本文主要是介绍Introduction to Advanced Machine Learning, 第六周,week6_final_project_image_captioning_clean(答案),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这是俄罗斯高等经济学院的系列课程第一门,Introduction to Advanced Machine Learning,第六周编程作业。任务是利用pre-trained InceptionV3架构对图片进行编码,这个是预先训练好的架构。我们要使用的是通过这个编码训练一个RNN,来生成图片的标题,即描述图片的内容。其原理和机器翻译类似,相当于训练一个sequence model,输入和输出是不等长的。而这里输入是CNN的编码,输出是RNN的译码。
这个作业一共两个部分,难易程度:中等偏难。
1. Prepare captions for training,从训练集中提取出常见的词语,生成字典。
2. Define architecture,定义RNN的网络结构
3. Training loop,训练。
最后要保证训练的loss < 2.5, accuracy > 0.5.
Image Captioning Final Project
In this final project you will define and train an image-to-caption model, that can produce descriptions for real world images!
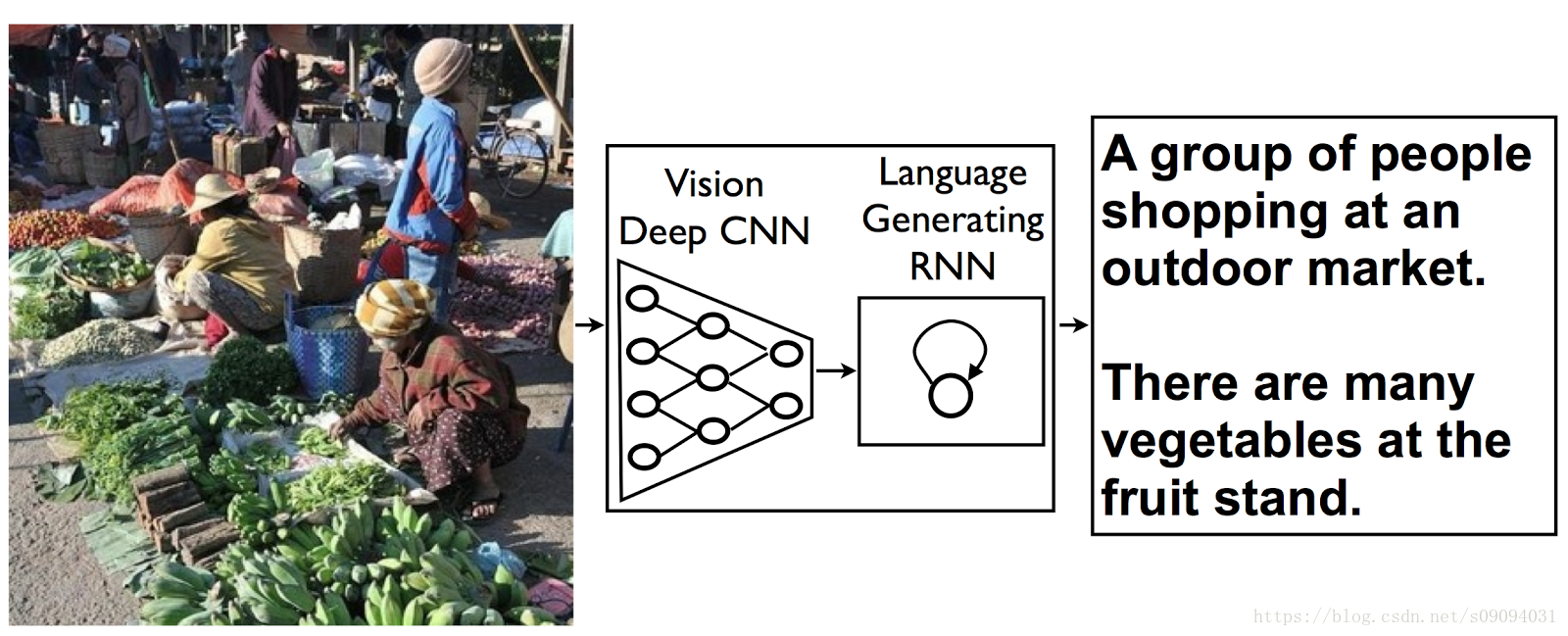
Model architecture: CNN encoder and RNN decoder.
(https://research.googleblog.com/2014/11/a-picture-is-worth-thousand-coherent.html)
Import stuff
import sys
sys.path.append("..")
import grading
import download_utilsdownload_utils.link_all_keras_resources()import tensorflow as tf
from tensorflow.contrib import keras
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
L = keras.layers
K = keras.backend
import tqdm
import utils
import time
import zipfile
import json
from collections import defaultdict
import re
import random
from random import choice
import grading_utils
import osDownload data
Takes 10 hours and 20 GB. We’ve downloaded necessary files for you.
Relevant links (just in case):
- train images http://msvocds.blob.core.windows.net/coco2014/train2014.zip
- validation images http://msvocds.blob.core.windows.net/coco2014/val2014.zip
- captions for both train and validation http://msvocds.blob.core.windows.net/annotations-1-0-3/captions_train-val2014.zip
# we downloaded them for you, just link them here
download_utils.link_week_6_resources()Extract image features
We will use pre-trained InceptionV3 model for CNN encoder (https://research.googleblog.com/2016/03/train-your-own-image-classifier-with.html) and extract its last hidden layer as an embedding:
IMG_SIZE = 299# we take the last hidden layer of InceptionV3 as an image embedding
def get_cnn_encoder():K.set_learning_phase(False)model = keras.applications.InceptionV3(include_top=False)preprocess_for_model = keras.applications.inception_v3.preprocess_inputmodel = keras.models.Model(model.inputs, keras.layers.GlobalAveragePooling2D()(model.output))return model, preprocess_for_modelFeatures extraction takes too much time on CPU:
- Takes 16 minutes on GPU.
- 25x slower (InceptionV3) on CPU and takes 7 hours.
- 10x slower (MobileNet) on CPU and takes 3 hours.
So we’ve done it for you with the following code:
# load pre-trained model
K.clear_session()
encoder, preprocess_for_model = get_cnn_encoder()# extract train features
train_img_embeds, train_img_fns = utils.apply_model("train2014.zip", encoder, preprocess_for_model, input_shape=(IMG_SIZE, IMG_SIZE))
utils.save_pickle(train_img_embeds, "train_img_embeds.pickle")
utils.save_pickle(train_img_fns, "train_img_fns.pickle")# extract validation features
val_img_embeds, val_img_fns = utils.apply_model("val2014.zip", encoder, preprocess_for_model, input_shape=(IMG_SIZE, IMG_SIZE))
utils.save_pickle(val_img_embeds, "val_img_embeds.pickle")
utils.save_pickle(val_img_fns, "val_img_fns.pickle")# sample images for learners
def sample_zip(fn_in, fn_out, rate=0.01, seed=42):np.random.seed(seed)with zipfile.ZipFile(fn_in) as fin, zipfile.ZipFile(fn_out, "w") as fout:sampled = filter(lambda _: np.random.rand() < rate, fin.filelist)for zInfo in sampled:fout.writestr(zInfo, fin.read(zInfo))sample_zip("train2014.zip", "train2014_sample.zip")
sample_zip("val2014.zip", "val2014_sample.zip")# load prepared embeddings
train_img_embeds = utils.read_pickle("train_img_embeds.pickle")
train_img_fns = utils.read_pickle("train_img_fns.pickle")
val_img_embeds = utils.read_pickle("val_img_embeds.pickle")
val_img_fns = utils.read_pickle("val_img_fns.pickle")
# check shapes
print(train_img_embeds.shape, len(train_img_fns))
print(val_img_embeds.shape, len(val_img_fns))(82783, 2048) 82783
(40504, 2048) 40504
# check prepared samples of images
list(filter(lambda x: x.endswith("_sample.zip"), os.listdir(".")))['val2014_sample.zip', 'train2014_sample.zip']
Extract captions for images
# extract captions from zip
def get_captions_for_fns(fns, zip_fn, zip_json_path):zf = zipfile.ZipFile(zip_fn)j = json.loads(zf.read(zip_json_path).decode("utf8"))id_to_fn = {img["id"]: img["file_name"] for img in j["images"]}fn_to_caps = defaultdict(list)for cap in j['annotations']:fn_to_caps[id_to_fn[cap['image_id']]].append(cap['caption'])fn_to_caps = dict(fn_to_caps)return list(map(lambda x: fn_to_caps[x], fns))train_captions = get_captions_for_fns(train_img_fns, "captions_train-val2014.zip", "annotations/captions_train2014.json")val_captions = get_captions_for_fns(val_img_fns, "captions_train-val2014.zip", "annotations/captions_val2014.json")# check shape
print(len(train_img_fns), len(train_captions))
print(len(val_img_fns), len(val_captions))82783 82783
40504 40504
# look at training example (each has 5 captions)
def show_trainig_example(train_img_fns, train_captions, example_idx=0):"""You can change example_idx and see different images"""zf = zipfile.ZipFile("train2014_sample.zip")captions_by_file = dict(zip(train_img_fns, train_captions))all_files = set(train_img_fns)found_files = list(filter(lambda x: x.filename.rsplit("/")[-1] in all_files, zf.filelist))example = found_files[example_idx]img = utils.decode_image_from_buf(zf.read(example))plt.imshow(utils.image_center_crop(img))plt.title("\n".join(captions_by_file[example.filename.rsplit("/")[-1]]))plt.show()show_trainig_example(train_img_fns, train_captions, example_idx=2)
Prepare captions for training
# preview captions data
train_captions[:1][:5]
print(type(train_captions))<class 'list'>
# special tokens
PAD = "#PAD#"
UNK = "#UNK#"
START = "#START#"
END = "#END#"# split sentence into tokens (split into lowercased words)
def split_sentence(sentence):return list(filter(lambda x: len(x) > 0, re.split('\W+', sentence.lower())))def generate_vocabulary(train_captions):"""Return {token: index} for all train tokens (words) that occur 5 times or more, `index` should be from 0 to N, where N is a number of unique tokens in the resulting dictionary.Also, add PAD (for batch padding), UNK (unknown, out of vocabulary), START (start of sentence) and END (end of sentence) tokens into the vocabulary."""flatten = [sentences for captions in train_captions for sentences in captions]flatten = split_sentence(' '.join(flatten))from collections import Countercounter = Counter(flatten)#print(type(counter))#print(counter.items())vocab = [token for token, count in counter.items() if count >= 5]vocab += [PAD, UNK, START, END]return {token: index for index, token in enumerate(sorted(vocab))}
def caption_tokens_to_indices(captions, vocab):return [[[vocab[START]] + [vocab[word] if word in vocab else vocab[UNK] for word in split_sentence(sentence)] + [vocab[END]] for sentence in examples]for examples in captions]#res = [[[vocab[START]] + [vocab[token] if token in vocab else vocab[UNK] for token in split_sentence(sentence)] + [vocab[END]] for sentence in caption] for caption in captions]# prepare vocabulary
vocab = generate_vocabulary(train_captions)
vocab_inverse = {idx: w for w, idx in vocab.items()}
print('length of vocab =',len(vocab))
#print(vocab)
#print(vocab_inverse)length of vocab = 8769
# replace tokens with indices
train_captions_indexed = caption_tokens_to_indices(train_captions, vocab)
val_captions_indexed = caption_tokens_to_indices(val_captions, vocab)#print(train_captions_indexed)Captions have different length, but we need to batch them, that’s why we will add PAD tokens so that all sentences have an euqal length.
We will crunch LSTM through all the tokens, but we will ignore padding tokens during loss calculation.
# we will use this during training
def batch_captions_to_matrix(batch_captions, pad_idx, max_len=None):"""`batch_captions` is an array of arrays:[[vocab[START], ..., vocab[END]],[vocab[START], ..., vocab[END]],...]Put vocabulary indexed captions into np.array of shape (len(batch_captions), columns),where "columns" is max(map(len, batch_captions)) when max_len is Noneand "columns" = min(max_len, max(map(len, batch_captions))) otherwise.Add padding with pad_idx where necessary.Input example: [[1, 2, 3], [4, 5]]Output example: np.array([[1, 2, 3], [4, 5, pad_idx]]) if max_len=NoneOutput example: np.array([[1, 2], [4, 5]]) if max_len=2Output example: np.array([[1, 2, 3], [4, 5, pad_idx]]) if max_len=100Try to use numpy, we need this function to be fast!"""matrix = []for sentence in batch_captions:#print(sentence)if max_len == None:columns = max(map(len, batch_captions))else:columns = min(max_len, max(map(len, batch_captions)))if len(sentence) >= columns:row = sentence[0:columns]else:extra = columns - len(sentence)row = sentence + [pad_idx] * extra#print(row)matrix.append(row)matrix_np = np.array(matrix, dtype = int)#print(matrix_np)return matrix_np## GRADED PART, DO NOT CHANGE!
# Vocabulary creation
grader.set_answer("19Wpv", grading_utils.test_vocab(vocab, PAD, UNK, START, END))
# Captions indexing
grader.set_answer("uJh73", grading_utils.test_captions_indexing(train_captions_indexed, vocab, UNK))
# Captions batching
grader.set_answer("yiJkt", grading_utils.test_captions_batching(batch_captions_to_matrix))# you can make submission with answers so far to check yourself at this stage
grader.submit(COURSERA_EMAIL, COURSERA_TOKEN)You used an invalid email or your token may have expired. Please make sure you have entered all fields correctly. Try generating a new token if the issue still persists.
# make sure you use correct argument in caption_tokens_to_indices
assert len(caption_tokens_to_indices(train_captions[:10], vocab)) == 10
assert len(caption_tokens_to_indices(train_captions[:5], vocab)) == 5Training
Define architecture
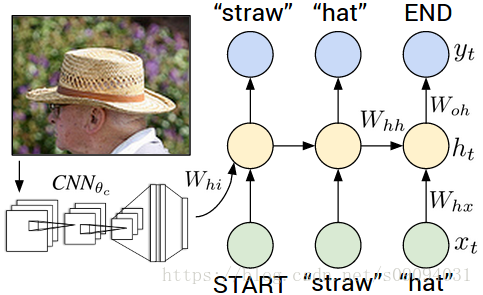
Since our problem is to generate image captions, RNN text generator should be conditioned on image. The idea is to use image features as an initial state for RNN instead of zeros.
Remember that you should transform image feature vector to RNN hidden state size by fully-connected layer and then pass it to RNN.
During training we will feed ground truth tokens into the lstm to get predictions of next tokens.
Notice that we don’t need to feed last token (END) as input (http://cs.stanford.edu/people/karpathy/):
IMG_EMBED_SIZE = train_img_embeds.shape[1]
IMG_EMBED_BOTTLENECK = 120
WORD_EMBED_SIZE = 100
LSTM_UNITS = 300
LOGIT_BOTTLENECK = 120
pad_idx = vocab[PAD]# remember to reset your graph if you want to start building it from scratch!
tf.reset_default_graph()
tf.set_random_seed(42)
s = tf.InteractiveSession()print(IMG_EMBED_SIZE)2048
Here we define decoder graph.
We use Keras layers where possible because we can use them in functional style with weights reuse like this:
dense_layer = L.Dense(42, input_shape=(None, 100) activation='relu')
a = tf.placeholder('float32', [None, 100])
b = tf.placeholder('float32', [None, 100])
dense_layer(a) # that's how we applied dense layer!
dense_layer(b) # and againHere’s a figure to help you with flattening in decoder:
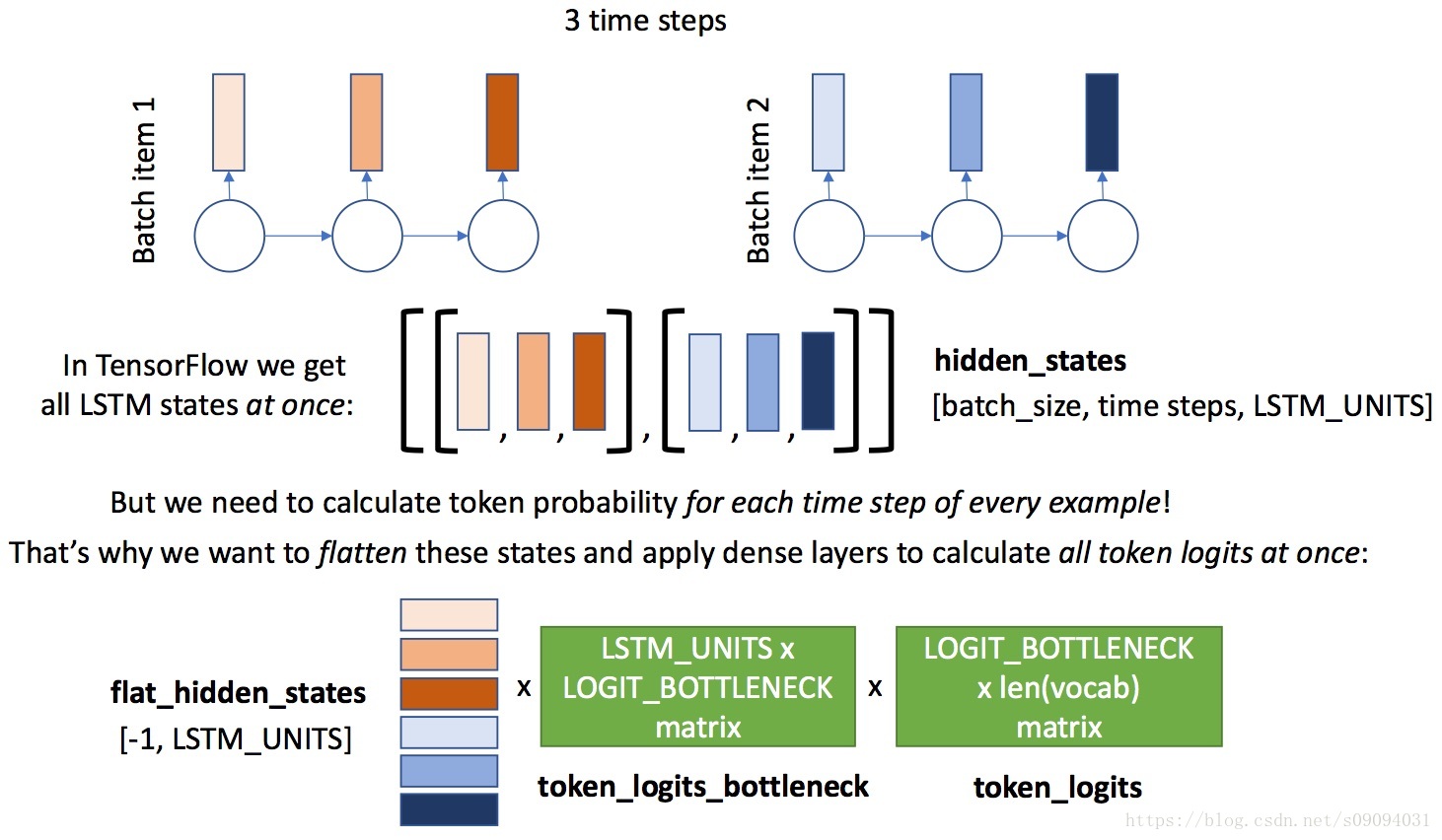
class decoder:# [batch_size, IMG_EMBED_SIZE] of CNN image featuresimg_embeds = tf.placeholder('float32', [None, IMG_EMBED_SIZE])# [batch_size, time steps] of word idssentences = tf.placeholder('int32', [None, None])# we use bottleneck here to reduce the number of parameters# image embedding -> bottleneckimg_embed_to_bottleneck = L.Dense(IMG_EMBED_BOTTLENECK, input_shape=(None, IMG_EMBED_SIZE), activation='relu')# image embedding bottleneck -> lstm initial stateimg_embed_bottleneck_to_h0 = L.Dense(LSTM_UNITS,input_shape=(None, IMG_EMBED_BOTTLENECK),activation='relu')# word -> embeddingword_embed = L.Embedding(len(vocab), WORD_EMBED_SIZE)# lstm cell (from tensorflow)lstm = tf.nn.rnn_cell.LSTMCell(LSTM_UNITS)# we use bottleneck here to reduce model complexity# lstm output -> logits bottlenecktoken_logits_bottleneck = L.Dense(LOGIT_BOTTLENECK, input_shape=(None, LSTM_UNITS),activation="relu")# logits bottleneck -> logits for next token predictiontoken_logits = L.Dense(len(vocab),input_shape=(None, LOGIT_BOTTLENECK))# initial lstm cell state of shape (None, LSTM_UNITS),# we need to condition it on `img_embeds` placeholder.c0 = h0 = img_embed_bottleneck_to_h0(img_embed_to_bottleneck(img_embeds))# embed all tokens but the last for lstm input,# remember that L.Embedding is callable,# use `sentences` placeholder as input.word_embeds = word_embed(sentences[:,:-1])# during training we use ground truth tokens `word_embeds` as context for next token prediction.# that means that we know all the inputs for our lstm and can get # all the hidden states with one tensorflow operation (tf.nn.dynamic_rnn).# `hidden_states` has a shape of [batch_size, time steps, LSTM_UNITS].hidden_states, _ = tf.nn.dynamic_rnn(lstm, word_embeds,initial_state=tf.nn.rnn_cell.LSTMStateTuple(c0, h0))# now we need to calculate token logits for all the hidden states# first, we reshape `hidden_states` to [-1, LSTM_UNITS]flat_hidden_states = tf.reshape(hidden_states,[-1, LSTM_UNITS])### YOUR CODE HERE #### then, we calculate logits for next tokens using `token_logits_bottleneck` and `token_logits` layersflat_token_logits = token_logits(token_logits_bottleneck(flat_hidden_states))### YOUR CODE HERE #### then, we flatten the ground truth token ids.# remember, that we predict next tokens for each time step,# use `sentences` placeholder.flat_ground_truth = tf.reshape(sentences[:,1:], [-1,])### YOUR CODE HERE #### we need to know where we have real tokens (not padding) in `flat_ground_truth`,# we don't want to propagate the loss for padded output tokens,# fill `flat_loss_mask` with 1.0 for real tokens (not pad_idx) and 0.0 otherwise.flat_loss_mask = tf.not_equal(pad_idx, flat_ground_truth)### YOUR CODE HERE #### compute cross-entropy between `flat_ground_truth` and `flat_token_logits` predicted by lstmxent = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=flat_ground_truth, logits=flat_token_logits)# compute average `xent` over tokens with nonzero `flat_loss_mask`.# we don't want to account misclassification of PAD tokens, because that doesn't make sense,# we have PAD tokens for batching purposes only!loss = tf.reduce_mean(tf.boolean_mask(xent, flat_loss_mask)) ### YOUR CODE HERE #### define optimizer operation to minimize the loss
optimizer = tf.train.AdamOptimizer(learning_rate=0.001)
train_step = optimizer.minimize(decoder.loss)# will be used to save/load network weights.
# you need to reset your default graph and define it in the same way to be able to load the saved weights!
saver = tf.train.Saver()# intialize all variables
s.run(tf.global_variables_initializer())/opt/conda/lib/python3.6/site-packages/tensorflow/python/ops/gradients_impl.py:93: UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape. This may consume a large amount of memory."Converting sparse IndexedSlices to a dense Tensor of unknown shape. "
## GRADED PART, DO NOT CHANGE!
# Decoder shapes test
grader.set_answer("rbpnH", grading_utils.test_decoder_shapes(decoder, IMG_EMBED_SIZE, vocab, s))
# Decoder random loss test
grader.set_answer("E2OIL", grading_utils.test_random_decoder_loss(decoder, IMG_EMBED_SIZE, vocab, s))# you can make submission with answers so far to check yourself at this stage
grader.submit(COURSERA_EMAIL, COURSERA_TOKEN)You used an invalid email or your token may have expired. Please make sure you have entered all fields correctly. Try generating a new token if the issue still persists.
Training loop
Evaluate train and validation metrics through training and log them. Ensure that loss decreases.
train_captions_indexed = np.array(train_captions_indexed)
val_captions_indexed = np.array(val_captions_indexed)# generate batch via random sampling of images and captions for them,
# we use `max_len` parameter to control the length of the captions (truncating long captions)
def generate_batch(images_embeddings, indexed_captions, batch_size, max_len=None):"""`images_embeddings` is a np.array of shape [number of images, IMG_EMBED_SIZE].`indexed_captions` holds 5 vocabulary indexed captions for each image:[[[vocab[START], vocab["image1"], vocab["caption1"], vocab[END]],[vocab[START], vocab["image1"], vocab["caption2"], vocab[END]],...],...]Generate a random batch of size `batch_size`.Take random images and choose one random caption for each image.Remember to use `batch_captions_to_matrix` for padding and respect `max_len` parameter.Return feed dict {decoder.img_embeds: ..., decoder.sentences: ...}."""random_idx_batch = np.random.choice(range(len(images_embeddings)), batch_size, replace= False)batch_image_embeddings = images_embeddings[random_idx_batch]### YOUR CODE HERE ###batch_captions_matrix = [caption[np.random.randint(5)] for caption in indexed_captions[random_idx_batch]]### YOUR CODE HERE ###batch_captions_matrix = batch_captions_to_matrix(batch_captions_matrix, pad_idx, max_len=max_len)return {decoder.img_embeds: batch_image_embeddings, decoder.sentences: batch_captions_matrix}batch_size = 64
n_epochs = 12
n_batches_per_epoch = 1000
n_validation_batches = 100 # how many batches are used for validation after each epoch# you can load trained weights here
# you can load "weights_{epoch}" and continue training
# uncomment the next line if you need to load weights
saver.restore(s, os.path.abspath("weights_11"))INFO:tensorflow:Restoring parameters from /home/jovyan/work/week6/weights_11
Look at the training and validation loss, they should be decreasing!
# actual training loop
MAX_LEN = 20 # truncate long captions to speed up training# to make training reproducible
np.random.seed(42)
random.seed(42)for epoch in range(n_epochs):train_loss = 0pbar = tqdm.tqdm_notebook(range(n_batches_per_epoch))counter = 0for _ in pbar:train_loss += s.run([decoder.loss, train_step], generate_batch(train_img_embeds, train_captions_indexed, batch_size, MAX_LEN))[0]counter += 1pbar.set_description("Training loss: %f" % (train_loss / counter))train_loss /= n_batches_per_epochval_loss = 0for _ in range(n_validation_batches):val_loss += s.run(decoder.loss, generate_batch(val_img_embeds,val_captions_indexed, batch_size, MAX_LEN))val_loss /= n_validation_batchesprint('Epoch: {}, train loss: {}, val loss: {}'.format(epoch, train_loss, val_loss))# save weights after finishing epochsaver.save(s, os.path.abspath("weights_{}".format(epoch)))print("Finished!")Epoch: 0, train loss: 2.586510482311249, val loss: 2.7041056823730467Epoch: 1, train loss: 2.559947569131851, val loss: 2.6480031490325926Epoch: 2, train loss: 2.551668902397156, val loss: 2.6677986073493956Epoch: 3, train loss: 2.523633302927017, val loss: 2.661551821231842Epoch: 4, train loss: 2.514521197080612, val loss: 2.657930402755737Epoch: 5, train loss: 2.5018435039520264, val loss: 2.6460987234115603Epoch: 6, train loss: 2.4804200737476347, val loss: 2.6443699979782105Epoch: 7, train loss: 2.4685235941410064, val loss: 2.638700065612793Epoch: 8, train loss: 2.4603914411067964, val loss: 2.6080277347564698Epoch: 9, train loss: 2.4436668586730956, val loss: 2.62331796169281Epoch: 10, train loss: 2.4294585037231444, val loss: 2.6152796459198Epoch: 11, train loss: 2.423172189950943, val loss: 2.6170984268188477
Finished!
## GRADED PART, DO NOT CHANGE!
# Validation loss
grader.set_answer("YJR7z", grading_utils.test_validation_loss(decoder, s, generate_batch, val_img_embeds, val_captions_indexed))# you can make submission with answers so far to check yourself at this stage
grader.submit(COURSERA_EMAIL, COURSERA_TOKEN)# check that it's learnt something, outputs accuracy of next word prediction (should be around 0.5)
from sklearn.metrics import accuracy_score, log_lossdef decode_sentence(sentence_indices):return " ".join(list(map(vocab_inverse.get, sentence_indices)))def check_after_training(n_examples):fd = generate_batch(train_img_embeds, train_captions_indexed, batch_size)logits = decoder.flat_token_logits.eval(fd)truth = decoder.flat_ground_truth.eval(fd)mask = decoder.flat_loss_mask.eval(fd).astype(bool)print("Loss:", decoder.loss.eval(fd))print("Accuracy:", accuracy_score(logits.argmax(axis=1)[mask], truth[mask]))for example_idx in range(n_examples):print("Example", example_idx)print("Predicted:", decode_sentence(logits.argmax(axis=1).reshape((batch_size, -1))[example_idx]))print("Truth:", decode_sentence(truth.reshape((batch_size, -1))[example_idx]))print("")check_after_training(3)# save graph weights to file!
saver.save(s, os.path.abspath("weights"))Applying model
Here we construct a graph for our final model.
It will work as follows:
- take an image as an input and embed it
- condition lstm on that embedding
- predict the next token given a START input token
- use predicted token as an input at next time step
- iterate until you predict an END token
class final_model:# CNN encoderencoder, preprocess_for_model = get_cnn_encoder()saver.restore(s, os.path.abspath("weights")) # keras applications corrupt our graph, so we restore trained weights# containers for current lstm statelstm_c = tf.Variable(tf.zeros([1, LSTM_UNITS]), name="cell")lstm_h = tf.Variable(tf.zeros([1, LSTM_UNITS]), name="hidden")# input imagesinput_images = tf.placeholder('float32', [1, IMG_SIZE, IMG_SIZE, 3], name='images')# get image embeddingsimg_embeds = encoder(input_images)# initialize lstm state conditioned on imageinit_c = init_h = decoder.img_embed_bottleneck_to_h0(decoder.img_embed_to_bottleneck(img_embeds))init_lstm = tf.assign(lstm_c, init_c), tf.assign(lstm_h, init_h)# current word indexcurrent_word = tf.placeholder('int32', [1], name='current_input')# embedding for current wordword_embed = decoder.word_embed(current_word)# apply lstm cell, get new lstm statesnew_c, new_h = decoder.lstm(word_embed, tf.nn.rnn_cell.LSTMStateTuple(lstm_c, lstm_h))[1]# compute logits for next tokennew_logits = decoder.token_logits(decoder.token_logits_bottleneck(new_h))# compute probabilities for next tokennew_probs = tf.nn.softmax(new_logits)# `one_step` outputs probabilities of next token and updates lstm hidden stateone_step = new_probs, tf.assign(lstm_c, new_c), tf.assign(lstm_h, new_h)# look at how temperature works for probability distributions
# for high temperature we have more uniform distribution
_ = np.array([0.5, 0.4, 0.1])
for t in [0.01, 0.1, 1, 10, 100]:print(" ".join(map(str, _**(1/t) / np.sum(_**(1/t)))), "with temperature", t)# this is an actual prediction loop
def generate_caption(image, t=1, sample=False, max_len=20):"""Generate caption for given image.if `sample` is True, we will sample next token from predicted probability distribution.`t` is a temperature during that sampling,higher `t` causes more uniform-like distribution = more chaos."""# condition lstm on the images.run(final_model.init_lstm, {final_model.input_images: [image]})# current caption# start with only START tokencaption = [vocab[START]]for _ in range(max_len):next_word_probs = s.run(final_model.one_step, {final_model.current_word: [caption[-1]]})[0]next_word_probs = next_word_probs.ravel()# apply temperaturenext_word_probs = next_word_probs**(1/t) / np.sum(next_word_probs**(1/t))if sample:next_word = np.random.choice(range(len(vocab)), p=next_word_probs)else:next_word = np.argmax(next_word_probs)caption.append(next_word)if next_word == vocab[END]:breakreturn list(map(vocab_inverse.get, caption))# look at validation prediction example
def apply_model_to_image_raw_bytes(raw):img = utils.decode_image_from_buf(raw)fig = plt.figure(figsize=(7, 7))plt.grid('off')plt.axis('off')plt.imshow(img)img = utils.crop_and_preprocess(img, (IMG_SIZE, IMG_SIZE), final_model.preprocess_for_model)print(' '.join(generate_caption(img)[1:-1]))plt.show()def show_valid_example(val_img_fns, example_idx=0):zf = zipfile.ZipFile("val2014_sample.zip")all_files = set(val_img_fns)found_files = list(filter(lambda x: x.filename.rsplit("/")[-1] in all_files, zf.filelist))example = found_files[example_idx]apply_model_to_image_raw_bytes(zf.read(example))show_valid_example(val_img_fns, example_idx=100)# sample more images from validation
for idx in np.random.choice(range(len(zipfile.ZipFile("val2014_sample.zip").filelist) - 1), 10):show_valid_example(val_img_fns, example_idx=idx)time.sleep(1)You can download any image from the Internet and appply your model to it!
download_utils.download_file("http://www.bijouxandbits.com/wp-content/uploads/2016/06/portal-cake-10.jpg","portal-cake-10.jpg"
)apply_model_to_image_raw_bytes(open("portal-cake-10.jpg", "rb").read())Now it’s time to find 10 examples where your model works good and 10 examples where it fails!
You can use images from validation set as follows:
show_valid_example(val_img_fns, example_idx=...)You can use images from the Internet as follows:
! wget ...
apply_model_to_image_raw_bytes(open("...", "rb").read())If you use these functions, the output will be embedded into your notebook and will be visible during peer review!
When you’re done, download your noteboook using “File” -> “Download as” -> “Notebook” and prepare that file for peer review!
### YOUR EXAMPLES HERE ###That’s it!
Congratulations, you’ve trained your image captioning model and now can produce captions for any picture from the Internet!
这篇关于Introduction to Advanced Machine Learning, 第六周,week6_final_project_image_captioning_clean(答案)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







