本文主要是介绍【Person Re-ID】Deep-Person: Learning Discriminative Deep Features for Person Re-Identification,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
paper下载地址:https://arxiv.org/abs/1711.10658
Introduction
基于CNN方法的person re-id方法可以分为三类:
基于全局描述的方法
基于局部描述的方法
结合全局描述和局部描述的方法
局部描述能够提取行人的一些细节信息,在大多数试验中都能比单独用全局描述的方法要好。通常的做法是将新人图像分割成几个rigid的块,然后每个块分别进行分类。这样的做法带来的弊端就是忽略了块与块之间的上下文信息,本文通过LSTM将图像看成是一个输入序列来记录行人的结构信息,然后用joint learning的方法将这种局部描述与全局描述结合起来。
Approach
主网络采用resnet-50,网络结构如下图所示,包括两方面的设计:
全局描述和局部描述的结合:全局描述和基于LSTM的局部描述能够增强网络的判别性。
基于softmax的分类loss和基于triplet的排序loss的结合:triplet loss帮助网络学习相似性度量(L2距离)。
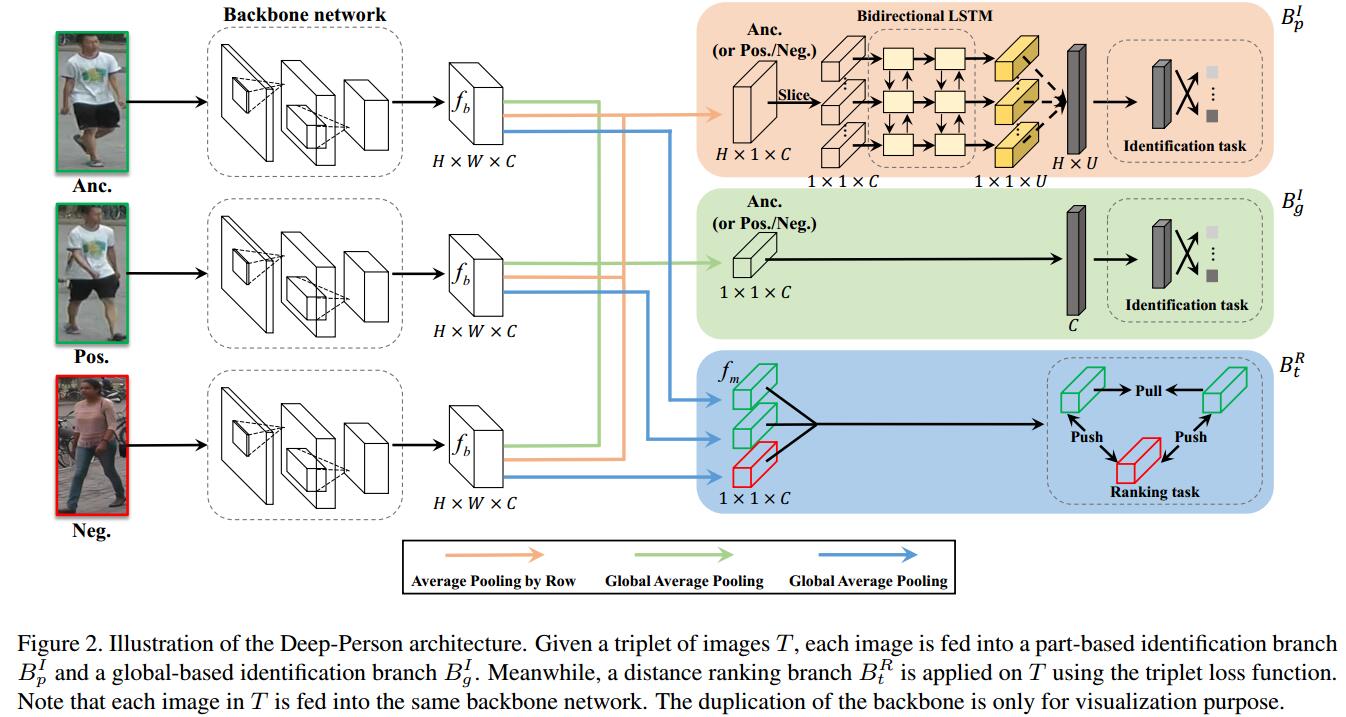
网络主要包括两个部分:
主网络学习low-level特征
三个分支网络学习具有高度可分性的描述子,分别为
- 基于局部描述的识别分支:将resnet-50最后一个卷积层的输出特征横向pooling做成一个sequence输入到双向LSTM中。
- 基于全局描述的识别分支:将resnet-50最后一个卷积层的输出特征global pooling进行分类。
- 基于triplet的排序分支:输入三元组,将resnet-50最后一个卷积层的输出特征global pooling求取triplet loss。
Experiment
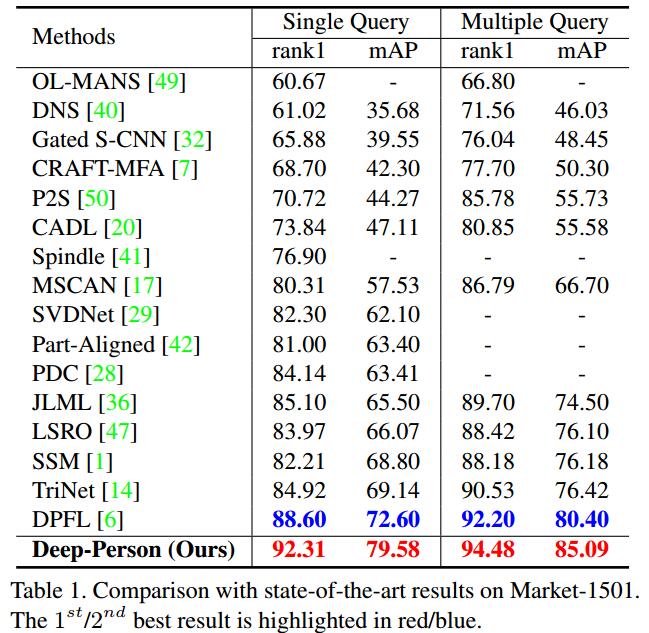
Evaluation on Market-1501
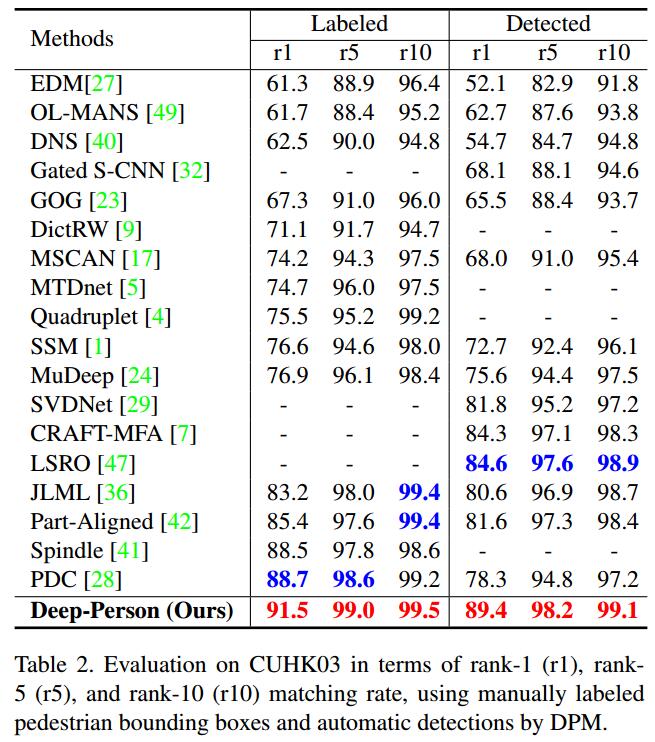
Evaluation on CUHK03
这篇关于【Person Re-ID】Deep-Person: Learning Discriminative Deep Features for Person Re-Identification的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






