本文主要是介绍文本匹配之Sentence Bert模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- Bert句向量表示效果为什么不好?
- Sentence Bert 原理
前言
目前,对于大部分的NLP任务来说,通过对预训练模型进行微调的方式已经取得了很好的效果,但对于某些特定的场景,我们常常需要的是文本的表示,比如文本聚类,文本匹配(搜索场景)等等;
对于文本匹配任务,在计算语义相似度时,Bert模型需要将两个句子同时进入模型,进行信息交互。
场景一:假如有10000个句子,找出最相似的句子对。
Bert模型需要计算(10000*9999/2)次,非常耗时,大约需要65个小时。而对Sentencebert模型来说,10000个句子只需要计算10000次获得自己的embedding,大约只需要5秒,进行余弦相似度计算的时间相比模型运行的时间可以忽略不计,大约需要5秒就可以完成,
5秒相比于65小时,这就是表示型和交互型的恐怖差距。
场景二:用户提出问题,将问题与数据库中的标准问题进行相似度计算,找到最相似的标准问。
Bert模型需要将用户问题与所有的标准问都计算一遍,效率非常低,而SentenceBert模型可以预先将标准库中的问题预先离线编码好,得到句向量,来新的问题(查询)后,只需要对新的问题进行编码就可以了,会大大提升效率。
Sentence Bert论文地址:
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
代码链接:
https://www.sbert.net/docs/pretrained_models.html
https://github.com/UKPLab/sentence-transformers
数据集:哈工大开源的LCQMC数据集,共20+w条数据;
评估指标:
- Spearman Rank Correlation,测试单调关系
- Pearson Rank Correlation,用来测试线性关系
建议使用 Spearman Rank Correlation。
Bert句向量表示效果为什么不好?

由上图可见,Bert的CLS向量表示效果并不好。
原因:
Bert 的向量空间是各向异性的,且词嵌入呈现锥形分布,高频词聚集在锥头部,低频词分散在尾部,又由于高频词本身是高频的,因此会主导句子表示。
词频影响词向量空间的分布,高频词与原点的L2距离更近,更接近原点;

低频词分布更加稀疏,(度量词空间中与K近邻单词的L2距离的均值,可以发现高频词更加集中,低频词更加稀疏)

还有一种原因就是,一般用于计算文本相似度的方法是cosine similarity,公式如下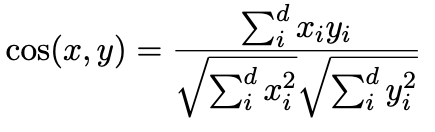
上式的计算是要保证向量的基底是标准正交基,因此如果是非标准正交基,计算结果就会不具代表性(不准确)。
Sentence Bert 原理
Bert 模型输出句向量的方式有两种,一种是取CLS表示句向量,一种是对token_embedding做池化(平均池化/最大池化),当然还可以取不同的层进行池化(最后一层,后两层,第一层和最后一层),当然,常用的是取最后一层的平均池化。句向量做相似度计算的效果并不好,但roberta的句向量是要比bert的句向量的表示好一些的。
通常使用的损失函数为cross_entropy,可以考虑将目标函数改为cosine similarity,使得[CLS]的值就是为计算cosine similarity来服务的。论文中提出了三种方法:
第一种方法:把单个Bert改成孪生网络的结构,虽然是两个部分,但是权重是共享的,分别输入两个句子,得到对应的CLS值,即图中的 u, v,然后把 u, v, |u - v| 进行拼接,再经过 softmax 进行分类。这种方法支持两种任务:NLI任务(三分类),STS任务(二分类)。

第二种方法是输出的 u 与 v 需要计算cosine similarity,最后损失函数换成了平方损失函数。这种方法只适用STS任务。

第三种方法是将损失函数换成hinge loss的方法,a表示原句,p表示正例,n表示负例,目标就是让原句与正例的差别要比原句与负例的差别大于设定的阈值。在论文中,距离度量为欧式距离,边距大小为1。
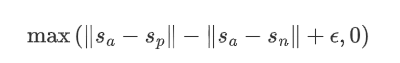
参考:https://blog.csdn.net/u012526436/article/details/115736907?spm=1001.2014.3001.5501
https://zhuanlan.zhihu.com/p/113133510
https://www.sbert.net/docs/training/overview.html
https://zhuanlan.zhihu.com/p/351678987
这篇关于文本匹配之Sentence Bert模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







