本文主要是介绍Adversarial Discriminative Heterogeneous Face Recognition阅读笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Lingxiao Song, Man Zhang, Xiang Wu, Ran He
AAAI-18
一、简介
不同人脸模式的感知模式之间的差距在异质人脸识别中仍是一个具有挑战性的问题(HFR)。图像对在大多数数据库中没有准确对齐,即使我们可以根据面部的位置标记对图像进行对齐,同一对象的姿势和面部表情仍然有很大的差异。
本文提出了一种基于原始像素空间(raw-pixel space)和紧致特征空间( compact feature space)的对抗性特征学习框架,通过对抗性学习来缩小感知差距。该框架将交叉光谱的人脸幻觉 和 鉴别特征学习集成到端到端对抗性网络中。
在像素空间中,我们利用生成的对抗性网络来实现交叉光谱的人脸幻觉。并提出了一种复杂的双路径模型,该模型既考虑了全局结构,又考虑了局部纹理,从而缓解了图像配对不足的问题。
在特征空间中,分别用一个对抗性损失和一个高阶方差差异损失来度量两个异质分布之间的全局和局部差异。这两种损失增强了域不变特征学习和模态无关噪声去除。
二、模型
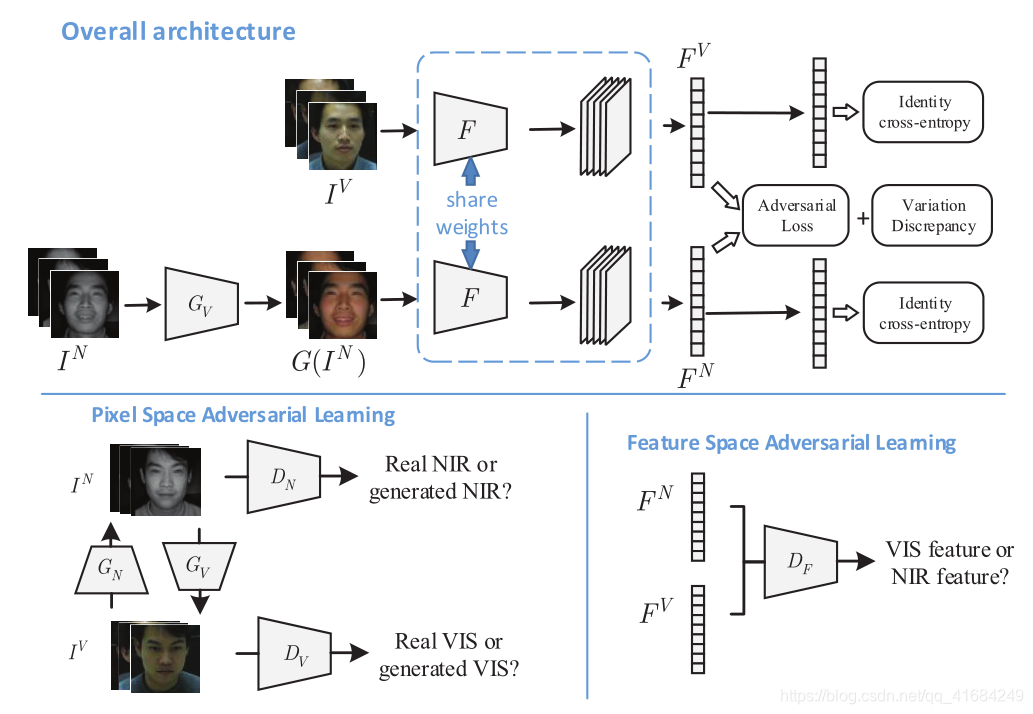
Cross-spectral Face Hallucination部分,先通过GAN网络将NIR图像生成VIS图,在生成过程中,将人脸与眼睛分别生成再合并,精确地恢复眼周区域的细节,生成效果更好,再生成的图片由RGB转化到YCbCr 再与原始输入图的NIR图像作LI loss。
Adversarial Discriminative Feature Learning部分,将生成的VIS图像与原始数据集的VIS图像分别提取特征,输入给判别器DF,这个判别器的作用是判别是不是RGB图像,进一步对生成的VIS图像进行处理,再通过类间方差差异CVD对标签(类别)进行指导,确保同一类别的一致性,最后通过交叉熵损失进行分类。
Cross-spectral Face Hallucination(跨光谱脸部幻觉):
NIR-VIS图像转换中的一个主要挑战是大多数数据库中的图像对不能精确对齐。尽管我们可以根据面部地标对齐图像,但同一对象的姿势和面部表情仍然有很大的不同。
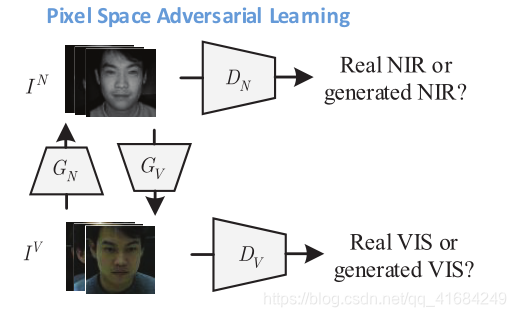
引入了一对GV: IN→IV和GN: IV→IN实现相反的变换,这样我们就可以构建VIS和NIR域之间的映射循环。同时,通过DV和DN进行判别,其得分越接近1则越真。

单个生成器很难合成出高质量的交叉光谱图像,同时全局结构和局部细节都得到了很好的重建。一种可能的解释是,卷积滤波器在所有空间位置之间共享,这很少适合于同时恢复全局和局部信息。
生成部分采用two-stream结构,由于近红外图像与其他面部区域的VIS图像之间存在特殊的对应关系,我们在眼睛周围增加了一条stream,以精确地恢复眼周区域的细节。
Adversarial Discriminative Feature Learning(对抗性辨别特征学习):
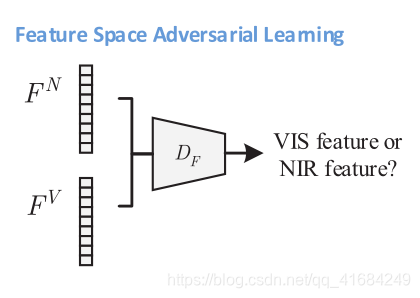
一个额外的鉴别器DF用于鉴别特征,数据输出是一个标量值,表示属于VIS空间的概率。
三、损失函数
3.1 跨光谱脸部幻觉损失:

同时加入cycleGAN的思路来保证输入图像和重建图像之间的一致性。本实验中。先将VIS图像转换为NIR图像,然后再将NIR图像转换为VIS图像。

由于可见光图像和近红外图像主要在光谱上存在差异,因此在进行跨光谱转换后需要保留结构信息。在全局路径中采用了一个保持一致性的权限来加强结构一致性。
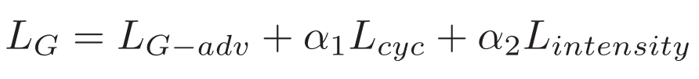
3.2 对抗性辨别特征学习损失
Adversarial Loss(对抗损失):
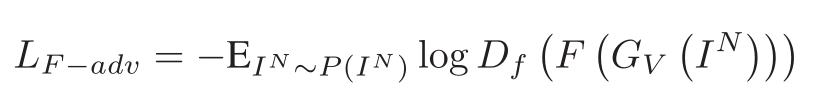
通过加强近红外特征分布与可见光特征分布的拟合,可以去除导致区域差异的噪声因素。由于对抗损失用于消除全局视图中异构数据分布之间的差异,而不考虑局部差异,并且每个模态中的分布由不同主题的许多子分布组成,因此局部一致性可能无法很好地保持。
Variance Discrepancy(类间方差):
Adversarial loss只能处理由模态转移引起部分人的内部差异,而不能处理与模态无关的因素。所以加入了类间方差差异(CVD),在标签的指导下,确保同一类别的一致性。

Cross-Entropy Loss:
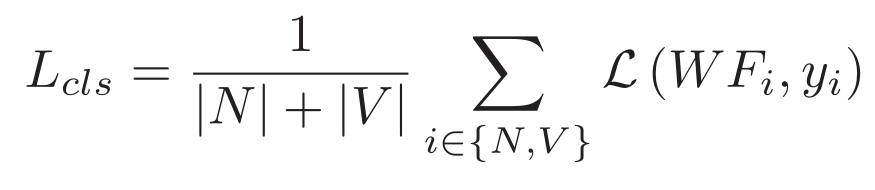
最后通过交叉熵损失,对不同模态的特征进行分类。
总的损失:
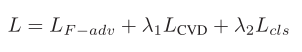
四、实验
CASIA NIR-VIS 2.0:

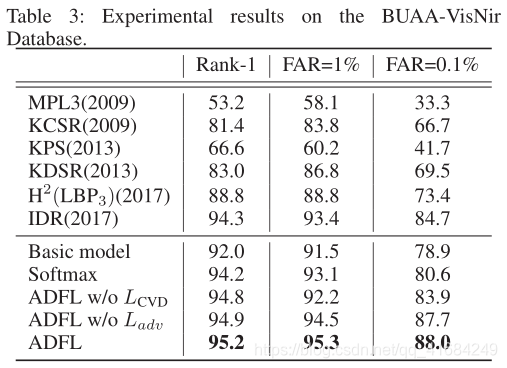
BUAA-VisNir:
Oulu-CASIA NIR-VIS:

这篇关于Adversarial Discriminative Heterogeneous Face Recognition阅读笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








