本文主要是介绍【学习日记week5】基于掩蔽的学习方法和跨模态动量对比学习方法(Masked Language Modeling Cross-modal MCL),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
序言
首先先review一篇师兄最近看的CVPR23的文章,这歌内容很有意思,通过Bert进行推理来构建类Masked Language,然后对其进行学习。
ViLEM: Visual-Language Error Modeling for Image-Text Retrieval(CVPR 23)
序言
ViLEM:是指视觉语言的错误建模。这个工作是基于ITC的基础上的。
Motivation & Contribution

首先调研整个跨模态检索&图文匹配问题的方法论,之前主流的工作都采用多重编码器的结构,这一类方法通过学习一个联合的嵌入空间,来进行粗粒度的对齐,对图文全局特征进行学习。很显然,有的时候需要更细粒度的对齐才能有更好的效果。
对于人类来说,人类可以通过分辨具体的不同模态信息之间是否有不同的内容来做到准确的图文匹配(比如,一张图片里面只有猫,那这样无论其他信息讲得再贴切,如果描述的内容是狗,那也一定是错的)。于是本文有了Motivation,提出了“基于错误进行学习”的学习方式ViLEM,这个方法强制地让模型来分辨并且消除局部的语义相歧的部份。最终使ViLEM和ITC模块一起联合地一起工作,来增强原本的多重编码器的结构。
比起“一个模型”,我认为ViLEM更像是一个学习策略。
ViLEM被分成了两个子任务:检错和纠错。检错的目标是在自然的语言中基于图像来找出错误的词(非常细粒度),然后用二分类01的方式来判断词语是否是正确的。对自然语言做人工标注或处理是较为麻烦的,所以采用了BERT来完成这个任务。此外,ViLEM也采用了多粒度的互动框架来让视觉和语言的encoders进行交互,且保持着高的检索性能。
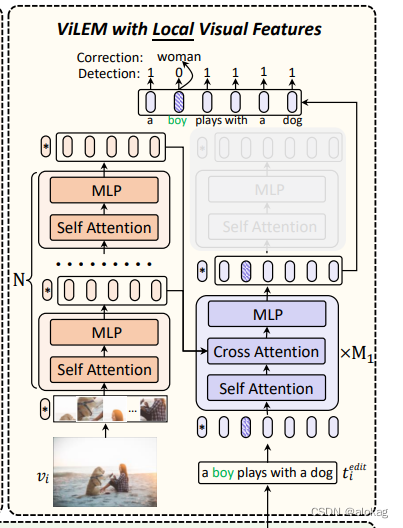
具体的说,全局视觉特征和本地视觉信息都会被用来进行错误检错与修正。对于全局的特征,采用直接将其注入到本地文本表示的方法,对于局部特征,直接采用Cross Attention的方法来进行融合。在推理中将删除交叉注意力模块,并不需要额外的计算成本和参数。
综合以上,有如下contribution:
- 提出了ViLEM,基于双编码器来进行跨模态语义关联学习。
- 提出了多粒度的交互框架来进行学习
- 做了大量实验
相关工作
这里不详细描述,主要讲一下有关错误纠正以及MLM任务的。MLM任务是一个我认为对我近期工作特别有帮助的多模态任务
文本错误校正有一个重要的应用领域,即语法错误校正(GEC),但这个跟我们这个工作关系不大不赘述。另一项工作预先训练语言模型与词检测的任务。和传统的直接用语言模型单独进行错误纠正的方法不同,相反,我们采用预先训练的语言模型来生成看似合理但视觉上不正确的文本,作为 ViLEM 的训练样本。此外,利用视觉特征检测和纠正文本错误,旨在促进图像-文本关联,进一步提高检索性能.
方法(重点学习)
3.1 双编码器的预训练
双编码器包括了一个视觉的编码器和一个文本的编码器,我们均将其视为若干的Transformer块,每个Transformer块都包含一个多头自注意力层和一个前馈神经网络,此外在文本编码器的前M1层中还加入了交叉注意力模块。这个交叉注意力模块在进行对比学习的时候是未激活的。基本的编码过程是先从原始数据编码到一个全局表征 h i v , h i t h_i^v,h_i^t hiv,hit中 ,然后再将其映射到一个共同的语义嵌入空间 z i v , z i t z_i^v,z_i^t ziv,zit中。相似性的度量通过这个语义嵌入的内积来度量,然后再更新的时候用一种基于动量更新的encoder来实现。
动量的对比学习: 详见MoCo
通过两个队列来存储不同模态的历史特征,从而构建更多的负样本对,最后有损失函数:

Error Modeling
首先根据bert,首先在一串词token中,选取若干的的位置来替换为mask(是一次性换完),然后基于bert生成top-k候选项来对mask进行替换。在对文本进行编辑后,同时会生成两个标签 y i d e t \boldsymbol y_i^{det} yidet和 y i c o r \boldsymbol y_i^{cor} yicor(检错和纠错标签)前者是判断是否有错,后者是保存纠错的原本词。
全局视觉特征的ViLEM
首先利用全局视觉特征进行 ViLEM,将局部文本信息与高层视觉上下文联系起来,提高了对细粒度文本语义的识别能力。值得注意的是,文本编码器也作为文本解码器来预测正确的单词(这句话是什么意思呢?)
这可能会干扰文本特征的编码。因此,我们只对文本编码器的前M1层执行 ViLEM,这实质上将文本编码器分为一个子解码器和一个子编码器,并解耦文本编码器的编码和解码功能以减轻干扰。
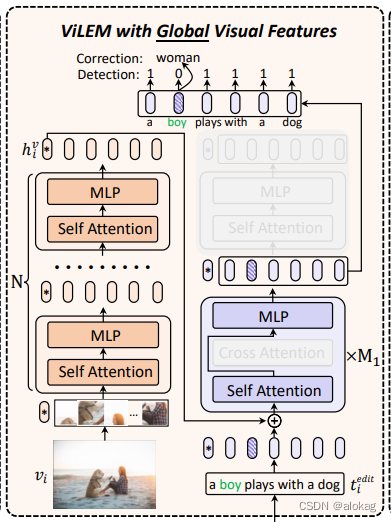
全局的过程是将全局的嵌入放入文本模态的局部嵌入当中。而局部的过程是将局部嵌入放入cross attention。这部分不细讲,具体的cross attention的方式是,将第 m m m层的Transformer块中,将第 l m l_m lm层的patch特征做cross attention,具体算法如下(其实就是均分了)
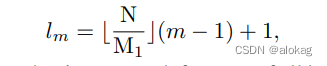
通过输出和grond truth的y进行比对,有如下的两个损失函数:
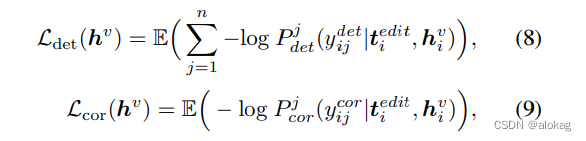
最终损失函数有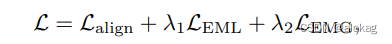
注意到其实这三个是联合训练的,读论文的时候最好奇的就是文本的编码器最后到底是设计成了一个什么结构。
M1块中按照框架图应该是能够同时做到编码器和解码器的功能,这样的话相当于文本模态是一个encoder-decoder后又接了一个encoder。那为什么不在前M1个上做ITC,然后整体做MLM呢?
COTS:基于Momentum CL的VLP
摘要:
首先作品的背景就不多说了,是在跨模态预训练模型兴起的基础上产生的工作,但是这些奠基作(CLIP,ALIGN等),都是在实例整体上进行的对齐。基于此提出了COTS方法(协同的双流式VLP),来增加跨模态的交流。
Motivation & Contribution
框架上分析现有VLP的问题
似乎本文的重点并没有放在“MoCo”上而是放在“Two-Stream”上,正好,笔者对于这种双流结构的模型理解还有所欠缺,所以这部分会详细的进行一些讲述。
- 当前存在的VLP,单流的VLP(图中a部份)往往用一些跨模态融合模块来计算相似性评分,这导致了巨大的计算成本(本文的方法相比单流的方法在inference阶段的效率强了1w倍)
- 为了获取的更有效的数据区域,单流的结构一般用的是用目标检测算法来进行计算。但是这位在时间消耗上跟是重量级,比如在一个800*1333的图像上进行目标提取,用Faster RCNN需要900ms,用基于ViT的方法需要15ms。
双流的方法采用独立的两个编码器,在最后的嵌入层对图像和文本进行对齐。然而,虽然双流的算法比单流的算法更加高效,但是现有方法会因为不同模态间较为独立,缺少相互交流导致结果欠佳,有些方法重新考虑是否需要用目标检测算法,而最近的一些模型采用了大规模的数据进行预训练,但这类方法不会注意细粒度的信息。
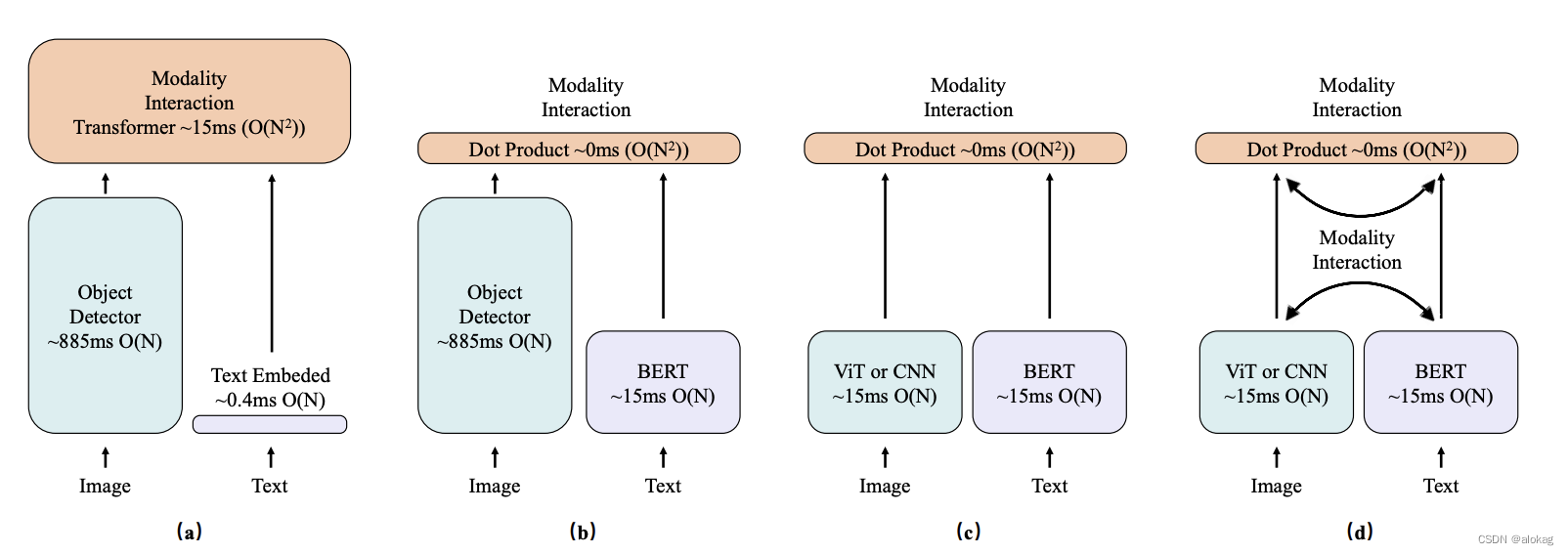
现在先看看现有的若干的算法,这个图也是非常有名的,在很多的文章中都出现过。
a. 单流的方法(低效)
b. 双流+目标检测算法(低效)
c. 双流+实力级别的整体对齐(粗粒度)
d. 本文方法
本文方法(contribution)
- 首先本文会用基于动量的对比学习方法,通过维护两个存储负样本的队列,来进行整体的实例级别的对齐(Instance-level interaction)
- 其次本文通过一个全新的Masked vision-language modeling的损失函数来进行token粒度的学习,而没有用任何传统的交错流的网络结构(虽然示例图中看不出来)
- 最后进行基于任务的对齐,即下游检索任务上的学习。
本文为了解决噪声数据的问题,本文提出了一种基于自适应的动量filter(AMF)模块来利用动量机制协助对比学习过程。具体地,首先先计算所有图像,文本动态队列中的IT对的相似性得分,来获得一个额外的队列;然后将这个相似性得分队列建立成一个正态分布,然后过滤掉相似性得分分布远离均值的样本。
Contribution具体有三点
- 提出了COTS,其中包括了两种粒度的对齐,以及一个基于任务的对齐。
- 提出了基于动量和分布的数据去噪
- 进行了实验以及视频检索的扩展
相关工作
不具体讲,这里也只讲一下MVLM部分的内容。这里讲一讲这些模型的发展过程:传统的一些VLP有用过一点Masked Vision Modeling的方法,这些方法用自底向上的attention机制(先用Faster R-CNN进行目标检测,再用其他标签和text token来预测masked的标签)这种方法有两个主要问题。1. 用Faster R-CNN的方法来进行目标检测来获得区域信息是非常麻烦的,用ViT的骨干网络来提取信息能够快60倍;2. 这些方法没办法进行端到端的训练,即这些方法都是分阶段进行训练的。而这种方式对于未知的object效果会很差。
和这些方法不同的是COTS采用的是VAE来作为tokenizer来将原始图像数据变成离散的Image token,用于masked vision modeling。启发于BEIT,这个tokenizer在端到端的无监督训练模式下进行预训练。相比于直接预测原本的像素点,这种预测被mask掉的token的方法更有意义一些。
所以这个“MLVM”是掩蔽语言建模+掩蔽视觉建模,也就是多模态的掩蔽学习。同时,这都是token级别的掩蔽,能够来学习token-level的跨模态关联。
提出的方法
概览
以下是COTS的整体框图:
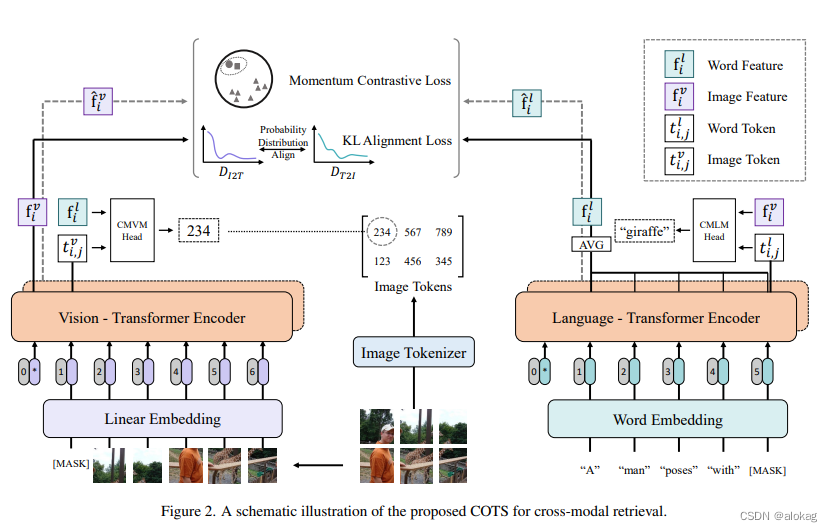
文本模态信息和视觉信息被单独模态的Transformer进行编码后,可以将三个层级的跨模态交互作为COTS的预训练目标函数。整体的实例级别的对齐通过的是Momentum CL的方法(受启发于单模态的MoCo);而对于token-level的对齐,用的是跨模态掩蔽学习MVLM损失。如前文所述,这包含了两个模态的掩蔽学习(CMVM & CMLM)。最后进行一个基于任务的模态交互学习,通过对齐分布来进行跨模态检索任务的学习。
训练目标函数
Token级别的交互
首先设计了一个MVLM loss,可以分成两个部分。首先对于每个图像,CMVM的目标是通过文本和未经掩蔽的Image patches预测出被掩盖的Image token的标签,CMLM就不赘述了。
具体地, D = { ( v i , l i ) } i = 1 N \mathcal D =\{(v_i,l_i)\}_{i=1}^N D={(vi,li)}i=1N表示训练的图像文本对,首先用一个离散差分自编码器将图像分为一传离散的token, T i v = { ( t i , j v ∈ V v ) } j = 1 576 \mathcal T_i^v =\{(t_{i,j}^v\in\mathcal V^v)\}_{j=1}^{576} Tiv={(ti,jv∈Vv)}j=1576。同时,整个图像被分成了24*24的patches,传入到ViT中来获得相应的嵌入。CMVM的损失有:

同理的,对于文本的tokenize就比较显然了,目标函数如下:

实例级别的交互
采用的是基于动量的对比学习。首先,两个encoder f f f有对应的参数 θ \theta θ,然后再原本的基础上再加一个额外的Momentum encoder f ^ \hat f f^和参数 θ ^ \hat\theta θ^。参数的更新方法如下:
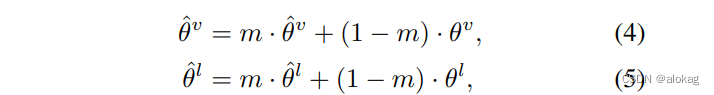
此外,设计了两个队列来保存Momentum feature。
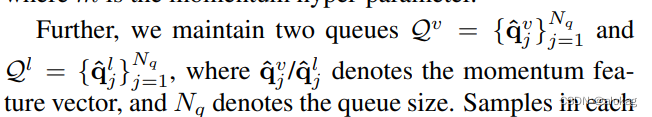
每次训练的时候,取一个mini-batch中的所有样本,喂到Momentum encoder中,获得Momentum feature,然后在计算完损失函数之后将其push到队列中。同时最早进入的 N b N_b Nb个Momentum特征出队。在计算对比损失时,直接将计算出来的当前模态特征和跨模态的动量特征来进行对比损失,有如下公式化描述:
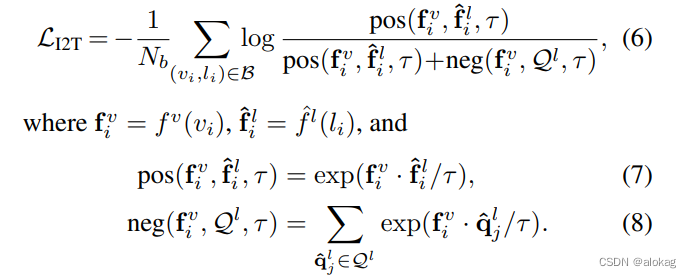
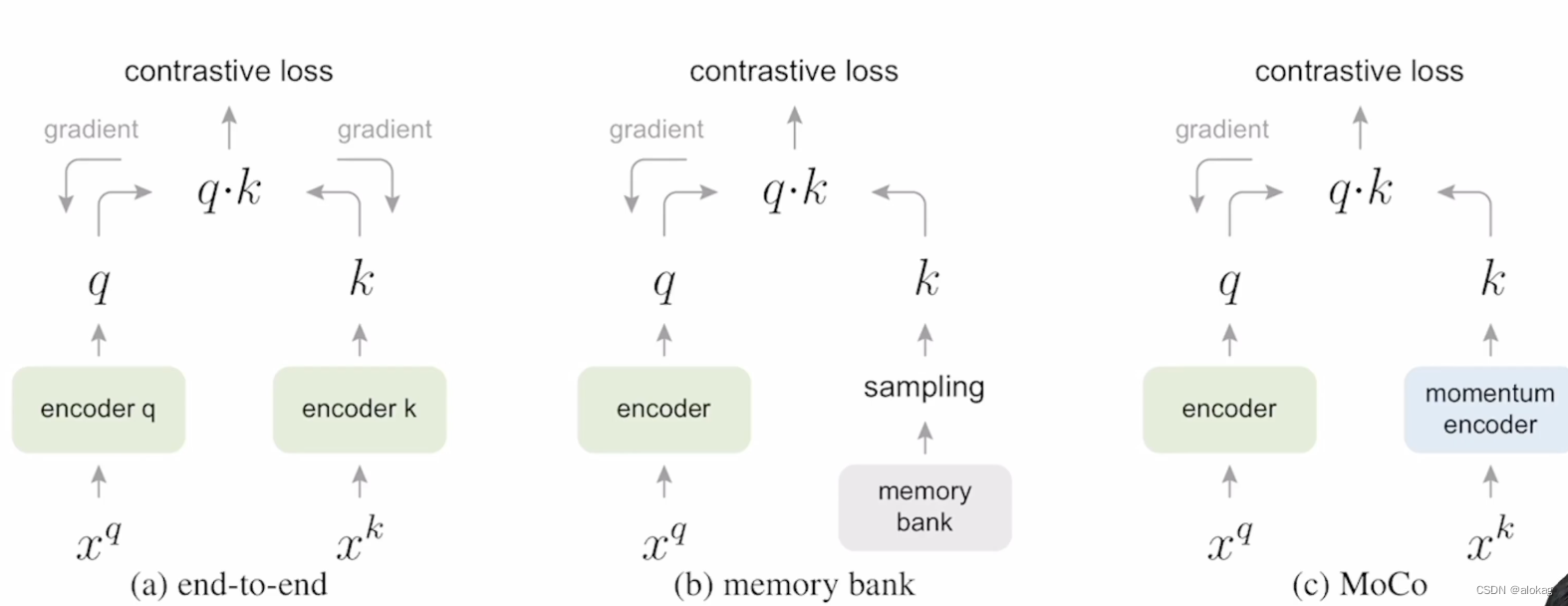
跨模态的MCL基本上是对MoCo的改动,笔者也专项学习了MoCo的一些基本思想,可以参考这个视频MoCo论文逐段精读。总的来说是介于MemoryBank和SimCLR之间的一种更高效,且保持一致性的算法。
关于momentum的实现,阅读了代码后知道,是通过内置函数,在forward()中进行自动更新
基于任务的交互
本文对于跨模态检索任务进行了学习,以image-to-text任务为例,首先先定义检索中的概率分布有
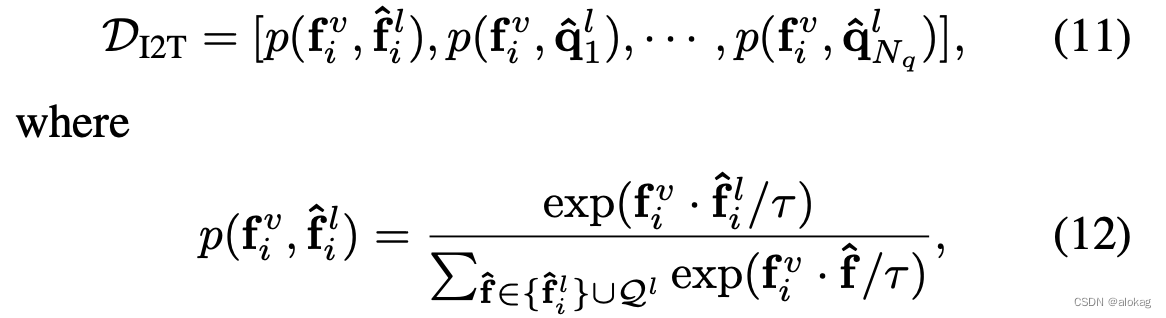
由于本文是基于MCL来做的,所以维护的队列可以用于进行下游任务的学习。计算的是当前样本在所有队列中的key以及自身在momentum encoder上编码内积的softmax(加了温度系数来对分布形状进行修正)
同理可以得到
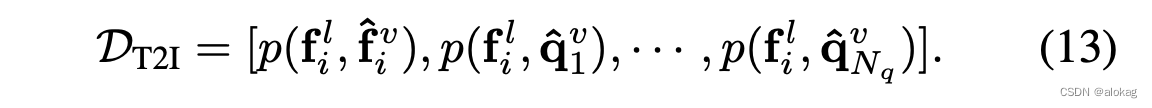
最后最小化两个分布之间的KL散度,有最终的基于任务的交互损失函数有:
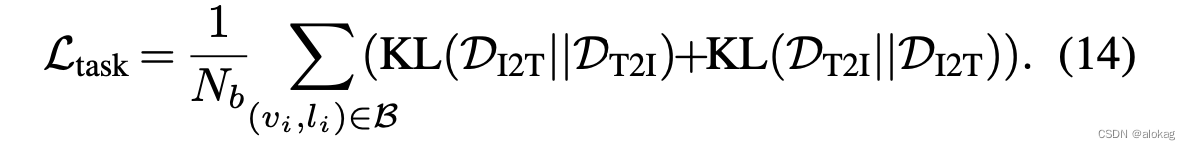
基于动量的数据清洗AMF
本文在维护 Q v , Q l \mathcal Q^v, \mathcal Q^l Qv,Ql的基础上,还会基于两个模态相应的key值的相似性(由内积刻画)构建一个相似性队列 Q s \mathcal Q^s Qs。然后这个工作在进行训练的时候会对这个相似性分布进行建模,计算出一个基本的均值和方差,然后基于这两个值设定一个阈值,认为阈值外的样本上噪声样本。
值得注意的是,噪声样本在作为负样本的时候依旧有学习价值,这也是为什么这个部份仅在计算loss时,即噪声样本作为正样本时使用,在进入队列 Q l , Q v \mathcal Q^l, \mathcal Q^v Ql,Qv时用的还是原始的数据。
实验部份略,本文代码未开源
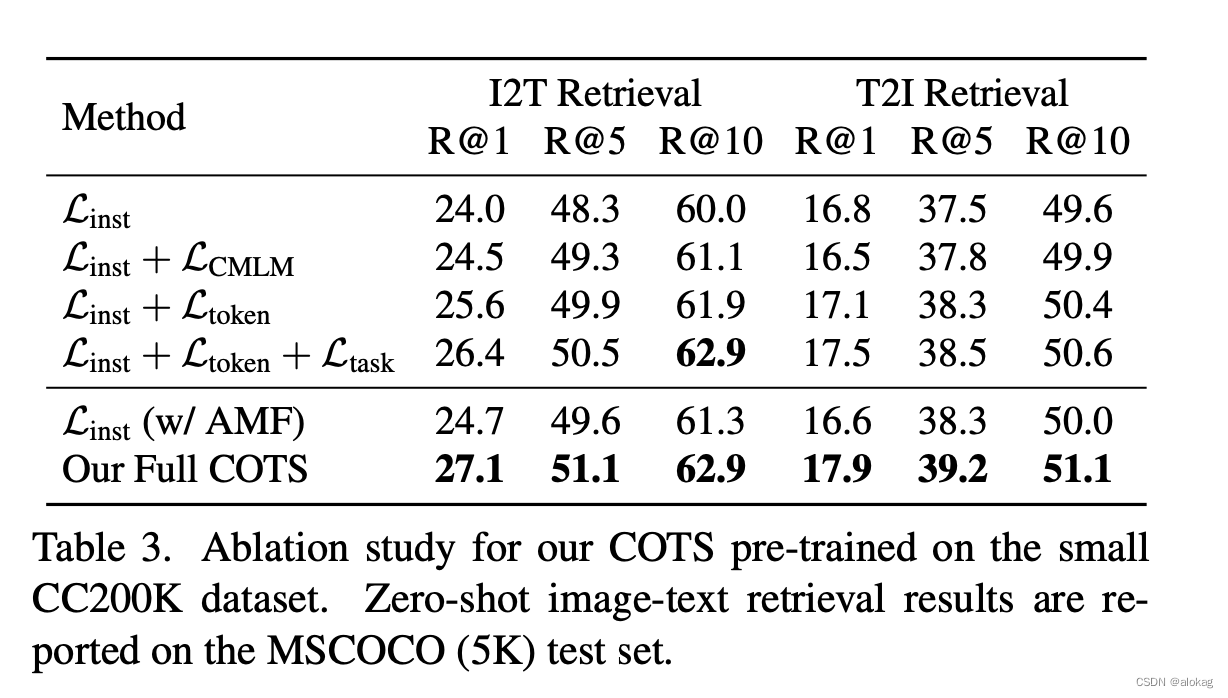
这个消融实验解释了每个部份的意义,挺有趣的是就算不做这个KL散度的loss也有一定的效果。且整体的性能主要还是通过实例对齐,即跨模态MCL方法来达到的。
还有一天要做汇报了,下周再来看这个工作:
Masked Vision-Language Transformer in Fashion
这篇关于【学习日记week5】基于掩蔽的学习方法和跨模态动量对比学习方法(Masked Language Modeling Cross-modal MCL)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





