信息检索专题

对话系统概述:问答型(直接根据用户的问题给出精准的答案,更接近一个信息检索的过程;单轮;上下文无关)、任务型(多轮对话、针对特定场景)、闲聊型(不解决问题;自然交互;多轮对话)、图谱型(基于图谱推理)
参考资料: 【笔记1-1】基于对话的问答系统CoQA (Conversational Question Answering) 了解人机对话—聊天、问答、多轮对话和推荐 幽澜资讯:如何区分智能机器人对话系统的单轮和多轮对话? NLP领域中对话系统(Dialogue)和问答系统(question answer)做法有哪些异同点? GitHub:基

信息检索(52):From doc2query to docTTTTTquery
From doc2query to docTTTTTquery 摘要 发布时间(2019) 摘要 Nogueira 等人 [7] 使用简单的序列到序列转换器 [9] 进行文档扩展。我们用 T5 [8] 替换转换器,并观察到效率大幅提升。 doc2query [7] 是一种文档扩展形式,其理念是训练一个模型,当给定一个输入文档时,该模型会生成该文档可能回答的问题。然后
LSA潜在语义分析与信息检索
1 LSA Introduction LSA(latent semantic analysis)潜在语义分析,也被称为LSI(latent semantic index),是Scott Deerwester, Susan T. Dumais等人在1990年提出来的一种新的索引和检索方法。该方法和传统向量空间模型(vector space model)一样使用向量来表示词(terms)和文档(

一个简单的多线程的大数据信息检索程序
下面我要展示的是一个简单的大数据库的多线程检索程序。 2015年网络上频繁爆出很多互联网大公司数据库泄漏事件,作为一个程序员遇到这种事情当然要down些裤子来黑衣黑朋友啦,比如说某社交平台帐号,或者电商的交易记录(物流信息),再或者快捷酒店的开房记录(你可别想歪了,谁还没出过差)等等。 然而,面对下载下来动不动一个文件就几个G的裤子,我们程序员当然要开外挂喽---多线程! 我的程序很简单,但
TF-IDF算法详解:信息检索与文本挖掘中的关键技术
介绍 TF-IDF算法是文本处理和信息检索领域中的一项基础技术,它通过量化词汇对于一个文档集或一个语料库中的其中一份文档的重要性,来评估词汇的相关性。本书《TF-IDF算法详解:信息检索与文本挖掘中的关键技术》将深入探讨TF-IDF算法的工作原理、计算方法、应用场景以及其在现代文本分析中的重要作用。 本书适合自然语言处理、数据科学、信息检索和文本分析等领域的研究人员和从业者,以及对这些领域感兴

【搜索方法推荐】高效信息检索方法和实用网站推荐
博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持! 博主链接 本人就职于国际知名终端厂商,负责modem芯片研发。 在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。 博客内容主要围绕: 5G/6G协议讲解 算力网络讲解(云计算,边缘计算,端计算) 高级C语言讲解 Rust语言讲解

Ubuntu下python的BeautifulSoup和rsa安装方法---信息检索project2部分:微博爬取所需python包
最近因为《信息检索》第二个project,需要爬取微博数据,然后再处理。师兄给了代码,让慢慢爬,但是在ubuntu下,少了很多python软件包。需要安装。 1.首先运行时,说少了python,BeautifulSoup包,用来解析html文件神奇,这么重要的包怎么能缺少呢,百度ubuntu python BeautifulSoup后,看博客后找到方法: 先安装easy_install工具:

现代信息检索3---词汇表和倒排记录表
第二节里我们了解了倒排索引的基本知识,包括构建、合并、查询等。课件里有个关于google中是否使用布尔模型?这个问题我们还是看下图吧: 让我感觉简单的布尔模型还是有用武之地的。下面是新的知识,对于我这个自学的人来说还是有点难,只能按照我自己的理解去说了。如果有误,欢迎指正。 你一定还记得这个图吧!当时只是一笔带过,现在应该去思考为什么会是这样的。先说下步骤吧: 我们构建索引的输入一般

现代信息检索2-----布尔检索(Boolean Retrieval)
下面我们进入正式的学习,希望这个系列会对自己有用,同样对你也有用!加油…… 布尔检索(Boolean Retrieval),布尔对于我们来说对比较熟悉,就是不是0就是1。顾名思义,布尔检索肯定跟0,1分不开了。剩下的我还是按照ppt顺序,娓娓道来吧。 1.信息检索: Information Retrieval (IR) is finding material (usually docume
现代信息检索1----课程介绍
这个系列是检索检索的内容,一直对这些方法比较感兴趣,所以记录之。一开始是接触斯坦福的CS 276 / LING 286: Information Retrieval and Web Search。后来发现中科院的王斌教授也教授了这个课,对于英语差的人,中文肯定是首选。下面贴出这两门课程的网址: 斯坦福cs276 :http://www.stanford.edu/class/c
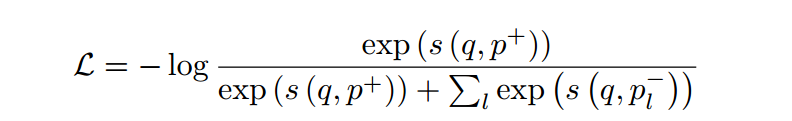
信息检索(36):ConTextual Masked Auto-Encoder for Dense Passage Retrieval
ConTextual Masked Auto-Encoder for Dense Passage Retrieval 标题摘要1 引言2 相关工作3 方法3.1 初步:屏蔽自动编码3.2 CoT-MAE:上下文屏蔽自动编码器3.3 密集通道检索的微调 4 实验4.1 预训练4.2 微调4.3 主要结果 5 分析5.1 与蒸馏检索器的比较5.2 掩模率的影响5.3 抽样策略的影响5.4 解码器
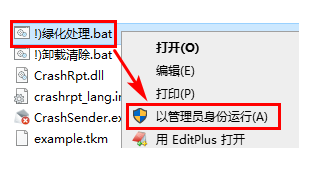
Xshell 7启动报错 产品运行所需的信息检索失败
错误信息 产品运行所需的信息检索失败 请重新安装Xshell Code:40002 解决办法 1、把压缩包解压出来 2、在“!)绿化处理.bat”上面右键以管理员身份运行
信息检索中常用的评价指标:MAP,nDCG,ERR,F-measure
知识点文本检索常用的评价指标:MAP、nDCG、ERR、F-score/F-measure以及附加的Precision、Recall、AveP、CG、DCG、IDCG、MRR、cascade models 而ROC曲线及其度量指标AUC主要用于分类和识别 一,MAP Precision(P): 准确率(精确度)是指检索得到的文档中相关文档所占的比例,公式如下: precisi

信息检索笔记-文档平分,词项权重计算
给定一个布尔查询,返回的结果要么满足条件,要么不满足条件,结果很多的时候就不太对了,应该按照文档的重要性排序后呈现给用户。 本文引入简单的几种权重计算。 域索引权重计算 我们知道一篇文章除了内容外,还有作者、题目,写作时间等,这就是域。我们可以对文档建立域索引。 建立好域索引后,我们就可以通过域加权。考虑这样的例子,一个文档集包含3个域-

信息检索笔记-索引压缩
第一章介绍了信息系统中的两个数据结构:词典及倒排记录表。本文将介绍对两个数据结构的各种压缩技术,这些技术对构建高效的IR系统很关键。 索引压缩的优点:(1)第一能增加高速缓存利用率。在搜索系统中,如果某个关键字使用频繁,那么我们可以将他放在高速缓存中,这样搜索的时候只需要查一下高速缓存就行了(不要磁盘访问操作),找到之后解压缩就行了。如果索引小了就可以在高速缓存里面放更多
信息检索笔记-索引构建
如何构建倒排索引,我们将这个过程叫做“索引构建”。如果我们的文档很多,这样索引就一次性装不下内存,该如何构建。 硬件的限制 我们知道ram读写是随机的操作,只要输入相应的地址单元就能瞬间将数据读出来或者写进去。但是磁盘不行,磁盘必须有一个寻道的过程,外加一个旋转时间。那么只有涉及到磁盘,我们就可以考虑怎么节省I/O操作时间。 【注】操作系统往往以数据块为单位进行读

信息检索笔记-词项及倒排记录表
建立倒排表的几个主要步骤:搜集文档;对文档中的文本进行词条化;对词条进行语言学处理,得到词项;根据词项建立倒排索引。 通过词条化和语言学处理我们才能确定系统的所用词项词典。词条化将原始的字符流转换成一个个词条的过程,而语言学处理主要是建立词条的等价类。 文档分析及编码生成 文档一般由文件或者web中的网页组成,那么第一步我们要确定其编码方式,有时我们

信息检索笔记-布尔检索
信息检索主要分为三大类:Web搜索、个人信息检索和面向企业的搜索。 词项文档矩阵 在搜索的时候,一种土办法:假设我们要在一本书中搜索含有“Brutus”和“Caesar”关键字的文档,那么我从头到尾线性扫描。这种方式在某些情况下不太灵活。一种非线性的扫描方式就是给文档建立索引。我们先给这本书建立一个词项-文档矩阵如下图所示。 其中“lsj”,“se
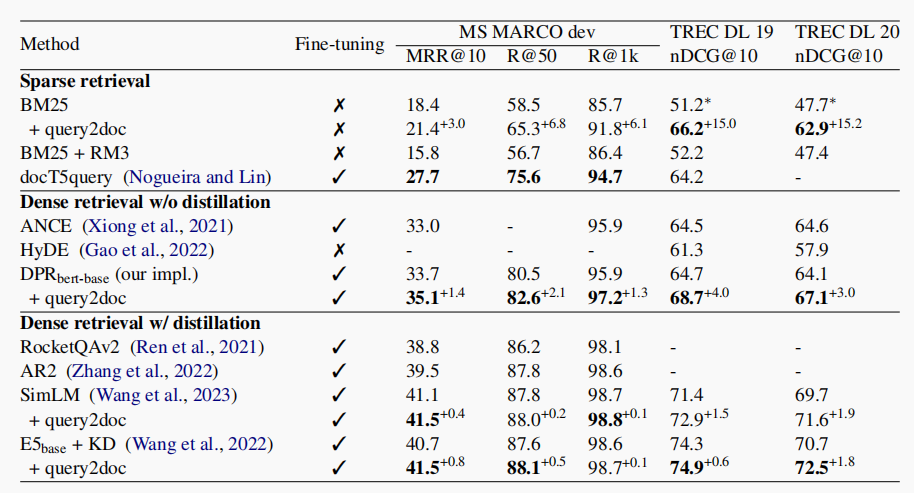
【IR 论文】Query2doc — 使用 LLM 做 Query Expansion 来提高信息检索能力
论文:Query2doc: Query Expansion with Large Language Models ⭐⭐⭐⭐⭐ Microsoft Research, EMNLP 2023 文章目录 背景介绍Query2doc 论文速读实现细节实验结果和分析总结分析 背景介绍 信息检索(Information Retrieval,IR)指的是,给定一个 user quer
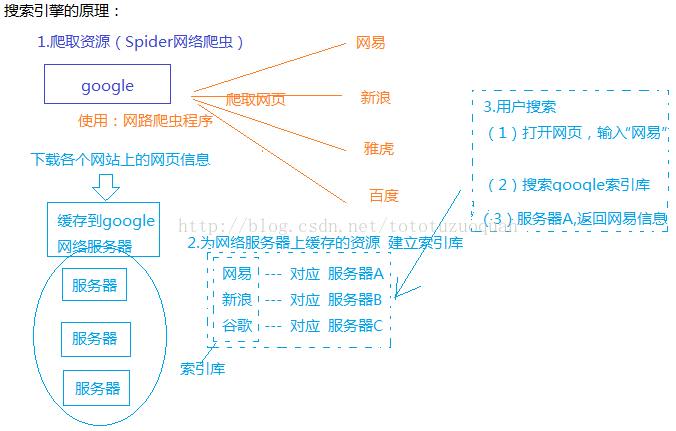
1.搜索引擎的历史,搜索引擎起步,发展,繁荣,搜索引擎的原理,搜索技术用途,信息检索过程,倒排索引,什么是Lucene,Lucene快速入门
一: 1 搜索引擎的历史 萌芽:Archie、Gopher Archie:搜索FTP服务器上的文件 Gopher:索引网页 2 起步:Robot(网络机器人)的出现与spider(网络爬虫) Robot基于网络的,可以执行特定任务的程序 Spider:特殊的机器人,网络爬虫,爬取互联网上的信息(可以是文件,网络)----网络自
写文章需要的一些信息检索
1:有些期刊引用文献需要卷号。但是cnki上检索出来的信息一般只有年,月,期。没有卷号。 解决办法:上这个期刊的官网,一般都有查阅往年期刊的栏目。卷号一般是一年一卷,所以查查看,如果2015年是32卷,那么2005年就是22卷了。因为很多期刊的网站上只保存了最近几年的期刊信息。

RankLLM:RAG架构下通过重排序实现精准信息检索
一、前言 在检索增强生成(Retrieval-Augmented Generation, RAG)的框架下,重排序(Re-Rank)阶段扮演着至关重要的角色。该阶段的目标是对初步检索得到的大量文档进行再次筛选和排序,以确保生成阶段能够优先利用最相关的信息。这一过程类似于传统信息检索中的两阶段排序策略,其中粗排(粗略排序)阶段追求高效的检索速度,而精排(精细排序)阶段则专注于提升结果的相关性和准确
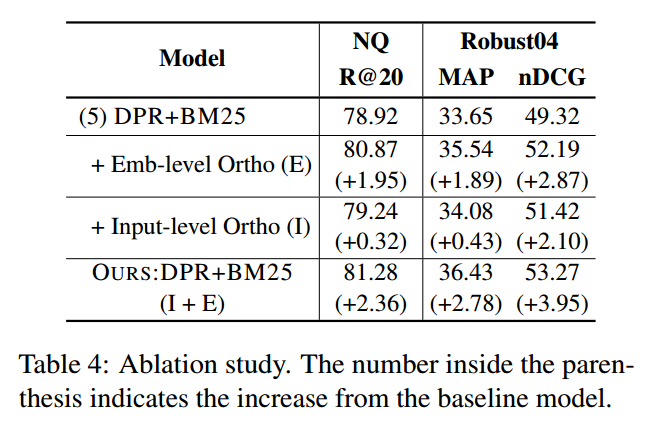
信息检索(十三):On Complementarity Objectives for Hybrid Retrieval
On Complementarity Objectives for Hybrid Retrieval 摘要1. 引言2. 相关工作2.1 稀疏和密集检索2.2 互补性 3. 提出方法3.1 Ratio of Complementarity (RoC)3.2 词汇表示(S)3.3 语义表示(D)3.4 互补目标 4. 实验4.1 实验设置4.2 实验结果4.2.1 RQ1:正交性的有效性4.2
一次性获取数据库中所有用户表信息,以用来进行信息检索之用
使用以下代码,到查询分析器里执行下,就可以得到结果,转载自:http://www.cnblogs.com/tuyile006/archive/2006/09/27/516289.html SELECT (case when a.colorder=1 then d.name else '' end)表名, a.colorder 字段序号, a