captioning专题

图像字幕Image Captioning——使用语法和语义正确的语言描述图像
1. 什么是图像字幕 Image Captioning(图像字幕生成) 是计算机视觉和自然语言处理(NLP)领域的一个交叉研究任务,其目标是自动生成能够描述给定图像内容的自然语言句子。这项任务要求系统不仅要理解图像中的视觉内容,还要能够将这些视觉信息转化为具有连贯性和语义丰富的文本描述。 图像字幕任务的3个关键因素:图像中的显著对象;对象之间的相互作用;用自然语

论文笔记 DenseCap: Fully Convolutional Localization Networks for Dense Captioning
李飞飞组的文章,是一篇很有意思的文章,主要介绍了一种CNN解决密集字幕任务的方法。密集字幕任务主要含两个方面: (1)单个单词描述的目标检测任务;(2)对整个图像的一个预测区域的字幕标注任务。具体任务需求如下: 文章主要提出了全卷积定位网络(FCLN)架构,无需外部区域的建议,并可以用单轮优化进行端对端的训练。该架构包含一个卷积网络,一个新的密集定位层,一个生成标签序列的递归神经网络的语言
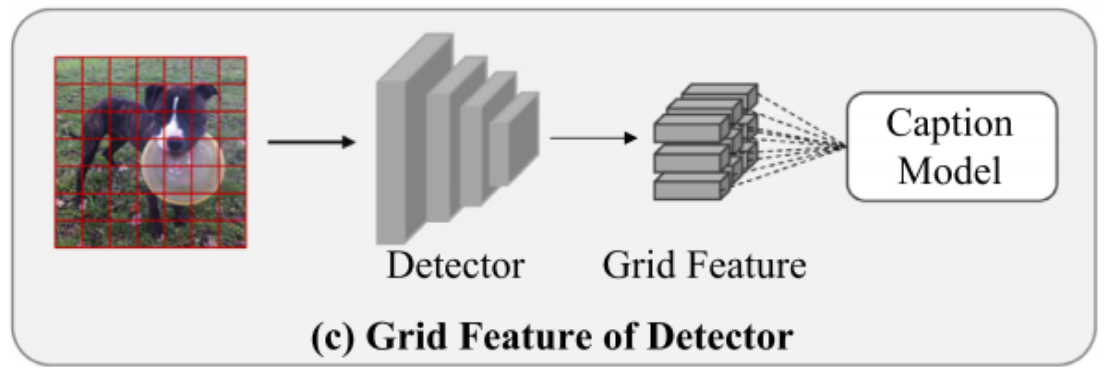
【Image captioning】基于检测模型网格特征提取——以Sydeny为例
【Image captioning】基于检测模型网格特征提取——以Sydeny为例 今天,我们将重点探讨如何利用Faster R-CNN检测模型来提取Sydeny数据集的网格特征。具体而言,这一过程涉及通过Faster R-CNN模型对图像进行分析,进而抽取出关键区域的特征信息,这些特征在网格结构中被系统地组织和表示。下面,我将引导大家深入了解这一特征提取流程。 1. 数据的预处理

【Image captioning】UCM字幕生成Resnet特征
1. 分析数据规模 UCM-Captions数据集是基于UCM-Merced大学土地利用数据集构建的。图像来自美国地质调查局的国家地图城市区域。UCM-Captions数据集包含21个类别,包括飞机、海滩、高架桥和体育场等,总共有2100张遥感图像。UCM-Captions数据集中的一些样本如图5所示。每张遥感图像的分辨率为256 × 256像素,并配备有5个不同的标题标签。整个数据集使用368
【Image captioning】MDSANet在自定义数据上的训练与测试调试
Multi-Branch Distance-Sensitive Self-Attention Network for Image Captioning(MDSANet)在自定义数据上的训练与测试调试 1. 环境设置 我们采用和Lstnet一样的环境即可,所以我们直接克隆环境。我们执行如下命令,进行克隆: conda create --name MDSANet --clone lstnet

【Image captioning】论文阅读九—Self-Distillation for Few-Shot Image Captioning_2022
摘要 大规模图像字幕数据集的开发成本高昂,而大量未配对的图像和文本语料库可能有助于减少手动注释的工作。在本文中,我们研究了只需要少量带注释的图像标题对的少样本图像标题问题。我们提出了一种基于集成的自蒸馏方法,允许使用不成对的图像和字幕来训练图像字幕模型。该集成由多个基础模型组成,在每次迭代中使用不同的数据样本进行训练。为了从未配对的图像中学习,我们使用整体生成多个伪标题,并根据它们的置信水平

【Image captioning】论文阅读七—Efficient Image Captioning for Edge Devices_AAAI2023
中文标题:面向边缘设备的高效图像描述(Efficient Image Captioning for Edge Devices) 文章目录 1. 引言2. 相关工作3. 方法3.1 Model Architecture(模型结构)3.2 Model Training (模型训练)3.3 Knowledge Distillation (知识蒸馏) 4. 实验4.1 数据集和评价指标4.2

CVPR 2023: Cross-Domain Image Captioning with Discriminative Finetuning
基于MECE原则,我们可以使用以下 6 个图像字幕研究分类标准: 1. 模型架构 编码器-解码器模型:这些传统的序列到序列模型使用单独的神经网络来处理图像和生成字幕。编码器,通常是卷积神经网络(CNN),从图像中提取视觉特征。解码器,通常是循环神经网络(RNN)如 LSTM,然后逐字生成字幕,条件是编码后的图像特征。这是早期作品如 Show and Tell [44] 和 VGG+LSTM
【Image captioning】图像描述标注(Image captioning)软件的设计与实现
1. 引言 大家好!我是一位对图像字幕(Image captioning)生成感兴趣的研究者。在研究过程中,我不可避免地需要对图像进行标注。然而,早期阶段我使用TXT记事本进行语言描述时,遇到了一些效率低下、错标和漏标等问题。为了提高工作效率,我设计了一款基于QT的图像描述标注软件。 2. 功能描述 这款基于QT的图像描述标注软件具有以下主要特点: 图像浏览功能:用户可以轻松浏览一个文件夹
ACL 2020 MART: Memory-Augmented Recurrent Transformer for Coherent Video Paragraph Captioning
动机 本文目标是生成一个段落(多个句子),条件是输入具有几个预定义的事件片段的视频。为视频生成多句子描述是最具挑战性的任务之一,因为它不仅要求视频的视觉相关性,而且要求段落中句子之间基于语篇的连贯性。最近,Transformer已被证明比RNN更有效,在许多顺序建模任务中展示了卓越的性能。之前将transformer模型引入视频段落captioning任务的方法,Transformer操作在分离
论文笔记:Contrastive Learning for Image Captioning
原文链接:Contrastive Learning for Image Captioning Introduction 本文的提出的Contrastive Learning (CL) 主要是为了解决Image Caption任务中生成的Caption缺少Distinctiveness的问题。 这里的Distinctiveness可以理解为独特性,指的是对于不同的图片,其caption也应

论文笔记:Self-critical Sequence Training for Image Captioning
论文链接:Self-critical Sequence Training for Image Captioning 引言 现在image caption主要存在的问题有: exposure bias:模型训练的时候用的是叫“Teacher-Forcing”的方式:输入RNN的上一时刻的单词是来自训练集的ground-truth单词。而在测试的时候依赖的是自己生成的单词,一旦生成得不好就

论文笔记:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
论文链接:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering Bottom-Up Attention Model 本文的bottom up attention 模型在后面的image caption部分和VQA部分都会被用到。 这里用的是object detection领域
Let there be a clock on the beach: Reducing Object Hallucination in Image Captioning
Abstract 用缺失或不存在的对象来解释图像被称为图像字幕中的对象偏差(幻觉)。这种行为在最先进的字幕模型中非常常见,这是人类所不希望的。为了减少字幕中的物体幻觉,我们提出了三种简单而有效的句子训练增强方法,不需要新的训练数据或增加模型大小。通过广泛的分析,我们表明所提出的方法可以显着减少我们的模型对幻觉指标的对象偏差。此外,我们通过实验证明我们的方法减少了对视觉特征的依赖。我们所有的代码

A Comprehensive Survey of Deep Learning for Image Captioning--图像描述深度学习综述
原文地址:https://arxiv.org/abs/1810.04020 翻译走起,第一次翻译文献,可能是一顿ctrl+c,ctrl+v在加上百度翻译的操作吧,如有问题和建议,欢迎留言。image captioning根据个人喜好翻译成图像描述,其他什么图像字幕,图像标题生成,whatever,大家随意好了。 图像描述深度学习综述 图像描述的定义:Generating a descript
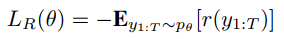
【论文阅读笔记】Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering.
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering. 2018-CVPR P. Anderson, X. He, C. Buehler, D. Teney, M. Johnson, S. Gould, and L. Zhang. 什么是“自上而下”,“自下而上”? 类比人类视觉

Video captioning——Video Analysis视频to文字描述任务
Video captioning的定义 为一张图片产生一个描述被称为image caption任务,为一个视频产生一个描述成为vedio caption,但视频可以理解为在时间上有连续性的一组图片,因此可以理解成为一组图片产生一个描述。 vedio caption是属于对vedio analysis的高层语义分析。 描述一般描述两个方向,属性和相互关系。 三种基本方法: 基于模版的方法,较为
Introduction to Advanced Machine Learning, 第六周,week6_final_project_image_captioning_clean(答案)
这是俄罗斯高等经济学院的系列课程第一门,Introduction to Advanced Machine Learning,第六周编程作业。任务是利用pre-trained InceptionV3架构对图片进行编码,这个是预先训练好的架构。我们要使用的是通过这个编码训练一个RNN,来生成图片的标题,即描述图片的内容。其原理和机器翻译类似,相当于训练一个sequence model,输入和输出是不等

nocaps: novel object captioning at scale ---- 文章解读和baseline复现
nocaps: novel object captioning at scale (ICCV 2019) ---- baseline paper: nocaps: novel object captioning at scale code: nocaps-org/updown-baseline: Baseline model for nocaps benchmark, ICCV 2019 pap