本文主要是介绍Masked Graph Attention Network for Person Re-identification,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Masked Graph Attention Network for Person Re-identification
论文:Masked Graph Attention Network for Person Re-identification,cvpr,2019
链接:paper
代码:github
摘要
主流的行人重识别方法(ReID)主要关注个体样本图像与标签之间的对应关系,而忽略了整个样本集中丰富的全局互信息。为此,文中提出了一种掩码图注意网络(MGAT)方法。MGAT 利用所提取的特征信息构建完整的图,节点在标签信息的引导下以掩模矩阵的形式定向的关注其他节点的特征。利用MGAT模块,将之前忽略的全局互信息转化为具有更强鉴别能力的优化特征空间。同时,文中还建议将MGAT 模块学习到的优化信息反馈到特征嵌入网络中,以增强映射的可扩展性,从而避免测试阶段大规模图数据处理的困难。文中在三个常用的数据集上进行了实验,结果表明,该方法优于大多数主流方法,并与最先进的方法具有很强的可比性。
引言
大多数主流的方法利用id loss独立的估计每个特征的分类标签,忽视了所有feature 之间的丰富的交互信息。换句话说,它们只关注了特征图的分类特征,而特征之间的聚类特征没有被关注,这个聚类特征描述的是相同特征聚类,不同特征分离的程度。辨别分析研究证明,更多的区分特征需要更好的聚类信息,而当前方法很少考虑这一点。

因此,作者提出了一种新的网络MGAT 来探索特征之间丰富的交互信息。这个网络的核心依赖于节点更新的掩模注意力机制,这和通过注意力矩阵值统计相似节点的卷积神经网络有很大不同。
具体流程为:我们先把学习到的特征embedding 网络重建成一个完整的图,然后MGAT 用注意力机制提供节点更新权重,然后通过掩码矩阵决定节点更新的方向(例如,拉近相同类别,或者推开不同类别节点)。因此,特征最终得到一个改良的聚类特征。
MGAT 的优化输出特征直接被 id loss 监督,确保足够的分类特征。另外,最优化信息被进一步反馈到了原始特征,用一个 optimization feedback (OF) loss来监督反馈。这样做的目的是提高特征嵌入网络的映射能力,从而避免后续操作或者一些不是端到端的处理(比如重排序操作)。
网络结构
文中将MGAT 和 ResNet50 整合到一起做ReID.模型结构如下:

1.概述
网络结构主要分为三个部分:特征提取、通过MGAT 进行特征最优化、最后使用OF loss 把学习到的最优化信息反馈到CNN网络中(特征嵌入空间)。
给一个batch图像,首先使用CNN提取一系列的特征记作X,每一个特征都有唯一对应的一个相关联的图像,把一系列的特征图当做一系列节点,构建一个完全图。在这个图上,每一条边描述的是连接节点的相似程度(包括自节点),相似性可以用很多方法实现。然后,这个创建的完全图被输入到MGAT去优化,需要注意的是MGAT 的输出特征X‘ 直接被id loss 监督,以此来保证分类特征的有效性。
同时,使用OF loss 约束输入特征和原始特征的不同。它被用来反馈MGAT 学到的优化信息并反应到特征嵌入网络中,使得(在测试阶段)特征嵌入网络可以直接生成优化后的特征(不需要任何后续操作)。总的来说,我们的网络架构的原则是提高特征嵌入网络的学习能力(通过使用我们提出的MGAT结构),以至于我们可以探索到更多的可区分的特征空间。
2.MGAT 网络
MGAT 网络是用来解决行人重识别中被忽略的有价值的交互信息,从而得到最优的聚类特征。MGAT 的输入是CNN网络提取的一系列特征X,即N个d维的特征,输出是一个新的X’,即N个 d’ 维的特征。为了让优化后的特征进一步监督原始的特征,指定d’=d.
MGAT 在图结构上工作,把特征当做节点,两个节点距离叫做边E,我们构建一个完全图G(X,E)。用Euclidean distance(欧式距离)来决定两个节点(xi,xj)之间的边长eij;
MGAT 的创新是掩码注意力机制,它是一种为边设计的为了达到提升聚类表现的架构,具体说,注意力机制包括两个部分:注意力矩阵A和掩码矩阵M。
2.1注意力矩阵
注意力机制通常被用来揭示两个特征图之间的关系。在我们的完全图中,由于两节点的距离是由边唯一确定的,所以我们能简单的定义注意力方程f,把边映射到注意力中。
实际中,我们这样定义注意力。公式如下:
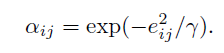
上式中左边是指 i 和 j 节点关系的重要性,γ 是一个超参数,有助于将注意力映射到接近零的小范围内。可以看出,越短的边,会得到更高的注意力。在许多的GCNs 中,为了整合图结构,一个节点通常只被它邻域中第一个临近节点影响。但是由于我们创建的是一个完全图,只包含一个batch 中的图像,所以我们计算每一个节点和其他所有节点的注意力去得到全局信息,为了提高不同节点的兼容性,我们使用了L1正则化,公式如下:
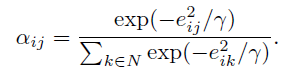
对于一个batch中的N个图,我们得到了一个一排N × N N \times NN×N的注意力矩阵A,在这个矩阵中,第i个节点对于其他所有节点的注意力值在第i行。
2.2 掩码矩阵
注意力矩阵代表的是图中节点信息的重要性,GCNs 和 GATs 会使用这些信息去更新节点(基于连接点最有可能是同类别的假设)。然而,这个假设可能限制了模型的容量,因为这只考虑到了相似性,而忽略了不同程度,并且难以处理困难样本。
为了解决这个问题,沿着注意力矩阵的思路,我们使用了掩码矩阵,缩短同类标签的边长,增长其他情况,以一种注意力的方式,具体说,比如 batch size 为 N,包含 M个ID,每个ID 有K 张图片,如下图:
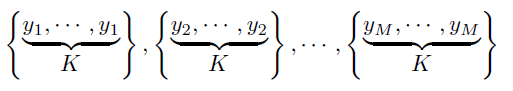
yi是指id为i的标签,掩码矩阵的元素由下式计算:
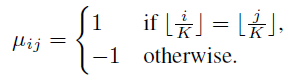
那个符号意思是向下取整,掩码矩阵由1(K × K K\times KK×K)的对角矩阵,还有其他元素都为-1。掩码函数作为一个注意力掩码,把他与注意力矩阵A对应相乘,这确保了相同类别注意力的值是正的,不同类别是负的,这样就使同类的相似性增加,同时不同类的相似性减少。简单的来说,掩码矩阵把节点标签携带的信息加入到了注意力的监督中,因此得到了更好的聚类特征。
有一个疑问是负掩膜会破坏归一化结果,但其实这里归一化的作用是让关注值具有可比性,这样的操作也有权重衰减的效果。
2.3 节点更新
将特征集X和X表示为X, X表示为矩阵形式。更新时,回顾传统的GATs仅利用注意矩阵A,通过线性组合得到节点的输出特征。
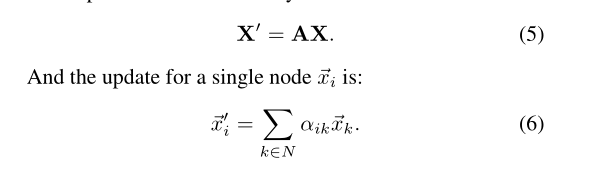
文中通过引入一个额外的掩码矩阵 M,得到了标签监督定向信息来处理节点特征的聚类特性。输出的表达式如下:
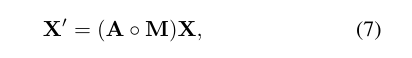
同样,单个节点的更新为:
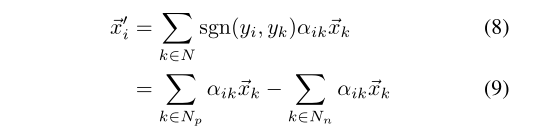
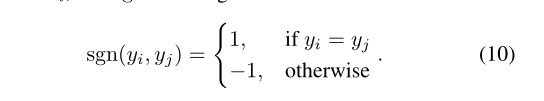
MGAT与传统GATs的节点更新过程如图3所示。请注意,卷积GATs使用注意值来计算相应节点特征的线性组合作为最终的输出节点特征,而不涉及标签监督来直接分离不同类别的节点。作为比较,给定掩模矩阵的掩模信息,我们的MGAT对不同类别的节点应用不同的注意处理。

3.OF loss
为了避免在测试阶段大量的构建图的工作,我们提出利用OF loss 的方法使CNN能够直接生成最优的特征。我们采用最简单的实现方法,即使用均方误差(MSE)损失来约束MGAT的输出特性与CNN提取的嵌入特征之间的差异。
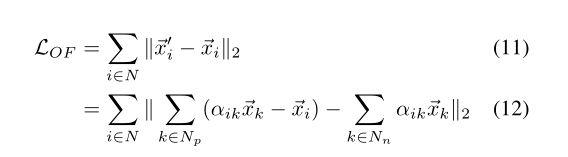
作者说他们没有独立的研究这样做对最后的结果有何影响。
实验
由于作者代码未开源,所以具体训练过程就不说了,直接看一下各个数据上的表现吧。




这篇关于Masked Graph Attention Network for Person Re-identification的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






