本文主要是介绍从DETR到Mask2Former(3):masked attention的attention map可视化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Mask2Former的论文中有这样一张图,表示masked attenion比cross attention效果要好
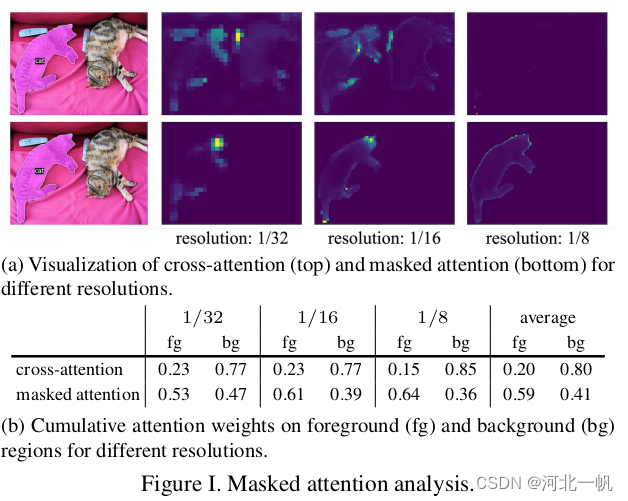
那么这个attention map是怎么画出来的?
在mask2attention的源代码中 CrossAttentionLayer这个类中,在forward_post函数中做如下修改:
def forward_post(self, tgt, memory,memory_mask: Optional[Tensor] = None,memory_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None,query_pos: Optional[Tensor] = None):tgt2, atten_weight = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),key=self.with_pos_embed(memory, pos),value=memory, attn_mask=memory_mask,key_padding_mask=memory_key_padding_mask, average_attn_weights=False)atten_weight = atten_weight.squeeze().detach().cpu().numpy()head_num = 0selected_query_num = 0if atten_weight.shape[-1] == 21888:import matplotlib.pyplot as plt# 创建2行4列的图形fig, axs = plt.subplots(2, 4, figsize=(12, 6))# 使用8次for循环在每个子图中进行绘制for i in range(2):for j in range(4):atten_map = atten_weight[head_num, selected_query_num, :]atten_map = atten_map.reshape((128, 171))head_num += 0axs[i, j].imshow(atten_map)plt.show()tgt = tgt + self.dropout(tgt2)tgt = self.norm(tgt)return tgt在 nn.MultiheadAttention 类实例的forward方法中,加入
average_attn_weights=False得到每个注意力头的attention map,将attention_weight可视化,就得到了论文中的图片。
这篇关于从DETR到Mask2Former(3):masked attention的attention map可视化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





