discriminative专题
车道线分割项目记录-Discriminative_loss
目录 一、损失函数原理 1. L_var 2. L_dist 二、代码 一、损失函数原理 主要是看明白了每个符号代表的意思就能明白了。 1. L_var L_var是方差损失,也就是一条车道线的像素点之间的方差越小越好。上面的式子中,前面两个求和以及1/C,1/N,就是为了平均这个损失值,取所有的车道线,再取所有的像素点,计算完了对所有车道线以及所有像素点求均值。

Learning Discriminative Features with Multiple Granularities for Person Re-Identification 论文学习
Abstract 将全局和局部特征结合已经成为提高行人重识别任务表现的关键方案。以前的基于局部特征的方法主要是利用预先定义的语义信息来定位区域,学习局部表征,这增加了学习难度,且对复杂场景来说其鲁棒性和效率都差一些。本文提出了一个端到端的特征学习策略,用多样化的细粒度来集成判别信息。作者仔细设计了 Multiple Granularity Network,它是一个多分支的深度网络结构,一个分支用
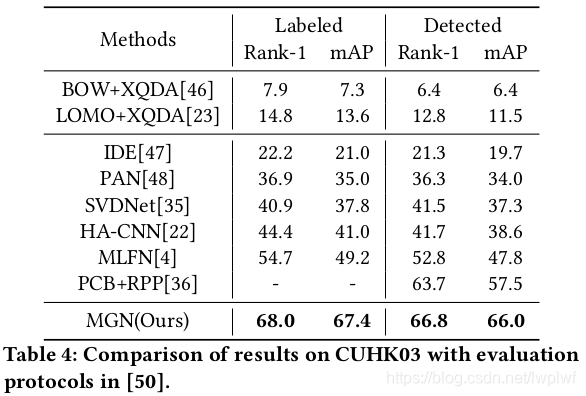
论文笔记2 --(ReID) Learning Discriminative Features with Multiple Granularities for Person Re-id
https://github.com/lwplw/reid-mgn https://github.com/lwplw/reid-mgn/tree/master/pytorch_MGN 论文:https://arxiv.org/pdf/1804.01438.pdf GitHub:https://github.com/lwplw/reid-mgn/tree/master/pytorch_MGN

CAM论文笔记--Learning Deep Features for Discriminative Localization
CAM:Learning Deep Features for Discriminative Localization 背景 论文主要针对图片中不同类别物体定位的弱监督学习问题,提出了基于分类网络的图片识别与定位。 分类网络如VGGnet和Alexnet等基本由卷积操作对图片的特征进行提取,在网络末端使用全连接层进行信息综合和分类。在监督学习中,分类问题需要带类别标签的数据集,定位问题需
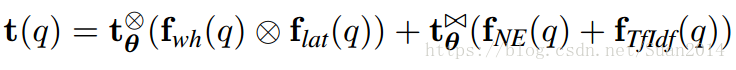
Discriminative Information Retrieval for Question Answering Sentence Selection论文笔记
原文下载地址 摘要 该算法提出场景:text-based QA,即给定一段文字说明,提出问题,从文字说明中找出相应答案作答。 text-based QA算法的主要步骤包含三个:1)获取可能包含答案的段落;2)候选段落的重排;3)提取信息选择答案 本文的算法主要是解决第一个步骤 算法 算法主要框架: 预处理:将文字说明切成一

CVPR 2023: Cross-Domain Image Captioning with Discriminative Finetuning
基于MECE原则,我们可以使用以下 6 个图像字幕研究分类标准: 1. 模型架构 编码器-解码器模型:这些传统的序列到序列模型使用单独的神经网络来处理图像和生成字幕。编码器,通常是卷积神经网络(CNN),从图像中提取视觉特征。解码器,通常是循环神经网络(RNN)如 LSTM,然后逐字生成字幕,条件是编码后的图像特征。这是早期作品如 Show and Tell [44] 和 VGG+LSTM
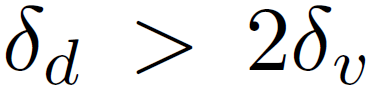
Semantic Instance Segmentation with a Discriminative Loss Function
1、优点 1)不依赖proposal,避免了detect-and-segment方法的弊端,有利于遮挡物体的检测 2)擅长区分高度相似的物体(不擅长形态各异的物体) 2、方法 1)pixel embedding(语义分割框架) 预测每个pixel处的representation(n维向量),使得同一个instance的向量距离较近,不同in
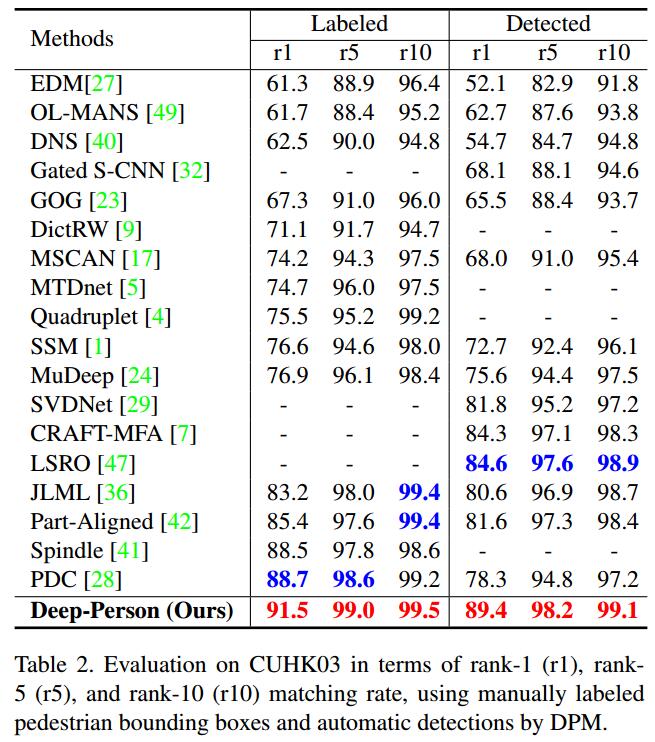
【Person Re-ID】Deep-Person: Learning Discriminative Deep Features for Person Re-Identification
paper下载地址:https://arxiv.org/abs/1711.10658 Introduction 基于CNN方法的person re-id方法可以分为三类: 基于全局描述的方法基于局部描述的方法结合全局描述和局部描述的方法 局部描述能够提取行人的一些细节信息,在大多数试验中都能比单独用全局描述的方法要好。通常的做法是将新人图像分割成几个rigid的块,然后每个块分别进行分类。

Adversarial Discriminative Heterogeneous Face Recognition阅读笔记
Lingxiao Song, Man Zhang, Xiang Wu, Ran He AAAI-18 一、简介 不同人脸模式的感知模式之间的差距在异质人脸识别中仍是一个具有挑战性的问题(HFR)。图像对在大多数数据库中没有准确对齐,即使我们可以根据面部的位置标记对图像进行对齐,同一对象的姿势和面部表情仍然有很大的差异。 本文提出了一种基于原始像素空间(raw-pixel space)和紧致特
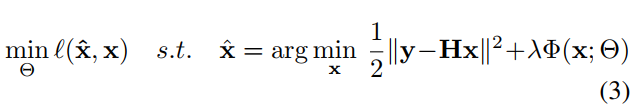
model based optimize? discriminative learning?有何区别?
如题,究竟有何区别呢?在看图像复原(超分)的论文IRCNN(Image Restoration by Convolution Neural Network)的时候,有所领悟哈,觉得写的很明白,只可意会,不可言传,翻译如下: 首先,明确两个英文单词: matrix : 矩阵 matrices: matrix的复数形式,多个矩阵 The model based optimization

Learning Deep Features for Discriminative Localization 笔记2
作者:Dr.Frankenstein 链接:https://www.zhihu.com/question/67987641/answer/258570104 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 不知道用文科生的视角解读是不是意味着不能再中英混杂装逼了……anyway。本文的动机如下:曾经有人提出过一个方法叫做global average pool

论文阅读-《Learning Deep Features for Discriminative Localization》
转自:http://blog.csdn.net/yaoqi_isee/article/details/62214648 收录于CVPR2016 关于全连接层不能保持spatial information的理解 相比全连接层,卷积层是一个spatial-operation,能够保持物体的空间信息(translation-variant)。比如一个物体原来在左上角,卷积之后的结果feature-m

Manifold regularized discriminative feature selection for multi-label learning(基于流式正则化判别多标记学习的特征选择)
论文大纲: 背景特征选择的方法详细介绍MDFS方法实验结果分析讨论和结论 背景: 在多标签学习中,对象本质上与多个语义相关,数据类型同时面临高特征维数的影响,如生物信息学和文本挖掘等应用。为了解决学习问题,提出了特征选择这一关键技术来降低维数,而以往的多标签特征选择方法大多是从传统的单标签特征选择方法中直接转化而来的,或者是在标签信息的开发过程中半途而废,从而导致了多标签特征

【论文阅读】Multi-instance Learning with Discriminative Bag Mapping
基本信息 · 题目:Multi-instance Learning with Discriminative Bag Mapping · 会议:IEEE 摘要 目前,通过选择一个实例将一个包转化为一个新空间中的单个实例,主要是基于原始空间。但是基于原始空间的映射有一些缺陷,如:难以保证所选实例的识别能力。因此,允许一组实例共享一个标签,是解决学习中标签歧义问题的有效工具。本文提出了一种用于多
【补充知识】生成模型(generative model)和判别模型(discriminative model)、贝叶斯学派和概率学派
看到过好几次“生成模型”这个词了,一直不太懂,这次买了李航老师的《统计学习方法》看一下。 统计学习分类: 基本分类: 监督学习(supervised learning):从标注数据中学习预测模型的机器学习问题 概念:输入空间、输出空间、特征空间(有时候不区分于输入空间),联合概率分布(P(X,Y)),假设空间(X→Y的映射集合) 无监督学习(unsupervised learning):

CSR-DCF(Discriminative Correlation Filter with Channel and Spatial Reliability) 文章分析(一)
CSR-DCF(Discriminative Correlation Filter with Channel and Spatial Reliability) 文章分析(一) 目录 DCF框架带来的问题本文针对上述问题的改进Spatially constrained correlation filtersConstructing spatial reliability mapConstra