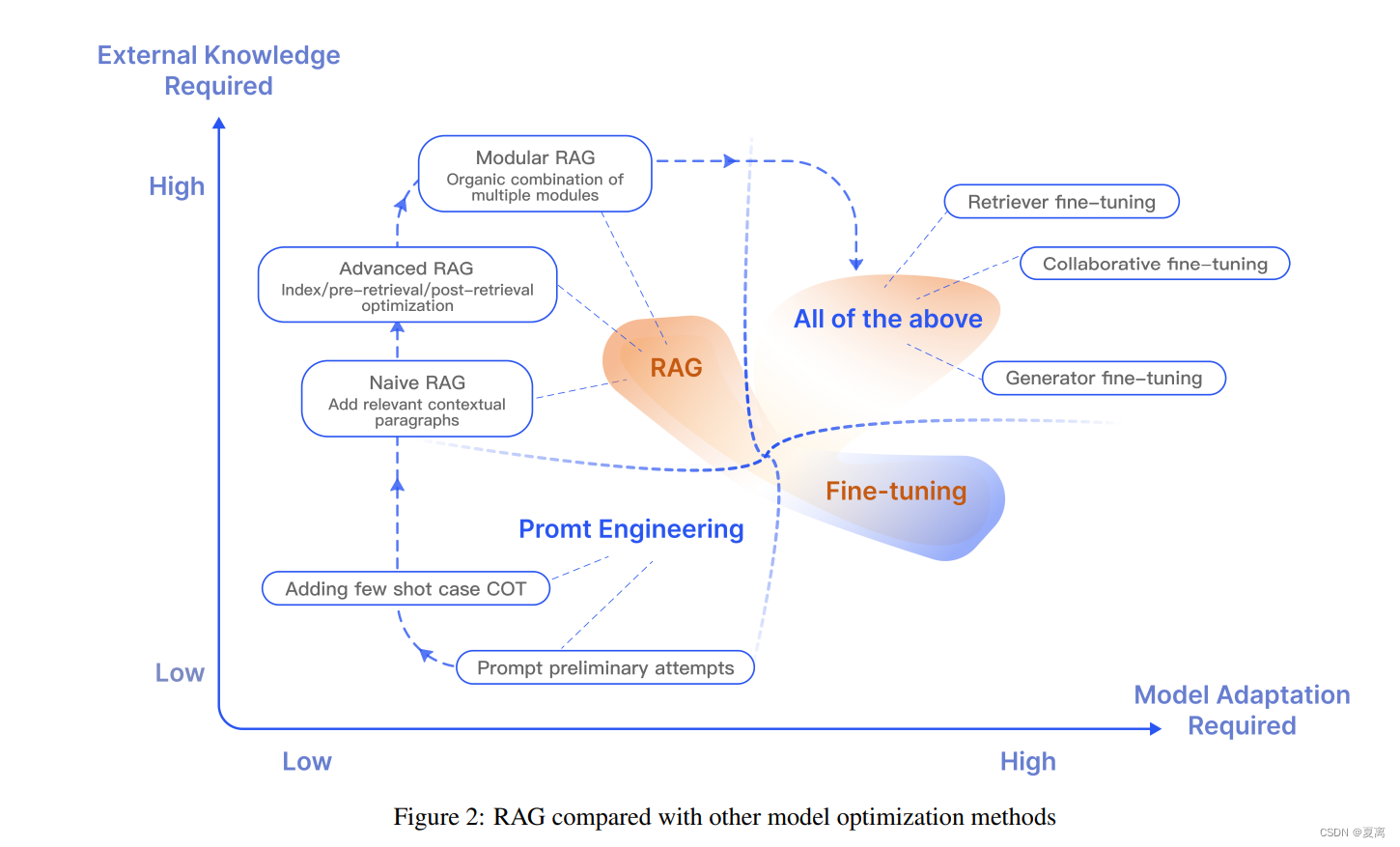
RAG和Finetune对比:

RAG技术
数据索引
索引构建
数据索引的目标是将原始的文本数据转换为可以快速检索的格式。这通常涉及以下步骤:
- 数据清洗:去除文本中无关的信息,如特殊字符、HTML标签等。
- 分块:将清洗后的文本划分为较小的文本块。因为语言模型通常有处理文本长度的限制,所以需要将长文本切分为多个小文本块。
- 嵌入和索引:使用语言模型将文本块编码为向量表示,然后建立索引,将文本块和对应的向量存储为键值对,以便快速检索。
优化索引
- 增加数据粒度:可以对嵌入向量进行聚类,划分为更细粒度的索引,提高检索的精度。
- 优化索引结构:调整分块大小,使用多路径索引,引入图结构等,都可以优化索引的效果。
- 添加元数据:在索引中添加文本的元数据如章节、时间等信息,有助于提高检索的效率。
- 嵌入向量的优化:可以对嵌入向量进行降维、聚类等处理,以减少计算量。
检索
检索在索引构建好后,就可以使用查询文本得到向量,通过计算与索引中向量的相似度来进行检索,找到最相关的文本块。这个阶段也可以应用一些优化技术如重排序、重新检索等。
后处理
检索到的文本块可能需要进一步处理,如去除冗余、提高可读性等,才能用于后续的生成阶段。总体来说,索引构建是RAG中的重要环节,直接影响到检索效果,需要针对具体任务和数据进行多方面的优化。
这篇关于Retrieval-Augmented Generation for Large Language Models: A Survey论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)