本文主要是介绍CVPR 2019 Progressive Attention Memory Network for Movie Story Question Answering,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
动机
-
人类具有先天的认知能力,可以从不同的感觉输入中推断出5W和1H的问题,这些问题涉及who,what,when,where,why以及how,在机器上复制这种能力一直是人类的追求。 近年来,关于问题回答(QA)的研究已成功地受益于深度神经网络,并显示出对textQA,imageQA,videoQA的显着改进。
-
本文考虑了电影故事QA ,旨在通过观察与时间对齐的视频和字幕后回答有关电影内容和故事情节的问题,来共同理解视觉和语言。 与VQA相比,电影故事问答具有两个方面的挑战性:
(1)精确定位与电影故事问答相关的时间部分,因为电影通常长于一小时;
(2)电影故事问答既有视频又有字幕,不同的问题需要不同的模态来推断答案。
-
电影故事问答的第一个挑战是,它涉及的长视频可能超过一个小时,这阻碍了精确定位所需的时间部分。回答问题所需的电影中的信息不是在时间轴上均匀分布的。为了解决这个问题,memory网络在QA任务中已被广泛接受。attention机制被广泛地用于检索与问题相关的信息。作者观察到记忆网络上的单步attention常常产生模糊的时间attention映射。
-
电影故事问答的第二个挑战是它同时涉及视频和字幕,不同的问题需要不同的模态来推断答案。每种模态都可以为不同的问题传达基本的信息,将它们最佳地融合是一个重要的问题。在电影《Indiana Jones and the Last Crusade》中,“What does Indy do to the grave robbers at the beginning of the movie?”这一问题需要视频形式而不是字幕形式,而“How has the guard managed to stay alive for 700 years?”这一问题则需要字幕形式。现有的多模态建模方法只关注模态之间丰富的相互作用的建模。然而,这些方法都是问题无关的,因为融合过程不涉及问题。
方法
简介
针对上述问题,本文提出了用于电影故事问答的渐进attention memory网络(PAMN)。PAMN包含三个主要特征;(1)用于精确定位被查询时间部分的递进attention机制;(2)用于自适应地融合基于问题和条件的模态的动态模态融合;(3)置信度修正回答方案。递进式attention机制利用了出自问题和答案的线索为每个memory修剪掉不相关的时间部分。在反复地获取问题和答案以产生时间attention的同时,记忆逐渐更新以积累线索来定位回答问题的相关时间部分。与堆叠的attention相比,渐进式attention在单个框架中考虑多个源(例如Q和A)和多个目标(例如视频和字幕memory)。动态模态融合通过自适应地确定每个模态的贡献来聚合每个memory的输出。在当前问题条件下,通过soft attention机制获得贡献。用双线性运算融合多模态数据往往需要较重的计算量或大量的参数。动态模态融合通过丢弃不必要的模态中的无价值信息,有效地将视频和字幕模态融合在一起。置信度修正答题方案依次修正每个候选答案的选择单词前得分。当人类解决问题时,他们通常以迭代的模态多次阅读内容、问题和答案。这种观察是用置信度修正回答方案建模的。与采用单步回答方案的现有回答方案相比,本文所称的预测分数(logits)具有相同的初始化和连续修正的可能性。
计算每种模态的贡献中使用到的 Soft Attention:传统的Attention Mechanism就是Soft Attention,即通过确定性的得分计算来得到attended之后的编码隐状态。Soft Attention是参数化的(Parameterization),因此可导,可以被嵌入到模型中去,直接训练。梯度可以经过Attention Mechanism模块,反向传播到模型其他部分。 也有称作Top-down Attention。
PAMN

图1给出了PAMN的总体结构,它充分利用了不同的信息源(视频、字幕、问题和候选答案)来回答问题。PAMN的流水线如下所示。首先,将视频和字幕嵌入到双memory中,如图1(a)所示,它为每个模态保持独立的memory。然后,递进attention机制确定与回答问题相关的时间部分,如图1(b)所示。为了推断出正确答案,将图1©中的动态模态融合,通过考虑每个模态的贡献,自适应地集成每个memory的输出。置信度回答方案从同样可能的置信度中依次修正每个答案的置信度,如图1(d)所示。(即PAMN的流水线如图1由以下四部分组成:(a)问题和候选答案嵌入一个公共空间。视频和字幕被嵌入到双memory中,该双memory为每个模态保持独立的memory。(b)渐进式attention机制确定与回答问题相关的时间部分。为了推断正确答案,(c)动态模态融合,通过考虑每个模态的贡献,自适应地整合每个memory的输出。(d)置信度修正回答方案从同样可能的初始化置信度中依次修正每个答案的置信度。)
Problem Setup
PAMN的输入是(1)问题表示q∈R300,(2)五个候选答案表示{ai} i=15∈R5×300,(3)整部电影中与时间对齐的视频表示(v)和字幕表示(s)。 字幕表示si的每个元素对应于一个角色的对话句子,视频表示vi的每个元素都是从时间对齐的视频剪辑中提取的。 电影的总句子数表示为T。目的是使以下可能性最大化:
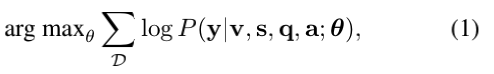
其中θ表示可学习的模型参数,D表示数据集,y表示正确答案。
Dual Memory Embedding
首先将输入映射到嵌入空间。通过具有参数Wug∈R300×d和bug∈Rd的权重共享线性完全连接(FC)层,问题表示q和候选答案表示{ai} i=15被嵌入到公共空间中,从而产生问题嵌入u∈Rd和答案嵌入g∈R5×d,其中d表示存储维数。
视频表示v和字幕表示s被独立地嵌入,以生成视频memory Mv和字幕memory Ms。这种双重memory结构可以为每种形式精确定位不同的时间部分。为了反映观察到的相邻视频片段通常具有很强的相关性,利用平均池化(Avg.Pool)层将相邻的表示形式存储到单个内存插槽中。
作为双memory嵌入的第一步,将包含两个线性全连接层(它们之间具有ReLU非线性)的前馈神经网络(FFN)应用于嵌入视频和字幕表示。 这独立于v和s的每个元素。 然后,将平均池化层应用于对相邻表示进行建模,从而形成视频memory Mv和字幕memory Ms,即双memory:
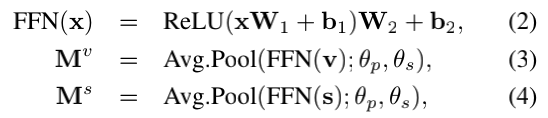
其中θp和θs表示池化的大小和步长,x表示每个输入,W和b分别代表前馈神经网络的权重和偏差。 最后,生成的视频和字幕memory为Mv,Ms ∈ RN×d,其中N = [T /θs]。
Progressive Attention Mechanism
渐进式attention机制将双记忆Mv、Ms、问题嵌入u和答案嵌入g作为输入,并逐步参与和更新双memory在迭代地询问问题和答案以产生时间attention时,会逐渐更新memory以累积提示,以找到用于回答问题的相关时间部分。 观察到memory网络上的单步时间attention通常会产生模糊的attention映射, 渐进式attention机制的多步骤性质使得能够产生更清晰的attention分布, 每次迭代都会从memory中过滤掉不必要的信息。
渐进式attention机制的第一步是通过将问题嵌入u进行时间attention。 attention权重是通过计算每个memory与问题嵌入u之间的余弦相似度来获得的,如公式5、6所示。双memory乘以attention权重,然后是线性全连接层进行更新,如公式7、8中所示。attention独立于视频memory Mv和字幕memory Ms:
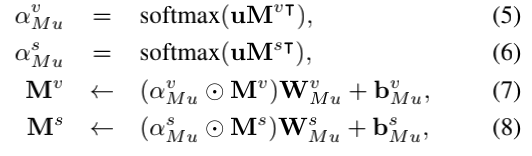
其中αMuv,αMus∈RN分别表示Mv、Ms的时间attention权重。 线性全连接层的可学习参数用WMu,bMu表示,←表示更新操作,并表示在适当轴上进行广播的点乘。
渐进式attention机制的第二步是通过答案进行时间attention。 此步骤与第一步相似,不同之处在于它利用答案嵌入g来访问更新的双memory M:
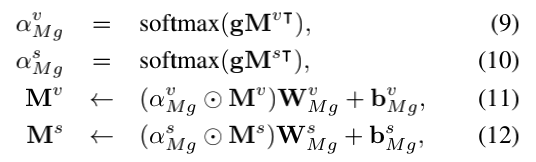
其中,αMuv和αMus∈R5×N表示双memory 的时间attention权重,Mv、Ms表示更新的视频和字幕memory 。
多跳扩展: 如上所述,渐进式attention机制对于每个attention步骤仅参与一次双memory 。 在这种情况下,双memory 可能包含许多不相关的信息,并且缺乏查询复杂语义来回答问题的能力。 渐进attention可以自然地扩展为利用多跳来抽象概念的细粒度提取和高级语义的推理。
与利用第k跳的输出ok和查询uk的总和作为下一跳的查询的memory 网络不同,将嵌入u的相同问题与更新的双memory M(k)用于第k 跳。 分别重复公式5-8、9-12 hMu,hMg次。 每个attend和更新操作可以表示为:
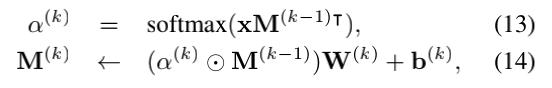
其中省略了每个等式对应的下标和上标,以避免重复,x表示递进attention的每一步的u或g。
Dynamic Modality Fusion
动态模态融合在每个渐进式attention步骤结束时将双memory融合为融合输出o。 不同的问题需要不同的模态来推断答案。 动态模态融合是基于soft attention的算法,该算法确定每种模态对回答问题的贡献。
给定双memory M,动态模态融合首先沿时间轴对每个memory求和,并通过将问题嵌入u来计算余弦相似度以计算attention得分。
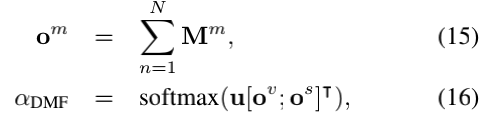
其中,m表示每个模态v或s,om表示每个memory的输出,N表示双memory的时间长度,而αDMF表示attention权重。 最后,融合输出o是通过attention权重和memory输出之间的加权求和来计算的:
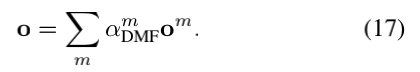
学到的attention权重可以解释为每种模态对问答的贡献或重要性。 通过调节每个模态在融合输出上的比率,动态模态融合通过丢弃不必要模态中的信息来实现稳定的学习。
Belief Correction Answering Scheme
置信度修正答案方案在五个候选答案中选择了正确答案。置信度修正回答方案不是一次确定预测分数,而是通过观察各种信息源来连续修正修正预测分数。 这模仿了人类回答难题的多步推理过程。 结合渐进式attention和动态模态融合,PAMN的这种多步骤推理方法增强了模型从多模态数据中提取高级含义的能力。
置信度B∈R5表示候选答案的预测分数。 预测概率z∈R5是通过对置信度进行归一化计算得出的,答案y的预测概率最高:
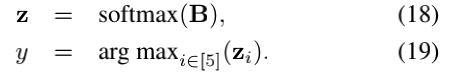
初始化置信度的一种方法是空初始化,它在观察任何信息之前赋予所有候选答案相同的概率。 为了反映这种无偏的初始化,将置信度B初始化为零向量。
置信度修正回答方案采用三步置信度修正; u,Mu和Mg修正。 对于每个修正步骤,通过累积答案嵌入g和观察信息之间的相似性来修正置信度。 首先仅考虑问题即可修正置信度,即u-修正。 直觉是,人类通常只浏览问题和候选答案后会先建立偏好:
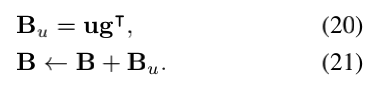
然后,对于Mu和Mg修正,将考虑第一和第二渐进式attention步骤oMu和oMg的输出。 再次,计算答案嵌入g之间的相似度:
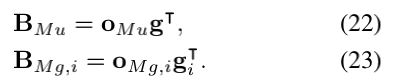
最后,置信度被修正以推断出正确答案:
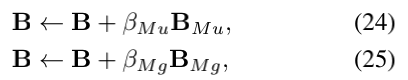
其中修正权重βMu,βMg是可缩放相应置信度修正的超参数。 请注意,将置信度被归一化,以在每次修正之后具有单位范数。
实验
Dataset
MovieQA基准是为电影故事QA而构建的,它包括各种信息源,如电影剪辑、字幕、情节提要、脚本和DVS转录。MovieQA数据集包含408部电影,对应14944道选择题。MovieQA基准由6个任务组成,根据这些任务去选择使用的来源。本文研究的是视频+字幕任务,这是唯一一个利用电影片段的任务。由于只有140部电影包含视频片段,因此有6462个问答对,分为4318个训练样本、886个验证样本和1258个测试样本。
TVQA基准是电视节目领域的视频故事QA数据集。它由六个电视节目的152.5万个问答对组成:《生活大爆炸》、《我如何遇见你的母亲》、《老友记》、《实习医生格蕾》、《房子》、《城堡》。TVQA的每一个部分分别包含122K、15.25K、15.25K用于训练、验证和测试。不像MovieQA那样将整部电影作为输入,TVQA包含21793个从原始电视节目中分割出来的60/90秒的短片段,用于问答。
Feature extraction
文本特征将问题,候选答案和字幕中的每个句子划分为单词序列,然后使用Tapaswi等人提供的跳过语法模型嵌入每个单词。 在MovieQA情节概要上进行了训练。 为了编码句子中单词的顺序,位置编码(PE)用于获取文本特征。 例如,在有问题的情况下,
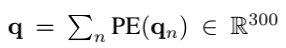
其中每个qn表示单词向量。
Implementation details
整个架构是使用Tensorflow 框架实现的。 本文报道的所有结果均使用Adagrad优化器获得,最小批量大小为32,学习率为0.001。 所有实验均在CUDA加速下使用单个NVIDIA TITAN Xp(12GB内存)GPU进行。 在所有实验中,严格遵守建议的训练/验证/测试拆分。
Quantitative Results
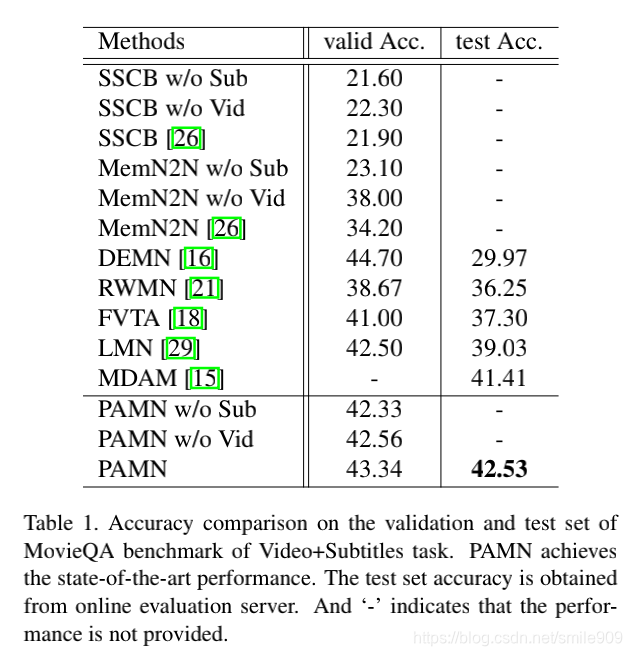
表1比较了Video+字幕任务的MovieQA基准测试的验证和测试精度。作者将PAMN的性能与其它先进的结构进行了比较。MovieQA测试集的真实答案是不可观察的,并且测试集上的评估只能通过在线评估每72小时执行一次。在MovieQA基准测试中,PAMN的测试精度达到了42.53%。它以1.12%和3.50%的优势超过了亚军,MDAM(41.41%)和第三名LMN(39.03%)。注意,MDAM是20个不同模型的集合,而PAMN是一个单一模型。
为了评价每种模式的有效性,还进行了仅使用视频和字幕的实验:PAMN W/O Sub和PAMN W/O VID。根据SSCB W/O Sub和MemN2N W/O Sub的近似随机猜测性能,如表1所示。单纯用视频来理解电影故事是不困难的。与MemN2N W/O Sub相比,PAMN W/O Sub的性能提高了19.23%。它甚至达到了与同时利用视频和字幕的LMN相当的性能。即使不看字幕,PAMN也能理解电影故事。从表1中可以看出,PAMN的性能要好于带Vid的PAMN和带Sub的PAMN,这表明视频和字幕在提高预测性能方面都提供了必要的信息。

表2显示了在没有时间戳注释的TVQA基准测试上的性能比较。在本实验中,作者使用了Lei等人提取的视频和文本特征,(即ImageNet和visual concept特征用于视频,GloVe特征用于文本)用于公平比较。在此基础上,作者用LSTM代替位置编码对句子特征进行编码。在TVQA基准测试中,PAMN的测试准确率达到了66.77%。
Ablation Study
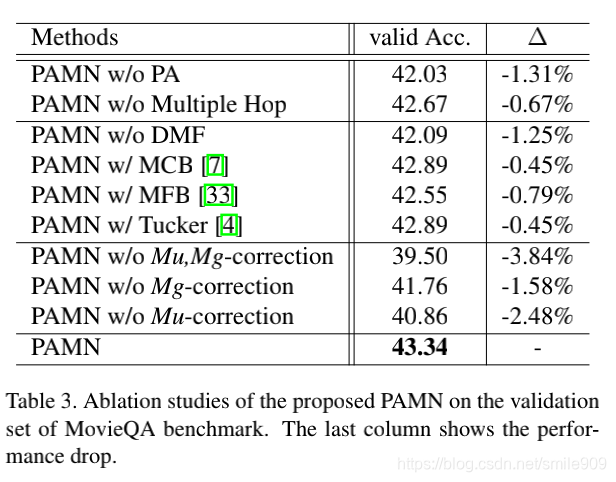
表3总结了在MovieQA基准的验证集上对PAMN的消融分析,以衡量PAMN关键部件的有效性。为考察渐进attention机制的有效性,采用公式(3)和(4)中获得的双记忆,对PAMN的每一个时间attention步骤进行测量。即不使用PA的PAMN不积累线索,每个attention步骤以并行的方式进行。对于每个时间attention步骤,具有多跳的PAMN只关注双存储器一次。如表3的第一个块所示,PAMN(不使用PA)的效果不如PAMN,说明渐进attention机制的attention积累对理解电影故事有重要作用。多跳扩展对于获得尽可能好的性能也是至关重要的。为了消融动态模态融合,作者用四种变体做实验:PAMN W/O DMF取双memory ov、os输出的平均值,PAMN W/MCB、MFB、Tucker分别用MCB、MFB、Tucker分解代替动态模态融合。如表的第二块所示。3、通过平均或双线性操作的模态融合比动态模态融合性能差。这意味着问题依赖于模态加权(即动态模态融合)有助于强化有利模态。为了衡量置信度修正回答方案的有效性,表3的第三块,显示了三个变体的实验结果:PAMN w/o Mu,Mg-correction, PAMN w/o Mg Correction, PAMN w/o Mu-correction。仅使用QA对显示出比随机基线高20%的性能。考虑Mu和Mg修正,没有Mg修正的PAMN的性能提高了2.26%,无Mu修正的PAMN的性能提高了1.36%。

表4总结了三组超参数对性能的影响;按问题u和答案g,θp、θs表示的attention跳数:平均跳数的大小和步长。池化层和βMu,βMg:置信度修正模块的修正权重。具有2-重复的多跳扩展显示了PAMN的最佳验证性能。重复次数超过三次的多跳扩展可能会因数据集的小而出现过拟合。增大θp、θs对性能有积极影响,但在增大θp和θs时,由于平均池化的信息模糊,性能下降。作者观察到没有最佳执行的最优修正权重。如果问题表示u有足够的关于电影中的什么地方需要关注的信息,那么βMu应该更高,反之亦然。此外,优选具有比βMu小的βMg值,因为大的βMg值扩大了ug和Mu修正的效果,因为在每个置信度修正之间应用了归一化。
Qualitative analysis

图2举例说明了PAMN的定性例子。每一个例子都提供了从渐进attention机制得到的时间attention映射。最后一个示例是失败案例。 绿色的句子和对号表示正确的答案,红色的虚线框突出显示了每个置信度更正步骤中PAMN的预测。 对于失败情况,红色“ x”符号表示选择错误。 αMgv,αMgs表示通过渐进式attention的时间注意力,αDMFv,αDMFs表示通过动态模态融合获得的attention。 PAMN的时间关注与生成问题的GroundTruth(GT)非常匹配。 通过观察各种信息源,PAMN成功地将置信度修正为正确答案。

图3通过MemN2N、RWMN和PAMN在MovieQA的验证集上关于问题的第一个词的精确度比较。PAMN在大多数问题类型上都优于PAMN。作者观察到PAMN在主要问题类型上优于MemN2N和RWMN,特别是在where问题和where问题上PAMN分别获得了20%和13%的表现,这说明PAMN在准确定位电影故事方面的优势。
贡献
(1)本文提出了一种电影故事问答体系结构PAMN,该体系结构具有三个特点,能够解决电影故事问答的主要问题;渐进attention、动态模态融合和置信度修正回答方案。
(2)PAMN在MovieQA数据集上取得了较好的效果。定量和定性的结果都显示了PAMN的优点和潜力。
小结
本文提出了一种用于电影故事问答(QA)的渐进attention记忆网络(PAMN)。与VQA相比,电影故事问答具有以下两个方面的挑战性:(1)由于电影通常长于一个小时,所以很难确定与回答问题相关的时间部分;(2)它既有视频又有字幕,不同的问题需要不同的模态来推断答案。为了克服这些挑战,PAMN包括三个主要特征:(1)渐进attention机制,利用问题和答案中的线索逐步剪除记忆中不相关的时间部分;(2)动态模态融合,自适应地确定每个模态对当前问题回答的贡献;(3)置信度修正回答机制,依次计算每个候选答案的预测分数。通过对MovieQA和TVQA两个公共基准数据集的测试,证明了每个特征都有助于作者的电影故事QA架构PAMN,并提高了性能以达到最先进的效果。对PAMN的推理机制进行了可视化的定性分析。
这篇关于CVPR 2019 Progressive Attention Memory Network for Movie Story Question Answering的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!

![BUUCTF靶场[web][极客大挑战 2019]Http、[HCTF 2018]admin](https://i-blog.csdnimg.cn/direct/ed45c0efd0ac40c68b2c1bc7b6d90ebc.png)