本文主要是介绍论文笔记:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文链接:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
Bottom-Up Attention Model
本文的bottom up attention 模型在后面的image caption部分和VQA部分都会被用到。
这里用的是object detection领域的Faster R-CNN方法来提取,详细的就不再说了。

其中把提取出的region的mean-pooled convolutional feature定义为 v i v_i vi 。
因为只有小部分的bounding box会被选择出来, Faster R-CNN可以看作是一种hard attention机制。
bottom up attetion model在完成imageNet的预训练后,又到visual genome数据上进行了训练,原因如下。
为了学习到更好的特征表示,除了预测object class以外,他们额外加了一个训练输出,来预测region i i i 的attribute class(比如物体的颜色、材质等,具体见上图,这些属性在visual genome上可以找到)。这里是通过把 v i v_i vi和一个可训练的ground-truth object class的embedding这两者进行concatenate,并把它送达到一个额外的输出层,输出层是每个attribute class的softmax分布。
本文保留了Faster R-CNN的损失函数,并在此基础上加了一个multi-class loss来训练attribute predictor。
Image Caption部分
Caption model结构如图所示,共有2个LSTM模块,一个是Language LSTM,另一个是Top-Down Attention LSTM。
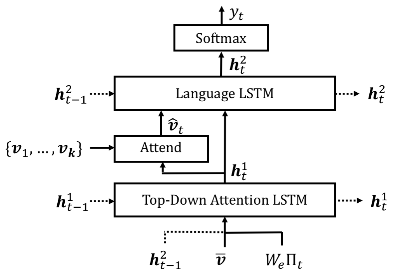
这里两个LSTM都是用的标准LSTM,因此就简化表述了:
h t = L S T M ( x t , h t − 1 ) h_t = LSTM(x_t, h_{t-1}) ht=LSTM(xt,ht−1)
其中,对于LSTM的输入 x t x_t xt 以及hidden state h t h_t ht,使用上标1表示top-down attention LSTM,上标2表示language LSTM。
这个模型的结构很有意思,两个LSTM都在互相使用对方前一个时刻的隐状态,具体结合公式来看。
top-down attention LSTM
top-down attention使用LSTM来确定image feature v i v_i vi 的权重, 是soft attention机制。
而top-down attention LSTM的输入 x t 1 = [ h t − 1 2 , v ‾ , W e Π t ] x^1_t = [h^2_{t-1}, \overline{v}, W_eΠ_t] xt1=[ht−12,v,WeΠt]分别由:
- 前一时刻language model的hidden state h t − 1 2 h^2_{t-1} ht−12
- k个image feature的 mean-pooled feature v ‾ = 1 k ∑ i v i \overline{v} = \frac{1}{k}\sum_iv_i v=k1∑ivi
- 之前生成的词的encoding( Π t Π_t Πt为t时刻输入单词的one-hot encoding, W e W_e We为embedding矩阵。)
这三者concatenate而成。
PS:论文原文提到:
These inputs provide the attention LSTM with maximum context regarding the state of the language LSTM, the overall content of the image, and the partial caption output generated so far, respectively.
而公式上只是输入了几个局部的image feature,而不是整张图片,个人认为严格意义上这不能等同于overall content of the image
对于k个image feature v i v_i vi的attention权重 α i , j \alpha_{i,j} αi,j,是由top-down attention LSTM在每一个时刻利用自身的hidden state h t 1 h_t^{1} ht1产生的:
a i , t = w a T t a n h ( W v a v i + W h a h t 1 ) a_{i,t} = w_a^T tanh(W_{va} v_i + W_{ha} h_t^1) ai,t=waTtanh(Wvavi+Whaht1)
α t = s o f t m a x ( a t ) \alpha_t = softmax(a_t) αt=softmax(at)
v t ^ = ∑ i = 1 K α i , t v i \hat{v_t} = \sum_{i=1}^K\alpha_{i,t}v_i vt^=∑i=1Kαi,tvi
其中 v t ^ \hat{v_t} vt^ 将在language LSTM中被用到。
简单来说, h t 1 h^1_t ht1记忆了之前输入的单词、图像的mean-pooled feature以及language LSTM的隐状态;而 W a T W_a^T WaT则根据 h t 1 h^1_t ht1以及 v i v_i vi来学习如何计算出 v i v_i vi的权重。
language LSTM
language LSTM的输入 x t 2 = [ v t ^ , h t 1 ] x_t^2 = [ \hat{v_t}, h^1_t] xt2=[vt^,ht1]由上述的:
- attention feature加权和 v t ^ \hat{v_t} vt^
- 当前时刻attention LSTM的hidden state h t 1 h^1_t ht1
concatenate而成。
在t 时刻输出的任一单词的概率分布 p ( y t ∣ y 1 : t − 1 ) = s o f t m a x ( W p h t 2 + b p ) p(y_t|y_{1:t-1})=softmax(W_p h^2_t +b_p) p(yt∣y1:t−1)=softmax(Wpht2+bp),其中 ( y 1 , . . . , y T ) (y_1,...,y_T) (y1,...,yT)为单词的序列。
而整个句子的概率分布 p ( y 1 : T ) = ∏ t = 1 T p ( y t ∣ y 1 : t − 1 ) p(y_{1:T})=\prod_{t=1}^Tp(y_t|y_{1:t-1}) p(y1:T)=∏t=1Tp(yt∣y1:t−1),为每个单词概率的连乘。
训练目标
文章首先使用的是最小化cross entropy L X E ( θ ) = − ∑ t = 1 T l o g ( p θ ( y t ∗ ∣ y 1 : t − 1 ∗ ) ) L_{XE}(\theta) = - \sum^T_{t=1}log(p_{\theta}(y^*_t|y^*_{1:t-1})) LXE(θ)=−∑t=1Tlog(pθ(yt∗∣y1:t−1∗)) 来进行训练的,其中 y 1 : T ∗ y^*_{1:T} y1:T∗是ground-truth caption。
另外文章还用到了SCST中的强化学习方法来对CIDEr分数进行优化:
L R ( θ ) = − E y 1 : T ∼ p θ [ r ( y 1 : T ) ] L_R(\theta) = -\mathbb{E}_{y_{1:T}\sim p_\theta} [r(y_{1:T})] LR(θ)=−Ey1:T∼pθ[r(y1:T)]
梯度可以被近似为:
∇ θ L R ( θ ) ≈ ( r ( y 1 : T S ) − r ( y ^ 1 : T ) ) ∇ θ log p θ ( y 1 : T S ) \nabla_\theta L_R(\theta) \approx (r(y^S_{1:T}) - r(\hat y_{1:T}))\nabla_\theta \log p_\theta(y^S_{1:T}) ∇θLR(θ)≈(r(y1:TS)−r(y^1:T))∇θlogpθ(y1:TS)
其中 y 1 : T S y^S_{1:T} y1:TS是强化学习中samlpe得到的caption, y ^ 1 : T \hat y_{1:T} y^1:T是baseline,总的来说,如果这个sample的句子比baseline好,这个梯度会提高它出现的概率,如果不好就抑制。
具体需要原理和推导需要看原论文以及强化学习相关理论。
本文使用beam size为5的beam search进行decode,并且发现,在这个size下通常会包含至少一个质量非常高(分数很高)的句子,而且这个句子的log概率通常不会很高。因此为了减少计算量,在强化学习的优化过程中,本文就只在beam search decode出来的句子中进行sample。
VQA部分
VQA模型也同样使用的是 soft top-down attention机制,结构如图所示:

对问题和图片进行joint multimodal embedding。
对于网络内的非线性变换,这里是用gated hyperbolic tangent activation来实现的,是highway network的一种形式。对于每一个gated tanh层,都是用如下方式来实现映射 f a : x ∈ R m → y ∈ R n f_a: x\in R^m \rightarrow y \in R^n fa:x∈Rm→y∈Rn:
y ~ = t a n h ( W x + b ) \tilde y = tanh (Wx + b) y~=tanh(Wx+b)
g = σ ( W ′ x + b ) g = \sigma (W'x+b) g=σ(W′x+b)
y = y ~ ∘ g y = \tilde y \circ g y=y~∘g
其中 α \alpha α表示函数内的参数 ∘ \circ ∘代表Hadamard积。
对于这个非线性变换,2017 VQA Challenge 第一名技术报告提到:
本质上就是原来的 tanh 激励上根据获得的 gate 进行了 mask,其实是跟 LSTM 和 GRU 中间非线性用的是一样的。
VQA中的问题Q被编码成GRU内的隐状态 q q q,其中单词是以可训练的word embedding来表达的。
其中对于k个image features v i v_i vi的unnormalized attention weight a i a_i ai是这样计算的:
a i = w a T f a ( [ v i , q ] ) a_i = w^T_a f_a([v_i,q]) ai=waTfa([vi,q])
而normalized attention weight α t \alpha_t αt和attended image feature v ^ t \hat v_t v^t就以caption 部分的方式计算。
输出响应 y y y的分布以如下方式计算:
h = f q ( q ) ∘ f v ( v ^ ) h = f_q(q)\circ f_v(\hat v) h=fq(q)∘fv(v^)
p ( y ) = σ ( W o f o ( h ) ) p(y) = \sigma(W_of_o(h)) p(y)=σ(Wofo(h))
其中 h h h是问题和图像的联合表示。由于篇幅限制,文章没有给出更多的VQA系统的细节,详见Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge。
实验结果
总的来说,image caption和VQA部分的结果都是当时state-of-the-art的,但是VQA部分的分析较少,就只放image caption的分析了。

这里的Resnet是文章选取的一个baseline模型,用来代替bottom-up attention机制。也就是说这个baseline模型只有top-down的attention机制。
可以看到,无论有没有加CIDEr的强化学习训练、有没有使用bottom-up机制,本文的模型都比SCST的方法要好。而且SCST是从4个随机初始化的模型里面选了一个最好的,而本文这里的对比就只用了一个模型。
本文也试验了4个模型ensemble后的结果:

可以看到,本文的模型跟其他模型相比提升非常大。
本文还做了个实验证明本文bottom up attention机制的作用:

根据实验显示,如果没有清晰的视觉信息的引导的话,模型可能会过分依赖于语言中的上下文信息,因此不能很好地识别出一些out-of-context的图片。
(在SCST中也做了out-of-context的图片实验,如果使用attention模型加cross-entropy训练的话是不能准确识别出out-of-context的图片的,加了CIDEr优化以后才能很好地识别出out-of-context的图片。本文这个实验中的Up-Down模型应该也是经过CIDEr优化的,那么这里的结果到底是因为强化学习的效果还是attention的效果呢?)
总结
总的来说,本文主要的贡献在于提出了Bottom-Up and Top-Down Attention的机制,如果跟前面Image Captioning with Semantic Attention的对比的话,主要区别就是:
后者提出的只是一个个的单词,来指代检测到的物体,不包含空间的信息;而前者是一个feature vector,包含空间信息的同时还可以对应多个单词,比如一个形容词和名词,表现力更丰富了。
另外,个人认为两个LSTM之前互相利用对方隐状态这一架构设计也非常有意思。
这篇关于论文笔记:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







