本文主要是介绍Reinforced History Backtracking for Conversational Question Answering论文翻译,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

公众号 系统之神与我同在
链接如下:
http://link.zhihu.com/?target=https%3A//www.aaai.org/AAAI21Papers/AAAI-1260.QiuM.pdf
对话问答的强化历史追溯
摘要
在多轮对话中对上下文历史建模已成为更好地理解问答系统中的用户查询的关键步骤。为了利用语境历史,大多数现有的研究将整个语境视为输入,这将不可避免地面临以下两个挑战。首先,对长历史进行建模的成本可能很高,因为它需要更多的计算资源。第二,长上下文历史包含许多不相关的信息,这使得对与用户查询相关的适当信息进行建模变的困难。为了缓解这些问题,本文提出了一种基于强化学习的方法来捕获和回溯相关的会话历史,以提高模型的性能。我们的方法寻求利用来自模型性能的隐式反馈自动回溯历史信息。我们还考虑即时奖励和延迟奖励,来指导强化的回溯政策。我们在一个大型回话数据集上进行了大量实验,实验结果表明,我们所提出的方法可以帮助缓解由于较长的上下文历史而产生的问题。实验结果表明,该方法比其它baseline具有更好的性能,并且该方法所采取的行动具有较强的洞察力。
导言
会话问题回答(ConvQA)最近引起了研究界和业界的许多研究人员的兴趣(Choi et ai.2018b;Reddy、Chen和Manning,2018a)。在对话答疑(ConvQA)的情景下,由于对话中经常出现共指和语用省略现象,每轮对话中的当前查询可能不是自成体系的,很大程度上要依赖于对话历史。因此,对话历史建模成为更好地理解查询的关键步骤。现有的大多数作品倾向于使用整个历史作为输入,来对语义变化进行建模,并在单个模型中执行引用解析,例如FlowQA(Huang、Choi和Yih 2018)、FlowDelta(Yeh和Chen 2019)和MC2(Zhang 2019)。最近的最新研究采用历史答案嵌入的方法来补充所有的对话历史(Qu et al.2019a)或问题关注(Qu et ai.2019b),这可以被视为对相关历史选择的一种软选择方式。
然而,如果要使用全部的对话历史,单个模型必然会面临一些挑战。首先,它需要更多的计算资源来合并所有历史的表示,包括相关的和不相关的历史,这对于理解查询可能是不必要的。此外,当采用诸如BERT大的重模型时,这个问题变得更糟,因为需要维护更长的输入序列和全部历史文本。第二,现有以整个历史为输入的模型通常采用基于注意力或门控的机制来选择性地关注不同的历史转折(Yeh和Chen 2019;Huang、Choi和Yih 2018)。然而,对于对话历史上出现的和当前问答无关的部分,这些方法仍然没有取得理想的结果。换句话说,现有方法可以从提取相关历史的额外步骤中获益(现有方法相当于进行了一个提取相关历史的额外步骤,以此提高效果)。
为了缓解上述问题,本文从不同的角度,对会话历史进行有意义的选择。我们的方法的优点是,它可以避免不重要的历史转折的负面影响,从源头上直接不考虑它们。我们把会话问答(ConvQA)任务建模为两个子任务:一个是会话QA任务,使用neuralMRC模型(神经元MRC模型);另一个是使用reinforced backtracker(增强后台跟踪器)的会话历史选择任务。增强后台跟踪器是由会话问题回答(ConvQA)构建的,与环境交互的代理(agent,中介/代理)。
更具体的说,对于每个查询,我们将查找相关历史的过程视为一个连续的决策制定过程。代理根据可用的会话历史进行操作,并逐个跟踪历史问答对,根据观察结果来确定它是否相关/有用。然后,机器阅读理解(MRC)模型根据所选择的历史图来帮助自己回答当前问题,并生成奖励来评估历史选择的效用。然而,由机器阅读理解(MRC)模型生成的奖励是稀疏的,因为它们只能在决策过程结束时获得奖励。针对这一奖励稀疏问题,我们进一步提出了一种新的训练方案,即主体先从只有一个历史转折的例子中学习并抽取代理,再从两个历史的例子中学习抽取代理,以此类推。
随着不相关历史被过滤,机器阅读理解(MRC)模型可以通过更复杂的机制得到更好的训练,并且专注于以更高的精度来寻找历史转折。此外,由于增强后跟踪器是一个单独的模块,所以将来可以灵活地对其进行调整,并利用迁移学习等技术进一步进行改进。
我们的贡献可概括如下:
1.针对会话问答(ConvQA)环境下会话历史建模问题,提出了一种新的解决方案。我们在传统的机器阅读理解(MRC)模型中,加入了一个增强回溯器来过滤不相关的历史图,而不是将历史作为一个整体来评估它们。因此,机器阅读理解(MRC)模型能够集中关注更相关的历史,并获得更好的性能。
我们把会话历史选择问题建模为一个顺序决策过程,该过程可以通过强化学习来解决。通过与预先训练的机器阅读理解(MRC)模型交互,增强后台跟踪器能够生成良好的选择策略。针对稀疏报酬问题,我们进一步地提出了一种新的训练方案。
2.我们在大型会话问题答疑数据集QuAC(Choi等人,2018a)上进行了广泛的实验,结果表明,采用强化学习(RL)学习会话历史选择策略有助于提高回答预测性能。
3.本文的其余部分安排如下。我们首先阐述了会话问题答疑(ConvQA)中的会话历史选择问题,并详细阐述了我们提出的利用强化学习训练回溯策略进行会话历史选择的方法。然后,我们在QuAC数据集上进行了详细的实验。最后,介绍了相关工作并进行了总结。
在本节中,我们首先定义任务,然后介绍我们提出的增强后台跟踪器。
任务定义
我们在对话问题回答(ConvQA)任务之上定义了会话历史选择任务。我们将任务分为两个子任务:会话QA任务和会话历史选择任务。给定当前的问题和对话历史,我们的加固后跟踪器旨在找到最相关的历史题库的子集,以最大化会话问题回答(ConvQA)任务的性能。

模型概述
如图1所示,我们将历史选择问题建模为顺序决策过程。给定当前查询,代理通过状态网络回溯历史,并获得每个对话回合的状态表示。策略网络采取状态表示和最后一个动作来决定该历史转向是否与查询相关。随后,机器阅读理解(MRC)模型使用所选择的历史转折和文章内容作为输入来预测答案跨度。历史选择质量直接影响到答案预测性能。因此,机器阅读理解(MRC)模型能够产生奖赏以评估历史选择的效用。最后,使用奖励来更新策略网络。下面我们将详细介绍状态、代理、环境和奖励。
状态
给定历史转折(Qi,Ai),其状态表示为连续实值向量,其中l是状态向量的维数。第i个选择中的状态向量S是下列特征的级联:
(1)
句子向量 。我们采用VanillaBERT模型生成的单词隐藏表示的平均值作为句子向量,其中BERT的输入是一个句子对:[CLS]QiAi[sep]。
最后行动的向量。我们将最后一个动作嵌入到长度为20的动作向量中。
位置向量V(i)。我们将当前的相对步长嵌入到这个向量中,该向量的作用是注入位置信息。
分段嵌入w。该向量被定义为对应动作为1(表示被选择)的过去句子嵌入的平均值,形式为:
(2)
强化学习Agent
**策略网络。**在给定状态下,我们的策略网络是一个全连接神经网络,定义如下:
(3)
在训练阶段,我们计算动作分布和样本动作。在评价阶段,根据最大概率选择行动。
策略梯度计算如下:
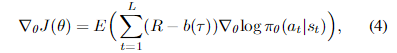
其中b是基线,设计用于减少方差。我们采用一个批次中的平均收益作为基线。R是累积报酬,将在本节中讨论。
行动。由于我们的目标是选择相关的历史回合(turn),代理对于每个回合有两个可能的选项,即,0(忽略)或1(选择)。
给定当前问题Qk,对话历史H′和文章段落P的子集,环境将对话历史添加到当前问题,以将多段对话QA任务转换为单段QA任务。然后,模型预测答案跨度,并产生奖赏以评估历史选择对于预测答案的效用。
本文采用BERT(Devlinet ai.2018)作为机器阅读理解模型。BERT的输入定义为:
[CLS]Qk[SEP]H′[sep]P[sep],其中Qk和P指当前的第k个问题和段落,H′是所选历史回合的集合。我们将BERT的输出表示为,其中L是通道长度,Dm是向量的维数。在形式上,我们预测答案的开始和结束位置如下:
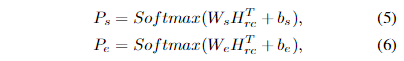
其中,其中s代表开始,e代表结束。
奖励
我们的目标是通过代理选择的输入,来最大化MRC模型的精确率(accuracy)。因此,一种直观的方法是采用预测 答案和最佳答案之间的词集F1分数(word-level F1 score)作为我们的奖励R。如果输入的信息不足以让模型正确预测答案,那么F1分数可能会很低。在形式上,F1分数的定义如下:
其中P是预测答案中与最佳回答(真实回答)重叠的比例,R是最佳答案中计数的重叠百分比。然后,我们将延迟奖励定义为模型更新后的F1分数的差异,即:。
注意,上述F1分数用作延迟奖励,因为它是在所有历史回合的所有选择操作之后获得的。这种稀疏的奖励对加强学习(RL)策略带来了挑战。因此,我们进一步考虑将即时奖励纳入所有行动,以帮助强化学习(RL)训练。我们记历史句子的表示为,以及第i步的行动为ai;。然后,即时奖励定义为当前句子向量和历史片段嵌入之间的相似度,见公式2。我们的想法是,我们应该鼓励模型添加一个接近历史片段嵌入的句子,因为它可以提供连贯的信息帮助历史建模。形式上,我们有:
(8)
其中sign(·)在ai==1时为1,其他情形下等于-1。显然,当行动为1时,当前句子越接近片段输入,得到的奖励就越高。
最终阶段i得到的奖励如下:
(9)
其中为折现因子,T为最后一步的标记。
算法
如图1所示,我们的方法由三个模块组成:使用vanillaBERT的状态网络、策略网络(即代理)和预训练的机器阅读理解(MRC)模型。状态网络输出状态表示,提供给策略网络来进行历史回溯动作。然后将所得到的历史回合和用户问题反馈给机器阅读理解(MRC)模型,得到预测结果。策略网络是根据基于预测回答和真实回答所计算的奖励来进行更新的。对于状态网络,我们采用Github上的预训练模型(https://github.com/google-research/bert),并冻结其权重。我们使用REINFORCE算法(Williams1992)更新代理策略。在算法1中给出了详细的算法。

训练方案 受课程学习启发(Ben-gio et ai.2009),我们考虑逐步增加学习难度,以帮助强化学习(RL)代理进行训练。代理首先从只有一个历史的剧集中学习策略,这可以看作是一个简化的选择过程。然后,我们增加章节的长度,以帮助代理开发其上下文建模策略。
实验
数据集
我们在QuAC数据集上进行了实验。QuAC是一个多回合互动的机器阅读理解任务,当前的问题通常指的是对话历史。一些对话经常会出现话题转移、钻入、话题返回等现象。数据集中主要有10万个问题和1万条对话。对话的最高回合是12轮。
我们还在另外一个Canard数据集上评估了这些方法。这个数据集包含基于上下文历史记录人工生成的问题,可以作为上下文建模的基础。此数据集可帮助检查竞争性方法是否具有选择适当的上下文历史,以生成接近人工生成的问题的高质量重写问题的能力。
评价指标 QuAC挑战提供了两个评价指标,即单词的F1分数和人类等价分数(HEQ)。单词的F1分数评估预测答案和真实回答跨度的重叠。它是(会话)机器理解任务中使用的经典度量(Rajpurkar et ai.2016;Reddy、Chen和Manning,2018b)。人类等价分数(HEQ)测量系统的F1分数超过或匹配人类的F1分数的例子的百分比。直观地,这个度量指标评价了机器是否能够提供像普通人一样好的答案。这个评价指标是在问题级别(HEQQ)和对话级别(HEQD)上计算的。
环境
我们在以下不同的环境中测试我们的方法。我们采用相同的模型结构,但是输入和训练的语料库不同。
Env-ST(Single Turn) 我们把在QuAC数据集的第一轮对话中训练单句机器阅读理解(MRC)模型的方法叫做Env-ST。这是为了避免引入对话历史对MRC模型所带来的影响。注意,例子的数量与 QuAC 中的对话数量相同。培训数据集有11, 567个例子。
Env-Canard(Canard Dataset)) 由于Canard数据集是基于历史回合重新编写的问题,因此它可以作为研究不同历史建模策略的完美环境。我们研究了以Canard为Env-Canard对机器阅读理解模型的训练方法。它有约31k个训练例子。
Env-ConvQA(Multi-turn) 我们把将最新的历史问答对附加到当前问题上的方法称为Env-ConvQA。形式上,当前的问题Qk及其最新的8个历史回合被连接成新的长问题,然后作为模型的输入。此方法是一个强大的baseline,如(Zhu, Zeng, andHuang 2018; Ju et al. 2019)所示。
基线
我们将我们的方法和最近关于Con-vQA的研究(Choi et al. 2018a; Qu et al. 2019b,a).进行了比较。注意,这些研究可以被视为我们方法的变体,在这里我们定义了一个基于规则的策略来选择最新的k个历史问答对。因此,这些变体表示为Rule-K,其中K是所选历史对的数量。
选择的必要性
如先前的研究(Yatskar 2019)所示,话题转移和主题重述在对话中是常见的,因此有必要在模型中加入历史回合。但仍然存在一个问题:是否加入的历史回合越多,模型的表现就越好?
为了检验这一点,我们使用了不同的历史回合来训练Conv-QA模型。如表1所示,当我们附加8个历史回合而不是4个历史回合时,性能将提高,但当我们添加最新的12个历史回合时,性能将会降低。一般而言,纳入适当的历史回合是有益的。历史合并对建模也带来了挑战,因此合并更多的历史回合并非总是更好。这背后的潜在原因是:1)信息冲突。模型很难自动捕获相关部分之间的依赖关系。2)长度限制。预训练的BERT模型的长度限制为512。添加的历史回合越多,就需要截断越多的通道或历史项以适应模
表1:模型在Conv-QA上的性能,此处我们将k个历史回合添加到当前问题的后面。表中展示了k={0,4,8,12}时,在测试数据集上5次运行得到的平均结果。
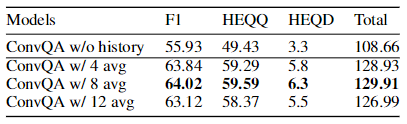
表2:模型在Env-Canard上的性能。
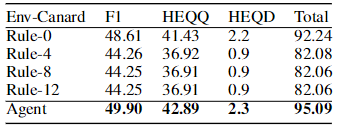
表3:单回合环境下的模型性能(Env-ST)。
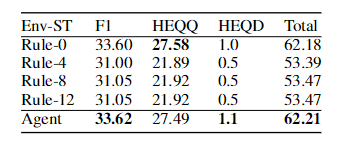
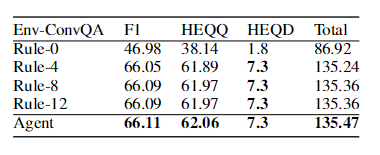
表4:模型在定制的 Env-ConvQA 上的性能,使用了与 Env-Canard 相同的训练样本,但没有重新编写的问题。
型,这使得模型难以从输入中提取关键信息。这激励我们考虑历史选择以进一步改进模型性能。
强化学习vs规则策略
在本节中,我们的目的是检验我们的强化学习方法的益处。如上所述,我们在Env-ConvQA、Env-ST 和 Env-Canard 三个环境中进行强化学习。
如表2所示,我们比较了代理学习和规则策略的不同设置的性能。对于Env-Canard,训练样本为人工重写的问题,这可以被视为一个不需要历史建模的良好环境。我们使用这样的环境来检查附加历史对如何影响模型性能。我们可以看到,在没有历史记录的Rule-0策略下模型可以达到最佳的性能。随着历史的增加,规则4、规则8和规则12的性能开始急剧下降。这是直观的,因为没有历史的重写问题已经包含所有有用的信息,更多的历史回合可能带来更多的噪声信息,这使得建模更具挑战性。在应用我们的方法后,性能有了很大的提高。这表明我们的代理可以帮助回溯有用的历史回合以获得更好的性能,即从历史回合中挖掘有用的信息。令人惊讶的是,我们的方法甚至优于Rule-0,这表明我们的方法有跟踪更多有用的信息来进一步增强人工编制的问题的潜力。
我们在Env-ST上进一步测试我们的方法,以检查如果没有提供重写数据集的有效性。如表3所示,所有模型性能急剧下降。其原因是,如果没有一个完美的环境,强化学习(RL)和基于规则的代理性能就不那么令人满意。但是,我们的方法仍然可以提高所有基于规则的代理的性能,这显示了我们策略的有效性。
我们还报告了我们的Env-ConvQA代理的结果,在没有重写问题的情况下检查了数据集上的模型性能。注意,为了与 Env-Canard 进行公平比较,Env-ConvQA 被裁剪成只包含与 Env-Canard 相同的训练样本,而不包含重写的问题。如表4所示,添加越多的历史回合,规则策略获得的性能就越好。但当我们附加到8个历史回合时,模型性能就停止增长了。这进一步呼应了我们的发现,即把更长的历史回合纳入其中并不总是更好的。尽管如此,在应用我们的强化学习方案时,由于其历史选择策略,模型性能可以进一步提高。
简而言之,我们发现,在对话问题回答(ConvQA)中纳入更多的历史回合并非总是更好,因为较长的历史对历史建模带来了新的挑战。然后,我们提出一种历史选择策略来缓解这个问题,并检验所提出的方法在三个环境中的有效性。以上结果表明,我们的方法始终优于竞争基线,证明了本方法的优越性。
我们的学习方案与片段学习(Episode Learning)的比较
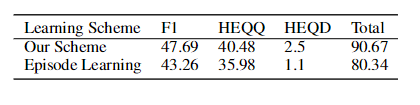
回想一下,我们的训练方案是受到课程学习(curriculumlearning)(Bengio et al. 2009)的启发,我们首先从只有一个历史的例子中学习策略,然后从有两个历史回合的例子中学习策略,以此类推。表5:在完整的Env-Canard语料库上采用不同的强化学习过程。
本节我们探讨训练计划的有效性。
如表5所示,我们对不同的学习方法进行了实验。使用Episode leaming的代理程序以数据集中出现的自然顺序与环境交互。我们可以看出,训练方案的效果比episode learning要好得多。一个潜在的原因是,训练方案能够提供一个预热的开始阶段(warn start),因为它首先从具有较少历史回合的实例中学习策略,然后从具有较多历史回合的实例中学习策略。它可以看作是一个学生学习从简单的课程到困难的课程。
本文方法与其他会话问答方法的比较
我们将我们的Env-ConvQA方法与以下最先进的会话问答方法(ConvQA)进行比较:
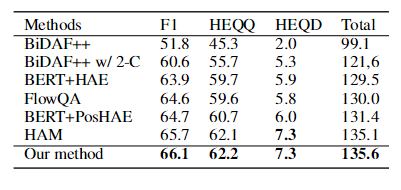
BiDAF++:一个没有历史记录的经典会话问答模型(ConvQA)(Choiet al. 2018a)。
· BiDAF++w/2-C:有两个历史回合的BiDAF++。
· FlowQA:具有历史流模型的会话问答模型(ConvQA)( Huang, Choi, and tau Yih 2018 8)。
· BERT+HAE:最近提出的具有历史建模的对话问答模型(ConvQA) (Qu et al. 2019b)。
· BERT+Poshae:一种基于BERT+HAE的改进方法(Qu et ai.2019b)。
· HAM:历史关注建模的最新研究(Qu et ai.2019c)。
注意,我们在这里省略了考虑迁移学习或数据增强的方法的比较,因为这些研究使用了外部数据。我们将用外部数据增强方法的研究留作今后的工作。
如表6所示,我们的方法在F1、HEQD中获得最佳性能,并且在总分中赢得第一名。我们的方法比最近参加HAM模型的历史成绩高出0.4分。鉴于这项任务极具挑战性,这一改进是不小的。这进一步说明我们选择相关历史回合的策略优于其它方法。
表6:我们的方法和最先进的会话问题回答(ConvQA)方法的比较
个案研究
我们从QuAC中的开发数据集中抽取两个示例,并可视化代理所做的操作。
如表7所示,它在一次对话中列出了两个后续的问题。上半部分展示了一个问题:“这篇文章还有什么有趣的吗?”代理认为所有历史都是相关的,因为代理所进行的操作都是单独的。在最下面的部分,给出一个问题,“他们快要解决它了吗?”我们发现“它”一词指的是最后提到的事件。有意思的是,代理只选择最后一回合作为最相关的部分,这是合理的。这是直观的,对于回答第一个问题,代理需要关注所有的历史,而对于第二个问题,只需要最新的信息。尽管这两个问题的历史几乎相同,但是增强学习(RL)代理能够根据给定的问题做出不同的选择。这表明我们的强化学习(RL)代理可以选择性地回溯会话历史来帮助会话问题回答(ConvQA)任务。
相关工作
我们的任务与机器阅读理解、对话以及强化学习有关。

机器阅读理解(MRC)与对话问答。机器阅读理解是自然语言理解的核心部分。许多高质量的挑战和数据集(Rajpurkar et ai.2016;Rajpurkar, Jia, and Liang 2018;Nguyen et ai.2016;Joshi et ai.2017;Kwiatkowski et ai.2019)极大地促进了这一领域的研究进展,产生了广泛的模型架构(Seoetal.2016;Huetal.2018;Wang et Gardai.2017;机器阅读理解(MRC)任务通常以单轮QA方式进行。目标是通过预测给定段落中的答案范围来回答问题。在CoQA(Reddy、Chen和Manning 2018b)和QuAC(Choi等人,2018a)中制定的会话问题回答(ConvQA)任务与机器阅读理解(MRC)任务密切相关。一个主要区别是,会话问题回答(ConvQA)中的问题是在交谈中组织的。因此,我们需要把对话历史融入其中,以便更好地理解当前的问题。大多数方法试图将对话历史建模纳入段落表达的过程。FlowQA(Huang, Choi, Yih 2018)采用RNN转换过去的段落表示。FlowDelta(Yeh和Chen 2019)寻求使用delta操作来模拟相对回合中的变化。GraphFlow(Chen、Wu和Zaki 2019)将文章中的每个词视为节点,使用关注度得分作为它们的连接,然后采用门控机制来融合过去和当前的表示。MC2(Zhang 2019)提出在FlowQA的基础上,从多个角度使用CNN来捕获语义变化。另一方面,采用历史答案嵌入的方法也很有竞争力。HAE(Qu et ai.2019a)采用答案嵌入的方法来指示历史答案的位置。 HAM(Qu et ai.2019b)进一步采用注意力机制来选择相关的历史问题。
表7:来自QuAC开发数据集的两个例子。尽管有类似的对话历史(相同的历史从0变为4),但RL代理对每个对话回合的行为都不同
强化学习(RL)。强化学习(RL)包括一系列面向目标的算法,这些算法已经在许多学科中研究了几十年(Sutton和Barto 1998;Arulkumaran等人,2017;Li 2017)。近期的深入学习发展为这一领域做出了巨大贡献,并在许多领域取得了惊人的成就,如与人类玩游戏(Mnih等人,2013年;Silver等人,2017年)。加强学习(RL)有两种工作方式:基于价值的方法和基于策略的方法。基于价值的方法,包括SARSA(Rummery和Niranjan 1994)和Deep Q网络(Mnih等人,2015年),根据对预期长期回报的估计采取行动。另一方面,基于策略的方法优化了策略,可以将状态映射到承诺最高回报的行动。最后,混合方法,例如演员-批评者算法(Konda和Tsitsiklis 2003),将经过训练的价值估计器集成到基于策略的方法中,以减少奖励和梯度中的方差。我们在工作中主要采用混合方法进行实验。
强化学习(RL)问题的本质是根据特定的观察进行一系列的行动,以实现一个长期的目标。这种性质使得强化学习(RL)适合于处理许多领域的数据选择问题((Fang, Li, andCohn 2017; Wu, Li, and Wang 2018; Fan et al. 2017; Patel,Chitta, and Jasani 2018; Wang et al. 2018; Feng et al. 2018)。(Takanobu et ai.2018)采用强化学习进行主题分割。(Buck et ai.2018)采用强化学习产生质量更好的问题。
我们提出的方法寻求识别有用的会话历史以建立更好的训练数据。据我们所知,我们的工作是第一个在研究会话问题回答(ConvQA)中回溯历史回合的强化学习。我们提出的方法是一种端到端的可训练方法,比竞争基线具有更好的结果。
结论
在本文中,我们提出了一种强化学习的方法来自动选择相关的历史转折,用于多转折机的阅读理解。在公共数据集上的大量实验表明,我们的方法始终比其他方法具有更好的性能。我们试图检验我们的RL方法的泛化能力,以便在未来的对话建模中有更多的上下文感知应用致谢
这项工作部分由国家自然科学基金项目(61402403、62072399)、阿里巴巴-浙江大学联合前沿技术研究所、中国工程科学技术知识中心、教育部数字图书馆工程研究中心以及中央大学基础研究基金赞助。本材料中表达的任何意见、调查结果和结论或建议都是作者的意见、调查结果和结论或建议,不一定反映提案国的意见、调查结果和结论或建议。
这篇关于Reinforced History Backtracking for Conversational Question Answering论文翻译的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

