本文主要是介绍Video captioning——Video Analysis视频to文字描述任务,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Video captioning的定义
为一张图片产生一个描述被称为image caption任务,为一个视频产生一个描述成为vedio caption,但视频可以理解为在时间上有连续性的一组图片,因此可以理解成为一组图片产生一个描述。
vedio caption是属于对vedio analysis的高层语义分析。
描述一般描述两个方向,属性和相互关系。
三种基本方法:
- 基于模版的方法,较为简单,caption质量在很大程度上取决于句子的模板,句子用句法结构生成,多样性较差。
- 基于检索的方法,一般来说,这个方法在固定场景内的视频中是有效的,因为嵌入空间可以很好地推广,并且更丰富的模型结构提高了性能。 然而,当遇到以前从未见过的情况的视频时,效果会很差。 此外,由于嵌入是固定长度的,因此它限制了视频和文本描述可以携带的信息量。
- 基于编码的方法, 更正式地说,这些工作提出的框架是一个编码器 - 解码器结构,它将视频编码为语义表示特征向量,然后解码为自然语言。
主要技术(attention,3D conv)
双流法
光流表达了图像的变化,由于它包含了目标运动的信息,因此可被观察者用来确定目标的运动情况,每张图像中每个像素的运动速度和运动方向找出来就是光流场。

采用双通道CNN的方式,对光流和图片同时处理得到结果,最后fusion一起。
一般的光流图为双通道的信息,分别为在X轴上的信息变化与Y轴上的信息变化。光流图是选择视频中的任意一帧的时间然后及其后面的N帧叠合成一个光流栈进入处理。
3D卷积
由于视频帧之间具有时间连续性,普通的2D卷积不能够充分表达这个特性,因此把相邻的几个帧合在一起组成一个具有三个维度的输入向量,同时在这三个维度进行卷积。
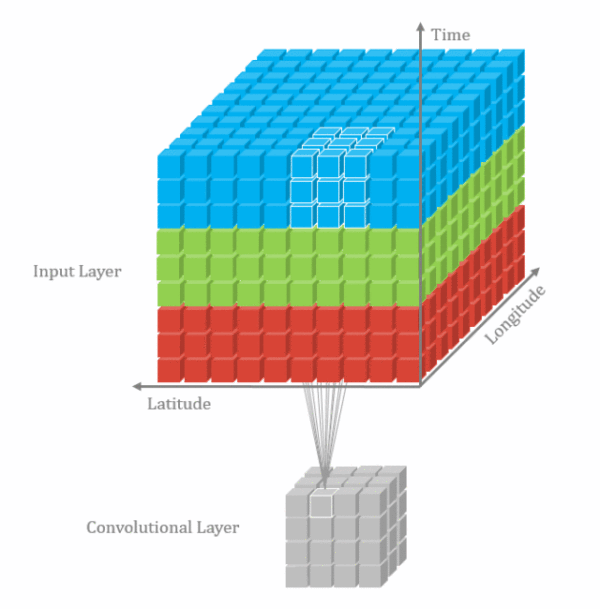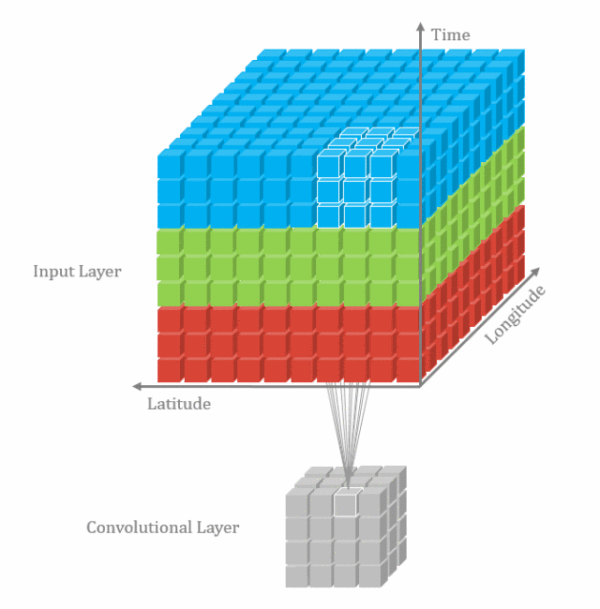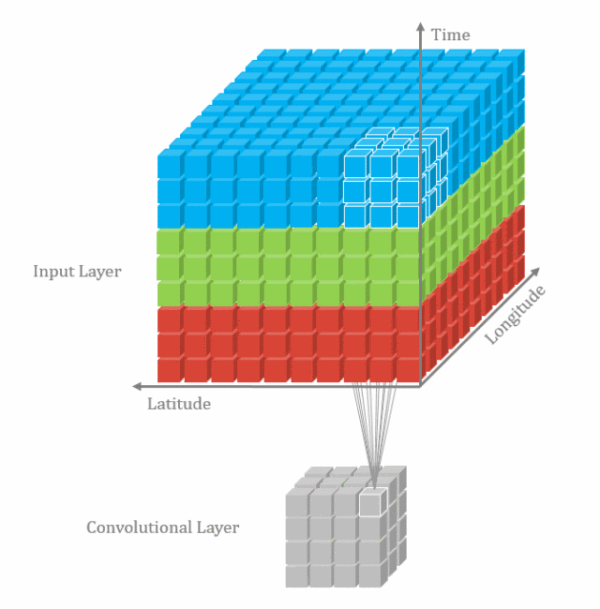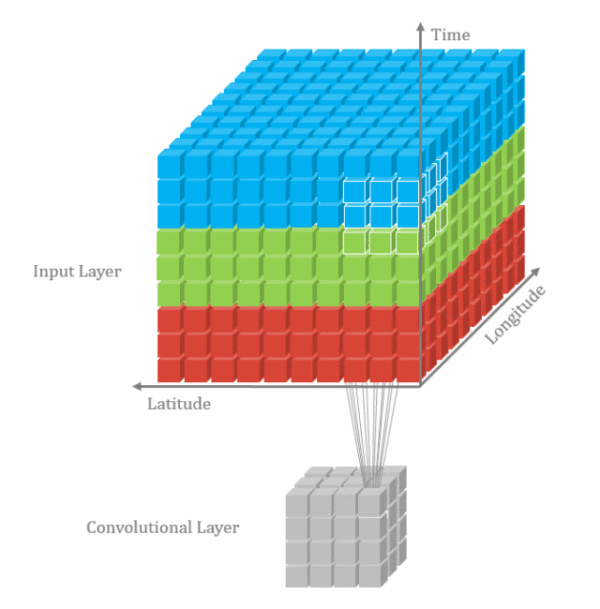
3D卷积也只是一种增加时间信息的补充手段,实际使用中2D卷积的结果+3D卷积结果fusion一起的效果更好。

从LSTM-E和p-RNN的结果可以看出,视频处理中,3D卷积效果好于2D卷积,二者结合一起,效果更好。
3D CNN模型的主要特性有:
1)通过3D卷积操作核去提取数据的时间和空间特征,在CNN的卷积层使用3D卷积。
2)3D CNN模型可以同时处理多幅图片,达到附加信息的提取。
3)融合时空域的预测。
Attention机制
两种attention机制:软注意力机制(soft-attention)和硬注意力机制(hard-attention)。软注意力机制对每一个图像区域学习一个大小介于0与1之间的注意力权重,其和为1,再将各图像区域进行加权求和。硬注意力机制则将最大权重置为1,而将其他区域权重置0,以达到仅注意一个区域的目的。在实际的应用中软注意力机制得到了更广泛的应用。由于其良好的效果和可解释性,attention机制已经成为一种主流的模型构件。
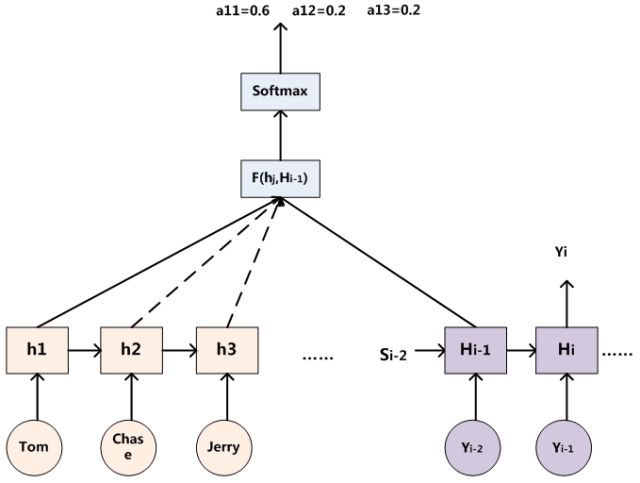
attention机制计算方法
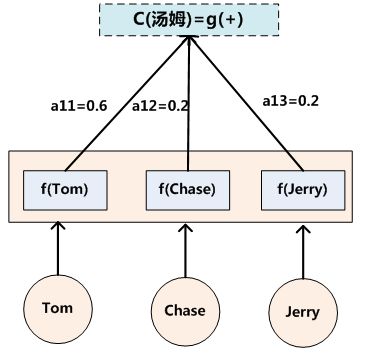
attention机制使用方法
如上所示,Attention基于先前时间的隐藏状态(其可能概括所有先前生成的帧)和对应帧的时间特征向量,为所有帧生成权重。
Attention机制由计算机视觉引入,在自然语言处理领域获得长足发展。而在image caption这样结合CV和NLP的领域,attention机制无疑是最有发展潜力的研究方向之一。
整体框架

整体分为三部分。
第一部分抽取视频特征,有2D卷积帧抽取,3D卷积,以及2D卷积和3D卷积结合的方式
第二部分对抽取出的视频特征进行处理,又称为encoder,有attention机制,直接pooling,LSTM以及多层级的encoder等,这部分的处理目的一般是为了考虑视频帧之间的时间连续性进行处理。
第三部分就是就是常规的的decoder对编码信息进行解码翻译,有LSTM和GRU等。
一般情况下大都只是对第一部分和第二部分,重点在于如何充分考虑视频帧之间的的时间特性来抽取特征和对于抽取出来的特征如何进行更好的再编码。也有用强化学习做video captioning,另18CVPR提出四部分的video caption,多了一个reconstructor部分,达到了目前的state-of-the-art。
目前主要论文
video caption的主要模型有如下几种:
MP-LSTM[1]
该模型是第一个使用encoder-decoder模式来做video caption,框架如下:该模型是第一个使用encoder-decoder模式来做video caption,框架如下:

对视频进行1/10的帧采样,采用AlexNet逐帧对图片进行卷积,对每帧图像的出来的结果之间进行mean pooling 得到固定的4096长度的向量,然后送入双层LSTM中处理得到caption。缺点是不能利用视频的时间关联性的特点。
S2VT[2]
该模型是第一个使用光流法做video caption的模型,框架如下:
主要特点为采用2D卷积+光流法组成encoder对视频进行了处理,从而获得了视频帧之间的时间信息,decoder为普通的双层LSTM。缺点为只能获取短时间内的光流信息。
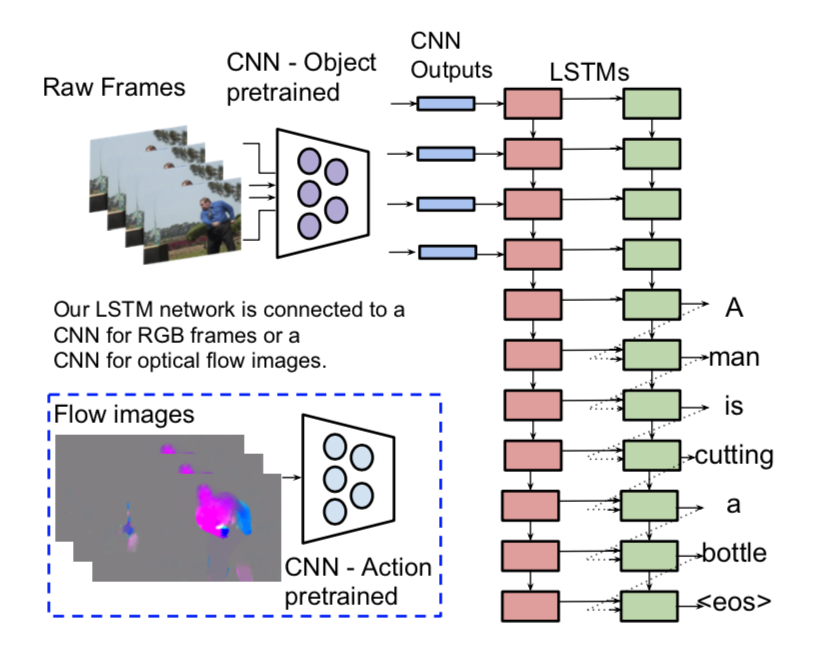
SA[3]
该模型是第一个使用3D卷积和attention机制在video caption中的模型,该框架为后续改进的基本框架。

先用3D卷积获取局部的时间信息特征向量,解码器是带有attention机制的LSTM解码器对编码器生成的所有特征向量以不同权重进行加权,
采用GoogleNet的2D卷积提取帧1024特征向量 3层3D卷积网络处理视频信息,最后堆叠一起送入decoder。
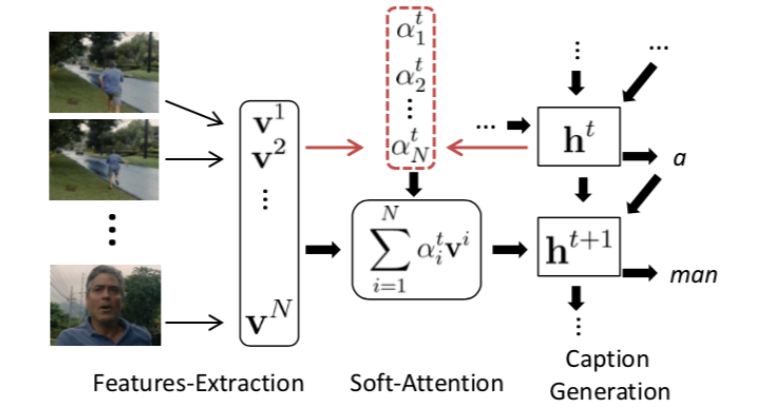
decoder为带有attention的LSTM,soft attention机制可以有效帮助处理视频时间信息,通过生成 α \alpha α来确定输入输入视频帧的权重。通过强调不同帧的不同作用,有效帮助模型生成caption。
HRNE[4]
encoder模型如下:

该模型的特点为encoder不仅对视频帧进行特征抽取,而且用具有层级关系的RNN模型对特征进行处理,encoder利用了不同时间粒度上的信息,即在每一段的LSTM编码器上再加一个编码器来归纳和学习更长时间粒度上的特征信息。模型继续使用了上述的attention机制,取得了很好的效果。但是,它需要固定的手动设置子序列长度,因此它不适应不同类型的视频。
评价指标
bleu
bleu是一种文本评估算法,它是用来评估机器翻译跟专业人工翻译之间的对应关系,核心思想就是机器翻译越接近专业人工翻译,质量就越好,经过bleu算法得出的分数可以作为机器翻译质量的其中一个指标。
优点:方便、快速,结果比较接近人类评分。
缺点:
1.不考虑语言表达(语法)上的准确性;
2. 测评精度会受常用词的干扰;
3. 短译句的测评精度有时会较高;
4. 没有考虑同义词或相似表达的情况,可能会导致合理翻译被否定;
BLEU本身就不追求百分之百的准确性,也不可能做到百分之百,它的目标只是给出一个快且不差的自动评估解决方案。
细节后续看,有现成工具可以使用。
Meteor
METEOR标准于2004年由Lavir发现在评价指标中召回率的意义后提出[3]
他们的研究表明,召回率基础上的标准相比于那些单纯基于精度的标准(如BLEU),其结果和人工判断的结果有较高相关性 ;
METEOR测度基于单精度的加权调和平均数和单字召回率,其目的是解决一些BLEU标准中固有的缺陷;
METEOR也包括其他指标没有发现一些其他功能,如同义词匹配等;
计算METEOR需要预先给定一组校准(alignment)m,而这一校准基于WordNet的同义词库,通过最小化对应语句中连续有序的块(chunks)ch来得出。
和BLEU不同,METEOR同时考虑了基于整个语料库上的准确率和召回率,而最终得出测度;
Dense caption
该任务由李飞飞实验室在2017年提出,同时提出了Activity数据集。
该任务类似于图像的dense caption,其中应为视频提供caption及其时间定位。每个caption描述涉及单个主要活动的事件,并且可以在时间轴上彼此重叠。

如上图所示
对于一个长时间视频来说,用单caption来概括视频内容可能不是一个好的任务描述方式,不同时间段的不同caption有更好的意义。
参考文献:
[1] S. Venugopalan, H. Xu, J. Donahue, M. Rohrbach,R. Mooney, and K. Saenko. Translating videos to natural language using deep recurrent neural networks. In NAACL,2015.1,2,4,5,6,7
[2] S. Venugopalan, M. Rohrbach, J. Donahue, R. Mooney, T. Darrell, and K. Saenko. Sequence to sequence - video to text. In ICCV, December 2015.
[3] https://www.jianshu.com/p/e5156a67c71d 双流法 (Two-Stream) 以及 C3D卷积
[4] P. Pan, Z. Xu, Y. Yang, F. Wu, and Y. Zhuang. Hierarchical recurrent neural encoder for video representation with appli- cation to captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1029–1038, 2016.
[5] https://blog.csdn.net/u013010889/article/details/80087601 Vedio caption tutorial
[6] Jiaqi Su. Study of Video Captioning Problem.
[7] Krishna R , Hata K , Ren F , et al. Dense-Captioning Events in Videos[J]. 2017.
[8] Ji S, Xu W, Yang M, et al. 3D convolutional neural networks for human action recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2013, 35(1): 221-231.
[9] Wang B , Ma L , Zhang W , et al. Reconstruction Network for Video Captioning[J]. 2018.
这篇关于Video captioning——Video Analysis视频to文字描述任务的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






