本文主要是介绍【论文阅读笔记】Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering.,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering.
2018-CVPR
P. Anderson, X. He, C. Buehler, D. Teney, M. Johnson, S. Gould, and L. Zhang.
什么是“自上而下”,“自下而上”?
类比人类视觉的注意力机制:
自上而下:基于某种任务,通过意识,集中地关注某物,比如寻找某物。
自下而上:场景中有某个突出的、显眼的物体,自动地引发意识信号。
问题:
现在的注意力机制都是自上而下的,将部分完成的字幕或图像内容作为上下文,通过训练,有选择地处理CNN的输出。确定图像区域的最佳数量总是需要在粗和细之间进行艰难地权衡。也很少考虑如何确定受关注的图像区域。
思路:
提出“自下而上”机制(基于Faster R-CNN)和“自上而下”机制,两者结合。
自下而上:发现图像I中的k个显著区域(大小可能不同),每个区域用一个卷积特征向量表示。使用Faster R-CNN实现(需要初始化和预训练),可以看作是一种“硬”注意机制,因为从大量区域中选择了少量的区域。
自上而下:决定不同区域的权重,提取的特征是总区域的加权和(“软”注意),并可以生成标题。它包含两个LSTM网络,第一个LSTM作为视觉注意模型,第二个LSTM作为语言生成模型。第一个LSTM的输入由图像特征v的均值、第二个LSTM上步的输出、上步生成的单词的编码组成。第二个LSTM的输入由第一个LSTM的输出、k个图像特征组成。
方法:
Bottom-up自底向上
Faster R-CNN是一种目标检测模型,识别属于特定类的目标实例,并使用包围框对其定位。
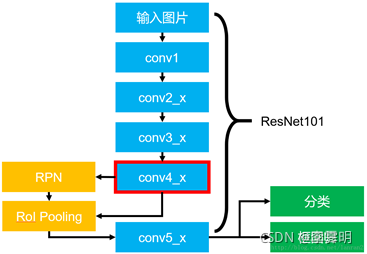
这里,Faster R-CNN结合ResNet-101来提取特征(上图)。RNP利用IoU阈值来对所有区域进行筛选("hard" attention),决定图像中的兴趣区域。Rol pooling给每个选中的区域提取一个小的特征,然后组合在一起作为CNN最后一层的输入。对于每一个区域 i, vi 定义为每个区域的特征(2048维)。
预训练Bottom-Up Attention Model, 首先初始化基于ResNet-101的Faster-RCNN并在ImageNet上进行分类任务的预训练,然后在Genome data上进行训练。为了学习到更好的特征表示,作者增加了一个预测物体属性类别的任务,可以预测区域i的属性。
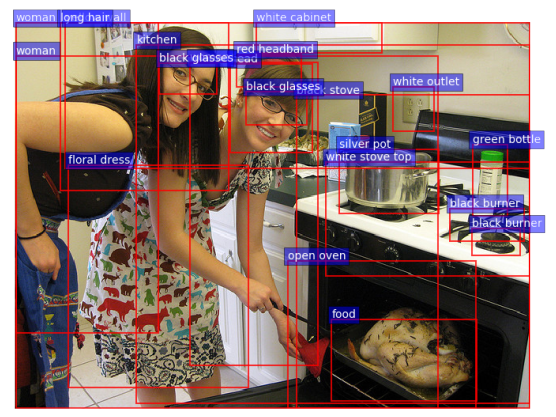
最终Bottom-Up Attention Model可达到(下图)效果。但我们只要k个区域的特征向量V。
Top-down自顶向下
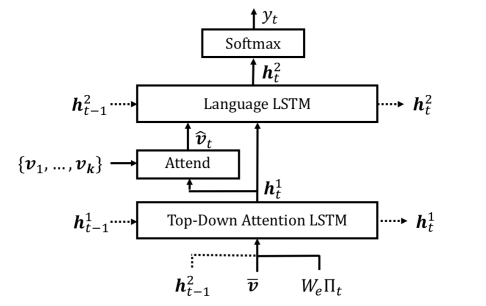
第一个LSTM
输入由三部分组成:

每个时间步t,为k个图像特征vi计算归一化的注意力权重αi,t,综合后输入第二个LSTM


(隐藏层h1t等价于Q;v1~vk等价于K;vi等价于V;v^t等价于Z)
第二个LSTM
输入:
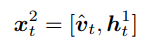
+ 上一步的输出ht-12
每个时间步t,输出ht2,然后计算可能的输出单词的条件分布:

整个输出句子的概率可以看成是所有单词概率的连乘:
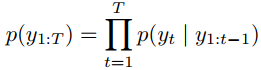
目标函数
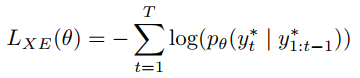
还进行了针对句子级别指标的优化,目标函数定义为:
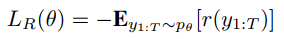
总结:
本文提出了一种结合bottom-up attention和top-down attention的视觉注意力机制,可以看成CNN-Attention + LSTM-Attention。它能够更有效地关注场景的结构,也具有更好地可解释性。bottom-up attention机制就是提取出感兴趣的候选框,可以使用目标检测算法还有很多,可以尝试进行替换。
2022-02-14
by littleoo
这篇关于【论文阅读笔记】Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering.的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








