sentence专题

Convolutional Neural Networks for Sentence Classification论文解读
基本信息 作者Yoon Kimdoi发表时间2014期刊EMNLP网址https://doi.org/10.48550/arXiv.1408.5882 研究背景 1. What’s known 既往研究已证实 CV领域著名的CNN。 2. What’s new 创新点 将CNN应用于NLP,打破了传统NLP任务主要依赖循环神经网络(RNN)及其变体的局面。 用预训练的词向量(如word2v
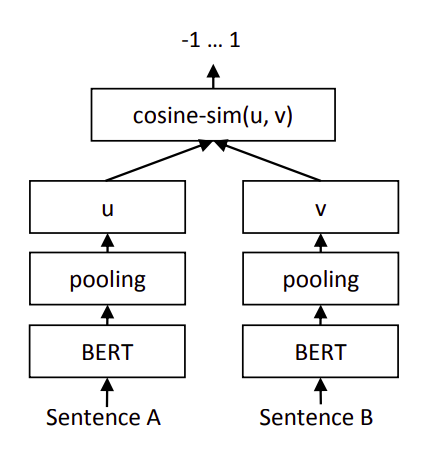
Sentence-BERT实现文本匹配【对比损失函数】
引言 还是基于Sentence-BERT架构,或者说Bi-Encoder架构,但是本文使用的是参考2中提出的对比损失函数。 架构 如上图,计算两个句嵌入 u \pmb u u和 v \pmb v v之间的距离(1-余弦相似度),然后使用参考2中提出的对比损失函数作为目标函数: L = y × 1 2 ( distance ( u , v ) ) 2 + ( 1 − y ) × 1 2

737. Sentence Similarity II
Given two sentences words1, words2 (each represented as an array of strings), and a list of similar word pairs pairs, determine if two sentences are similar. For example, words1 = [“great”, “acting”,
734. Sentence Similarity
Given two sentences words1, words2 (each represented as an array of strings), and a list of similar word pairs pairs, determine if two sentences are similar. For example, “great acting skills” and “f

论文阅读:《Convolutional Neural Networks for Sentence Classification》
重磅专栏推荐: 《大模型AIGC》 《课程大纲》 《知识星球》 本专栏致力于探索和讨论当今最前沿的技术趋势和应用领域,包括但不限于ChatGPT和Stable Diffusion等。我们将深入研究大型模型的开发和应用,以及与之相关的人工智能生成内容(AIGC)技术。通过深入的技术解析和实践经验分享,旨在帮助读者更好地理解和应用这些领域的最新进展 论文地址:http://xueshu
使用 optimum 使得 embedding 生成速度提高 5 倍(和原生 sentence transformer 模型对比)
今天偶然刷到了 Accelerate Sentence Transformers with Hugging Face Optimum (philschmid.de) 看到可以是用 optimum 调用 onnx API 加速 embedding 模型在 CPU 上的推理速度,而且相比之前: 使用 onnx 使得 embedding 生成速度提高 4 倍(和原生 sentence transf

使用 onnx 使得 embedding 生成速度提高 4 倍(和原生 sentence transformer 模型对比)
记录下使用 onnx 提高向量生成速度的过程。复现放在:amulil/vector_by_onnxmodel: accelerate generating vector by using onnx model (github.com)。 结果 OnnxModel Runtime gpu Inference time = 4.52 msSentence Transformer gpu Infe
读论文有感:A Sample But Tough-To-Beat Baseline For Sentence Embedding
该算法有着一定的意义,即通过分析,对Word Embeddings进行加权平均,得到比单纯平均或以TF-IDF为权值的平均向量更好的结果,因计算简单,如作者所述,作为一个更好的Baseline是很好的选择 不过该论文的一些说法有点言过其实,甚至进行了一点小tricks,比如说比supervised 的LSTM有着更好的效果这一说法,有着一定的争议,因为Sentence Embedding实则也是

LibreOffice Calc 取消首字母自动大写 (Capitalize first letter of every sentence)
LibreOffice Calc 取消首字母自动大写 [Capitalize first letter of every sentence] 1. Tools -> AutoCorrect Options2. AutoCorrect -> Options -> Capitalize first letter of every sentenceReferences 1. Tool
Discriminative Information Retrieval for Question Answering Sentence Selection论文笔记
原文下载地址 摘要 该算法提出场景:text-based QA,即给定一段文字说明,提出问题,从文字说明中找出相应答案作答。 text-based QA算法的主要步骤包含三个:1)获取可能包含答案的段落;2)候选段落的重排;3)提取信息选择答案 本文的算法主要是解决第一个步骤 算法 算法主要框架: 预处理:将文字说明切成一

论文A simple but tough-to-beat baseline for sentence embedding
转载自https://blog.csdn.net/sinat_31188625/article/details/72677088 论文原文:A simple but tough-to-beat baseline for sentence embedding 引言 在神经网络泛滥的时候,这篇文章像一股清流,提出了一个无监督的句子建模方法,并且给出了该方法的一些理论解释。通过该方法得到的句子向量

Frequently oral english sentence!
1. I see. 我明白了。2. I quit! 我不干了!3. Let go! 放手!4. Me too. 我也是。5. My god! 天哪!6. No way! 不行!7. Come on. 来吧(赶快)8. Hold on. 等一等。9. I agree。 我同意。10. Not bad. 还不错。11. Not yet. 还没。12. See you. 再见。13. Shut up!
论文笔记:Convolutional Nerual Network for Sentence Classification
Convolutional Nerual Network for Sentence Classification 论文链接:Convolutional Neural Network for Sentence Classification 文中建立了一个一层卷积层和一层全连接层组成的网络,实现文本分类任务。 Introduction 在 Introduction 部分中,开始介绍了一些深度深
Leetcode 2047. Number of Valid Words in a Sentence [Python]
展开了,把不符合条件的全部返回False。细心点就好了。 class Solution:def countValidWords(self, sentence: str) -> int:lst = sentence.split(' ')hyphens = Falseres = 0#print(lst)for part in lst:if part == '':continueif self.che
大型语言模型:SBERT — Sentence-BERT
@slavahead 一、介绍 Transformer 在 NLP 方面取得了进化进步,这已经不是什么秘密了。基于转换器,许多其他机器学习模型已经发展起来。其中之一是BERT,它主要由几个堆叠的变压器编码器组成。除了用于情感分析或问答等一系列不同的问题外,BERT在构建词嵌入(表示词的语义含义的数字向量)方面也越来越受欢迎。 以嵌入的

使用CNN进行句子分类(Convolutional Neural Networks for Sentence Classification)
Yoon Kim在论文(2014 EMNLP) Convolutional Neural Networks for Sentence Classification提出TextCNN。 文章地址:https://arxiv.org/pdf/1408.5882.pdf 以下是翻译内容 摘要: 一个简单的CNN需要很少的超参和静态的vector就能够获得很好的结果,如果将静态的vector改为针对任
FlagEmbedding目前最好的sentence编码工具
FlagEmbedding专注于检索增强llm领域,目前包括以下项目: Fine-tuning of LM : LM-Cocktail Dense Retrieval: LLM Embedder, BGE Embedding, C-MTEB Reranker Model: BGE Reranker 更新 11/23/2023: Release LM-Cocktail, 一种通过模型融合在微调时保
文本匹配之Sentence Bert模型
文章目录 前言Bert句向量表示效果为什么不好?Sentence Bert 原理 前言 目前,对于大部分的NLP任务来说,通过对预训练模型进行微调的方式已经取得了很好的效果,但对于某些特定的场景,我们常常需要的是文本的表示,比如文本聚类,文本匹配(搜索场景)等等; 对于文本匹配任务,在计算语义相似度时,Bert模型需要将两个句子同时进入模型,进行信息交互。 场景一:假如有100
BERT家族:sentence-BERT
sentence-BERT 论文:《Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks》 论文地址:https://arxiv.org/pdf/1908.10084 作者/机构:达姆施塔特工业大学 年份:2019.8 Sentence-BERT主要是解决Bert语义相似度检索的巨大时间开销和其句子表征不适用于非
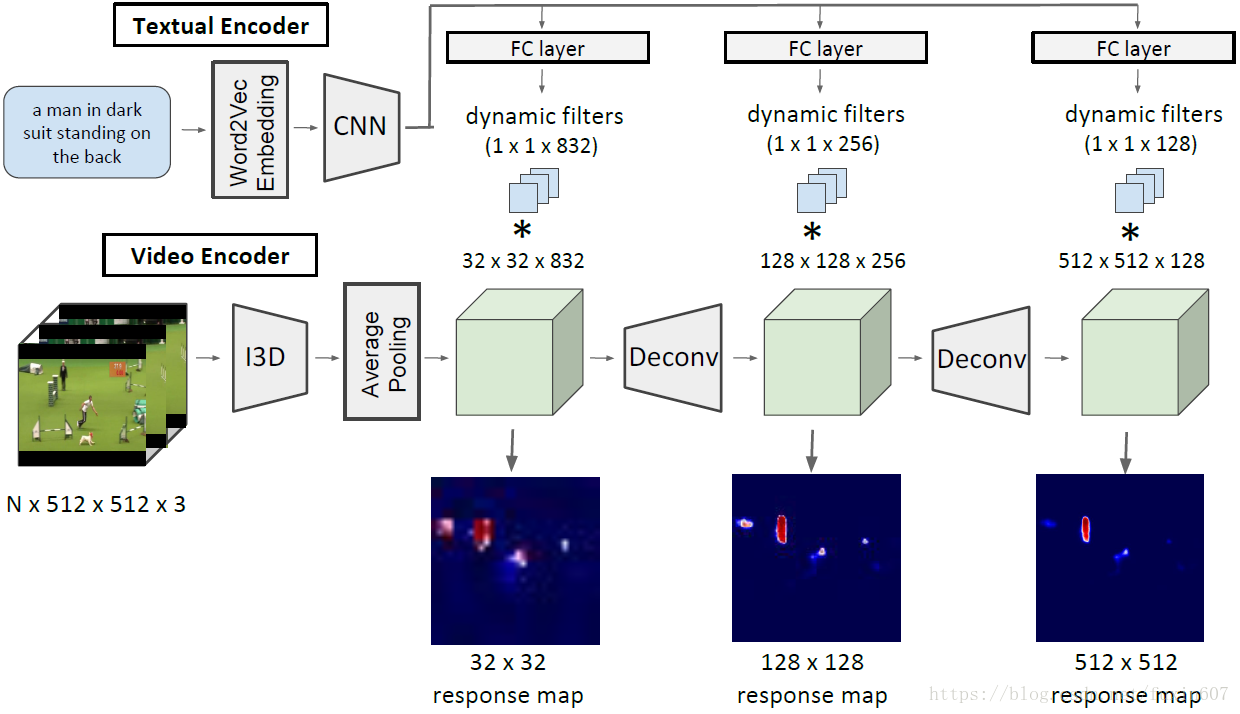
Actor and Action Video Segmentation from a Sentence
CVPR2018 Oral的一篇关于跨媒体(Video与NLP结合)的文章,paper链接 https://arxiv.org/abs/1803.07485,一作是荷兰阿姆斯特丹大学的PHD,作者的homepage https://kgavrilyuk.github.io/,code和datasets还没有被released出来。 个人瞎扯:这是我见过的第一篇发表出来的用NLP做video se

【EMNLP 2019】Sentence-BERT
重磅推荐专栏: 《大模型AIGC》;《课程大纲》 本专栏致力于探索和讨论当今最前沿的技术趋势和应用领域,包括但不限于ChatGPT和Stable Diffusion等。我们将深入研究大型模型的开发和应用,以及与之相关的人工智能生成内容(AIGC)技术。通过深入的技术解析和实践经验分享,旨在帮助读者更好地理解和应用这些领域的最新进展 1. 介绍 在许多NLP任务(特别是在文本语义匹、文本向
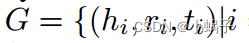
Multi-Aspect Explainable Inductive Relation Prediction by Sentence Transformer
摘要 最近关于知识图(KGs)的研究表明,通过预先训练的语言模型授权的基于路径的方法在提供归纳和可解释的关系预测方面表现良好。本文引入关系路径覆盖率和关系路径置信度的概念,在模型训练前过滤掉不可靠的路径,以提高模型的性能。此外,我们提出了知识推理句子转换器(Knowledge Reasoning Sentence Transformer, KRST)来预测KGs中的归纳关系,KRST将提取的可靠

Distant Supervision for Relation Extraction with Sentence-Level Attention and Entity Descriptions
主要贡献 作者提出了基于句子级别的Attention模型来选择有效的句子。从FreeBase和Wikipedia页面去获取实体描述,从而弥补背景知识不足的缺陷,从而给实体更好的representation。做了很多实验,效果很好。 任务定义 所有句子被分到N组bags中, {B1,B2,⋯,Bi} { B 1 , B 2 , ⋯ , B i } \{ B_1,B_2,⋯,
[论文笔记]Sentence-BERT[v2]
引言 本文是SBERT(Sentence-BERT)论文1的笔记。SBERT主要用于解决BERT系列模型无法有效地得到句向量的问题。很久之前写过该篇论文的笔记,但不够详细,今天来重新回顾一下。 BERT系列模型基于交互式计算输入两个句子之间的相似度是非常低效的(但效果是很好的)。当然可以通过批数据优化,将query和多个待比较句子分别拼接成批大小内的样子一次输入,是可以同时计算批大小个样本之间

sentence similarity vs text (multi-sentence) similarity
1. sentence similarity 1.1 方法列举 BERT Universal Sentence Encoder ELECTRA embedding 1.2 介绍 1.2.1 BERT With the advancement in language models, representation of sentences into vectors has been getti
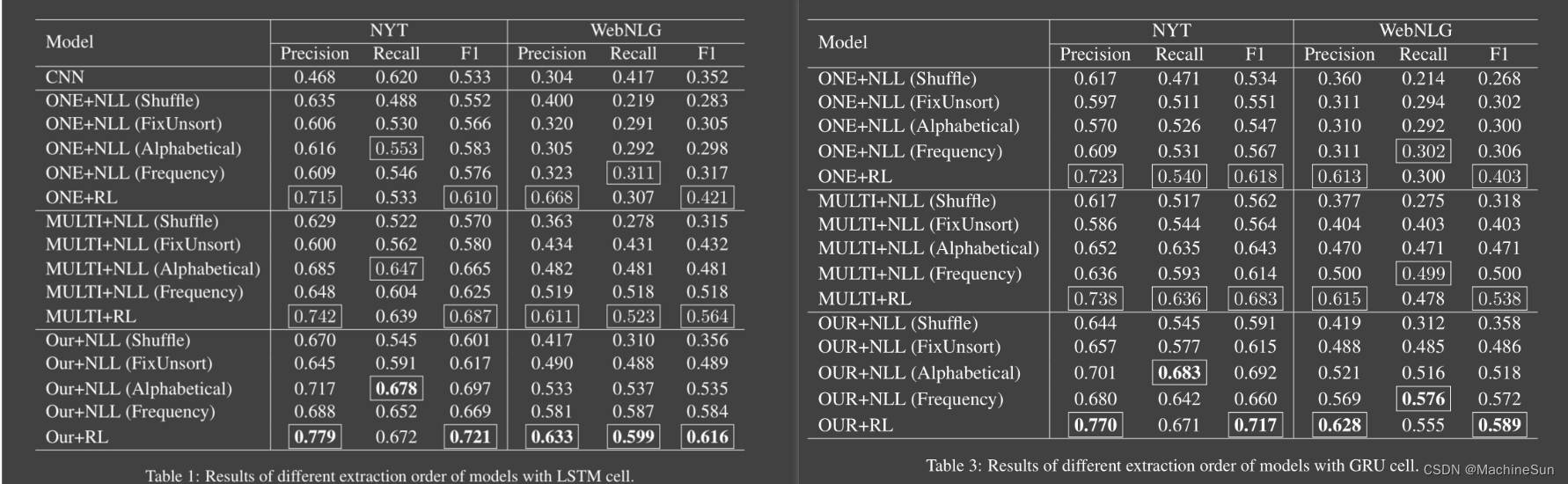
Learning the Extraction Order of Multiple Relational Facts in a Sentence with Reinforcement Learning
Abstract 现有的方法中没有考虑到相关事实的提取和整理,多重关系提取任务尝试从句子中提取所有关系事实,本文认为提取顺序在此任务中至关重要,为了考虑提取顺序,文本将强化学习应用到Seq2Seq模型中,所提出的模型可以自由生成关系事实。 model 通过双向RNN对句子进行编码,再通过另一个RNN逐个生成三元组,当所有有效的三元组生成后,解码器将生成NA三元组。 在时间步长t中,需要