本文主要是介绍RT-DETR 详解之 Efficient Hybrid Encoder,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在先前的博文中,博主介绍了RT-DETR在官方代码与YOLOv8集成程序中的训练与推理过程,接下来,博主将通过代码调试的方式来梳理RT-DETR的整个过程。
整体结构
RT-DETR的代码调试大家可以参考博主这篇文章:
在梳理整个代码之前,博主需要说明一下RT-DETR的主要创新点,方便我们在代码调试的过程中有的放矢。
博主首先使用官方代码进行讲解,在后面还会对YOLOv8集成的RT-DETR代码进行讲解,之所以这样安排很大程度上是因为官方代码相较而言更容易理解,而YOLOv8中集成的RT-DETR代码更加具有通用性与规范性,因为里面多是以配置文件的形式来编写的,在理解上或许不够直观。
那么,我们便开始RT-DETR的学习吧,首先需要了解其创新点:
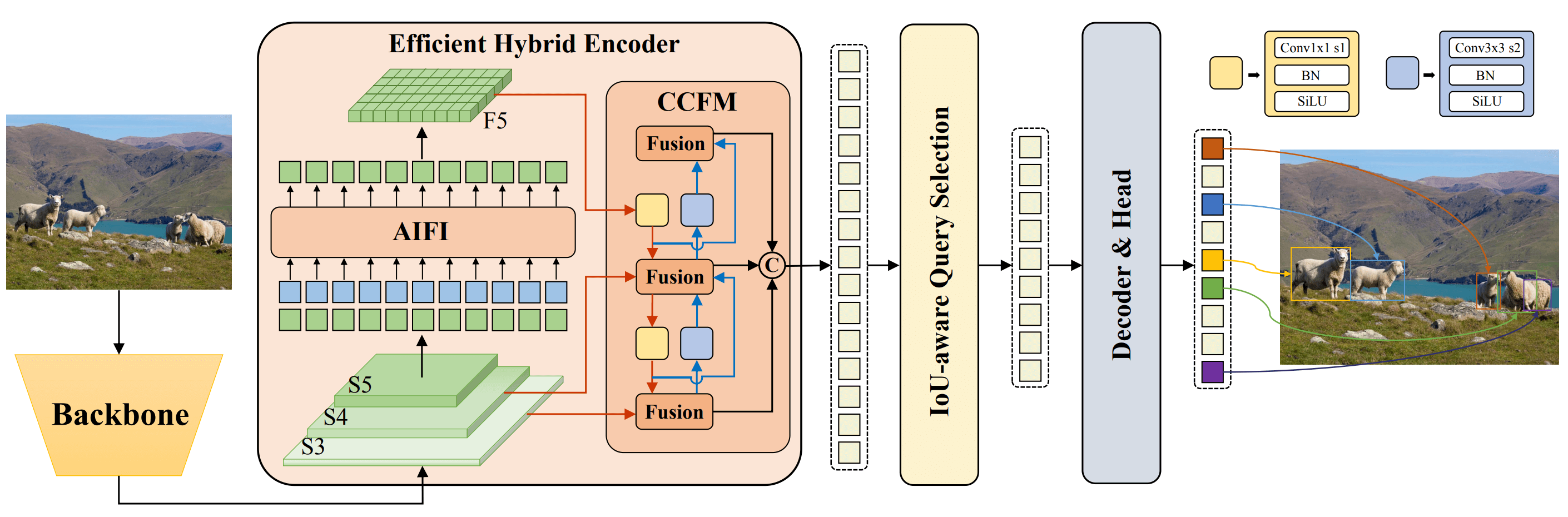
从RT-DETR的结构上来看,其分为四个部分,分别是骨干特征提取网络(backbone)、Transformer编码器模块、Transformer解码器模块以及检测头,其中,RT-DETR的改进主要在Transformer编码器、Transformer解码器部分。
其创新点分别为:
- 创新点1:高效混合编码器(
Efficient Hybrid Encoder):RT-DETR使用了一种高效的混合编码器,通过解耦尺度内交互和跨尺度融合来处理多尺度特征。这种独特的基于视觉Transformer的设计降低了计算成本,并允许实时物体检测。 - 创新点2:
IoU感知查询选择(Uncertainty-minimal Query Selection):RT-DETR通过利用IoU感知的查询选择改进了目标查询初始化。这使得模型能够聚焦于场景中最相关的目标,从而提高了检测精度。 - 创新点3:自适应推理速度(
Scaled RT-DETR):RT-DETR支持通过使用不同的解码器层来灵活调整推理速度,而无需重新训练。这种适应性便于在各种实时目标检测场景中的实际应用。
在进行网络模型的调试前,我们先要找到train、val等代码,在RT-DETR中,数据集加载配置,模型加载都是通过配置文件进行的。
训练代码
首先是训练代码,tools下的train.py为启动文件,里面需要我们指定相应的配置文件:
parser.add_argument('--config', '-c', default="/rtdetr_pytorch\configs/rtdetr/rtdetr_r18vd_6x_coco.yml",type=str, )
该配置文件中还加载了数据集配置文件、优化器等
__include__: ['../dataset/coco_detection.yml','../runtime.yml','./include/dataloader.yml','./include/optimizer.yml','./include/rtdetr_r50vd.yml',
]output_dir: ./output/rtdetr_r18vd_6x_cocoPResNet:depth: 18freeze_at: -1freeze_norm: Falsepretrained: TrueHybridEncoder:in_channels: [128, 256, 512]hidden_dim: 256expansion: 0.5RTDETRTransformer:eval_idx: -1num_decoder_layers: 3num_denoising: 100optimizer:type: AdamWparams: - params: '^(?=.*backbone)(?=.*norm).*$'lr: 0.00001weight_decay: 0.- params: '^(?=.*backbone)(?!.*norm).*$'lr: 0.00001- params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bias)).*$'weight_decay: 0.lr: 0.0001betas: [0.9, 0.999]weight_decay: 0.0001随后,在train.py的main方法中开启训练:
随后在solver中的det_solver.py文件中,运行train_one_epoch方法,传入model,数据集等
训练集配置如下,里面包含batch_size=4,数据集地址等信息
DataLoader(dataset: Dataset CocoDetectionNumber of datapoints: 16270Root location: D:\graduate\datasets\detection\coco\images\train2017img_folder: D:\graduate\datasets\detection\coco\images\train2017ann_file: D:\graduate\datasets\detection\coco\annotations/instances_train2017.jsonreturn_masks: Falsetransforms:Compose(RandomPhotometricDistort(brightness=(0.875, 1.125), contrast=(0.5, 1.5), hue=(-0.05, 0.05), saturation=(0.5, 1.5), p=0.5)RandomZoomOut(p=0.5, fill=0, side_range=(1.0, 4.0))RandomIoUCrop(min_scale=0.3, max_scale=1, min_aspect_ratio=0.5, max_aspect_ratio=2, options=[0.0, 0.1, 0.3, 0.5, 0.7, 0.9, 1.0], trials=40, p=0.8)SanitizeBoundingBox(min_size=1, labels_getter=default)RandomHorizontalFlip(p=0.5)Resize(size=[640, 640], interpolation=InterpolationMode.BILINEAR, antialias=warn)ToImageTensor()ConvertDtype()SanitizeBoundingBox(min_size=1, labels_getter=default)ConvertBox(out_fmt=cxcywh, normalize=True))batch_size: 4num_workers: 4drop_last: Truecollate_fn: <function default_collate_fn at 0x00000293A9606C10>
)
随后我们让数据进入模型,det_engine.py文件中:
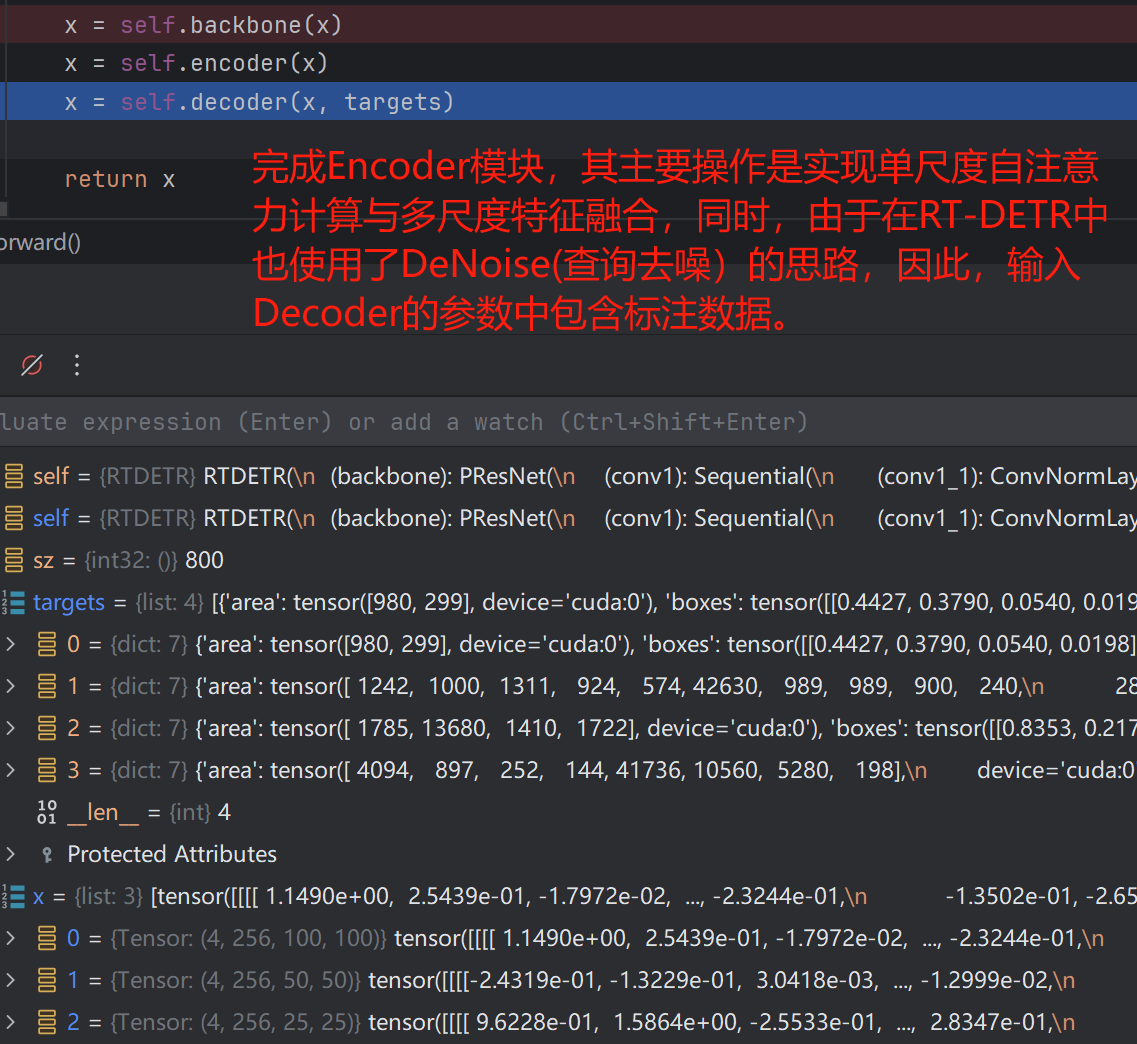
outputs = model(samples, targets)
传入的数据样本(图像)与标签如下:

紧接着便进入了特征提取网络中,该部分即ResNet,这里就不再赘述了,其输出结果有三个,即对应ResNet第3、4、5层输出特征图。

接下来,便是进入Encoder模块了,我们将代码定位到Encoder,即detr_encoder.py文件,在这里,我们先来了解一下RT-DETR中各个文件的内容含义:
随后,进入Encoder模块,即Efficient Hybrid Encoder
Efficient Hybrid Encoder
原理讲解
首先便是第一个创新点的讲解了,其属于模块结构上的创新,用于解决Transformer计算复杂度高的问题。
事实上,第一点创新理解起来并不困难,我们只需要看一下DETR,Deformable-DETR以及RT-DETR的模型对比图即可一目了然。

是不是很清晰了,RT-DETR只使用ResNet最后一层特征图进行自注意力计算,同时Transformer编码器层只有一层,因此计算量就要下降很多,同时使用第3、4层特征图与Transformer编码器输出的扁平特征图进行特征融合,从而获取了多尺度特征。
那么,这个多尺度特征融合是怎么做的呢?其实就和YOLO中的Neck层差不多,通过上采样、下采样、卷积特征提取等操作进行特征融合。
如下图所示,大家可以先看一下这个图,对其有个大概的印象。

代码讲解
其首先进入rtdetr_encoder.py中的HybridEncoder,这里面包含两部分,一个是用于自注意力计算的Encoder,另一个便是提出的融合模块(这个融合模块并没有统一定义在一个类中,而是在运行过程中由多个类组装起来的,如ConvNormLayer、RepVggBlock等。
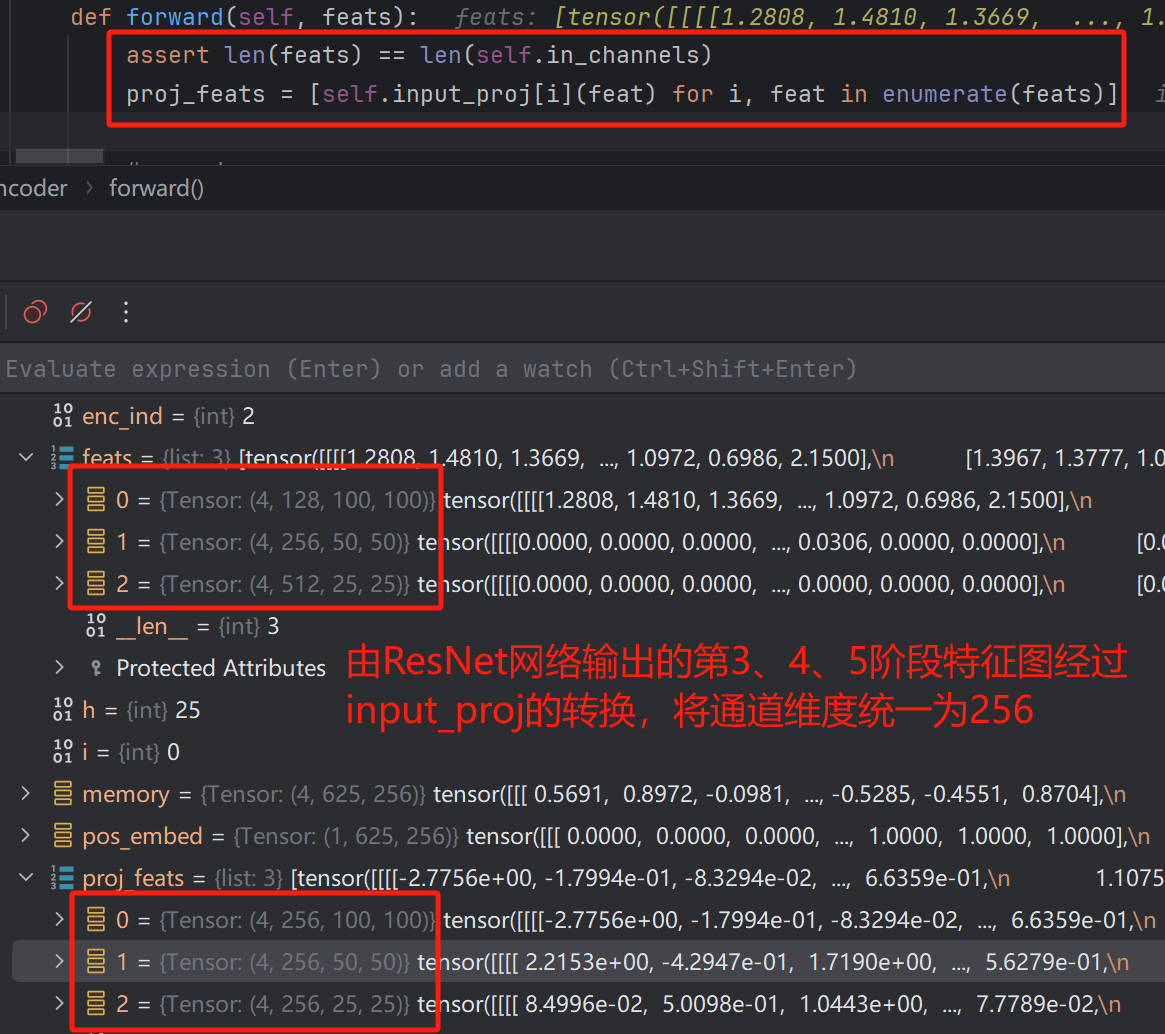
可以看到,输入到HybridEncoder中的即为feats变量,其为list形式,保存的便是ResNet网络输出的第3、4、5特征提取阶段输出的特征图,随后,通过input_proj进行维度转换,将其通道维度统一为256,大小不变。
input_proj的结构如下,其有三个模块,根据输入通道数可知分别对应三个特征图。
ModuleList((0): Sequential((0): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(1): Sequential((0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(2): Sequential((0): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))
)
通过循环的方式对feats进行通道维度变换。
随后便把数据传入Encoder模块:
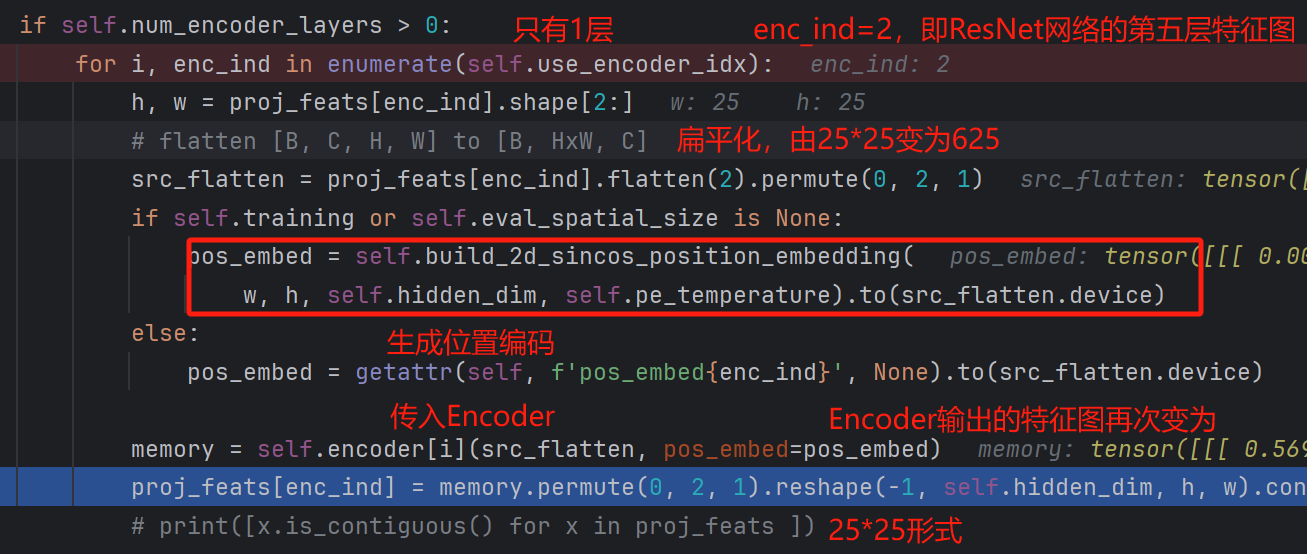
Encoder中的详细过程如下:首先是传入Encoder的参数,分别是src(ResNet第五个特征提取阶段输出的展平特征图),pos_embed位置编码。
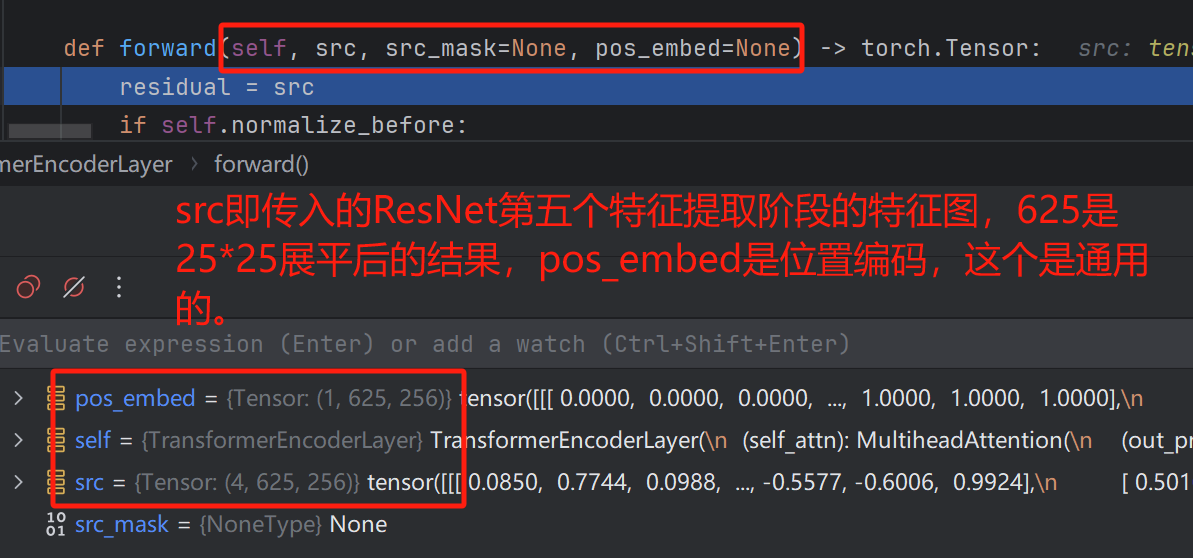
接下来,执行的其实就是Transformer的编码器中的自注意力计算,拼接残差等一系列操作了,实现代码如下(hybrid_encoder.py):
residual = srcif self.normalize_before:src = self.norm1(src)q = k = self.with_pos_embed(src, pos_embed)src, _ = self.self_attn(q, k, value=src, attn_mask=src_mask)src = residual + self.dropout1(src)if not self.normalize_before:src = self.norm1(src)residual = srcif self.normalize_before:src = self.norm2(src)src = self.linear2(self.dropout(self.activation(self.linear1(src))))src = residual + self.dropout2(src)if not self.normalize_before:src = self.norm2(src)return src
我们对其中的关键步骤进行解析:
可以看到,这里它的实现其实就是标准的自注意力计算等一系列操作,其流程如下:
自注意力计算为:
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout, batch_first=True)
该部分代码是在torch中封装好的标准多头注意力,传入的参数为q,k,src(充当value)
其中,q,k是由src与pos_embed相加得到的。
def with_pos_embed(tensor, pos_embed):return tensor if pos_embed is None else tensor + pos_embed
随后便是残差、归一化、前馈神经网络等一系列操作了。在该过程中,数据的维度均未发生改变。

随后,便是作者所提出的创新点了,即CCFM模块,前面已经说过,这个模块没有像Encoder那样统一定义在一起,而是在HybridEncoder中即组即用,我们先来看看前一部分的实现:
for idx in range(len(self.in_channels) - 1, 0, -1):feat_high = inner_outs[0]feat_low = proj_feats[idx - 1]feat_high = self.lateral_convs[len(self.in_channels) - 1 - idx](feat_high)inner_outs[0] = feat_highupsample_feat = F.interpolate(feat_high, scale_factor=2., mode='nearest')inner_out = self.fpn_blocks[len(self.in_channels)-1-idx](torch.concat([upsample_feat, feat_low], dim=1))inner_outs.insert(0, inner_out)
我们以第一次循环为例,self.in_channel=[128, 256, 512],即len为3,该循环是由后往前遍历的
首先是feat_high,其为第五层特征图,feat_low为第四层特征图,在图像特征提取中,我们称越深层网络提取的特征为高维特征,包含的语义信息更丰富,而低维特征细节特征更丰富。

随后将feat_high与feat_low输入lateral_convs模块中,该模块的构造与结构如下:

OrderedDict([('0', ConvNormLayer((conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU(inplace=True)
)), ('1', ConvNormLayer((conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU(inplace=True)
))])
此时,len(self.in_channels) - 1 - idx=0,即调用ConvNormLayer的第一层。
随后进行上采样操作, F.interpolate是torch中提供的一个函数,其作用便是上采样,(插值)
upsample_feat = F.interpolate(feat_high, scale_factor=2., mode='nearest')
其参数为:
input(Tensor):输入张量
size(int or Tuple[int] or Tuple[int, int] or Tuple[int, int, int]) :输出大小
scale_factor (float or Tuple[float]) : 指定输出为输入的多少倍数。如果输入为tuple,其也要制定为tuple类型
mode (str) : 可使用的上采样算法,有’nearest’, ‘linear’, ‘bilinear’, ‘bicubic’ , ‘trilinear’和’area’. 默认使用’nearest’
此时upsample_feat的维度为torch.Size([4, 256, 50, 50]),即原本的第五层特征图的大小已经与第四层相同了
接下来,将feat_low(第四层特征图)与upsample_feat拼接,输入 fpn_block。
inner_out = self.fpn_blocks[len(self.in_channels)-1-idx](torch.concat([upsample_feat, feat_low], dim=1))
fpn_block的构造过程与结构如下:

结构如下图所示(论文图像)

ModuleList((0-1): 2 x CSPRepLayer((conv1): ConvNormLayer((conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU(inplace=True))(conv2): ConvNormLayer((conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU(inplace=True))(bottlenecks): Sequential((0): RepVggBlock((conv1): ConvNormLayer((conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(norm): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): Identity())(conv2): ConvNormLayer((conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): Identity())(act): SiLU(inplace=True))(1): RepVggBlock((conv1): ConvNormLayer((conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(norm): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): Identity())(conv2): ConvNormLayer((conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): Identity())(act): SiLU(inplace=True))(2): RepVggBlock((conv1): ConvNormLayer((conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(norm): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): Identity())(conv2): ConvNormLayer((conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): Identity())(act): SiLU(inplace=True)))(conv3): ConvNormLayer((conv): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU(inplace=True)))
)
随后,便进入第二次循环,此时的特征图即为第四层特征图与第三层特征图了,其余的过程均相同,只是维度不同而已,这里就不再赘述了。

经过这样一系列的操作,最终会将三个不同尺度的特征图组合起来,同时,还将三个特征图存入inner_outs中,供下一阶段使用。其操作为:
inner_outs.insert(0, inner_out)
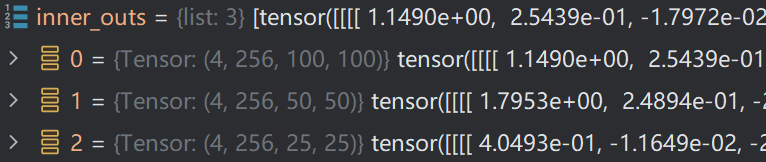
随后便是下一阶段的操作了,首先获取第三层特征图,在inner_outs中索引为0。outs=torch.Size([4, 256, 100, 100])
outs = [inner_outs[0]]for idx in range(len(self.in_channels) - 1):feat_low = outs[-1]feat_high = inner_outs[idx + 1]downsample_feat = self.downsample_convs[idx](feat_low)out = self.pan_blocks[idx](torch.concat([downsample_feat, feat_high], dim=1))outs.append(out)
接着,便获取outs与inner_outs中的值,feat_low 的维度为torch.Size([4, 256, 100, 100]),此时idx=0,则feat_high = inner_outs[1],即其维度为torch.Size([4, 256, 50, 50])
此时,将feat_low通过下采样进行维度缩减,得到downsample,其维度为torch.Size([4, 256, 100, 100])
下采样模块的构造与结构如下,其是基于 ConvNormLayer层构建的
self.downsample_convs.append(ConvNormLayer(hidden_dim, hidden_dim, 3, 2, act=act))
结构如下:
ModuleList((0-1): 2 x ConvNormLayer((conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(norm): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU(inplace=True))
)
最后,便是将两个特征图拼接,然后输入pan_blocks模块,其构造方式如下:
可以看到,pan_blocks模块是基于 CSPRepLayer构建的。
self.pan_blocks.append(CSPRepLayer(hidden_dim * 2, hidden_dim, round(3 * depth_mult), act=act, expansion=expansion))
ModuleList((0-1): 2 x CSPRepLayer((conv1): ConvNormLayer((conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU(inplace=True))(conv2): ConvNormLayer((conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU(inplace=True))(bottlenecks): Sequential((0): RepVggBlock((conv1): ConvNormLayer((conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(norm): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): Identity())(conv2): ConvNormLayer((conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): Identity())(act): SiLU(inplace=True))(1): RepVggBlock((conv1): ConvNormLayer((conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(norm): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): Identity())(conv2): ConvNormLayer((conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): Identity())(act): SiLU(inplace=True))(2): RepVggBlock((conv1): ConvNormLayer((conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(norm): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): Identity())(conv2): ConvNormLayer((conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): Identity())(act): SiLU(inplace=True)))(conv3): ConvNormLayer((conv): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(norm): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU(inplace=True)))
)
随后,得到的out为torch.Size([4, 256, 50, 50]),并将其添加到outs,以供下一层循环使用

随后,其操作便是相同的了,只不过换成了第四层特征图与第五层特征图罢了。最终,得到outs如下:
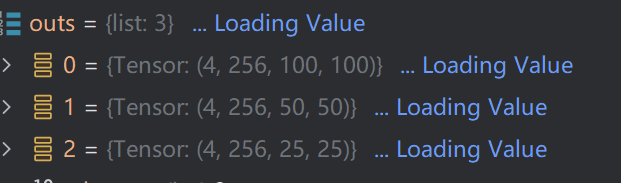
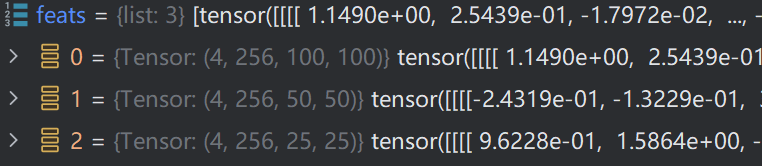
随后,将结果返回,输入到Decoder中。
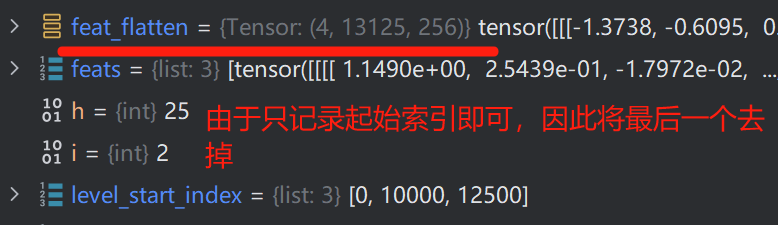
在进入真正的Decoder之前,还需要将Encoder输入的三层特征图进行扁平化,从而继续自注意力计算。三层特征图如下:
扁平化融合操作如下:
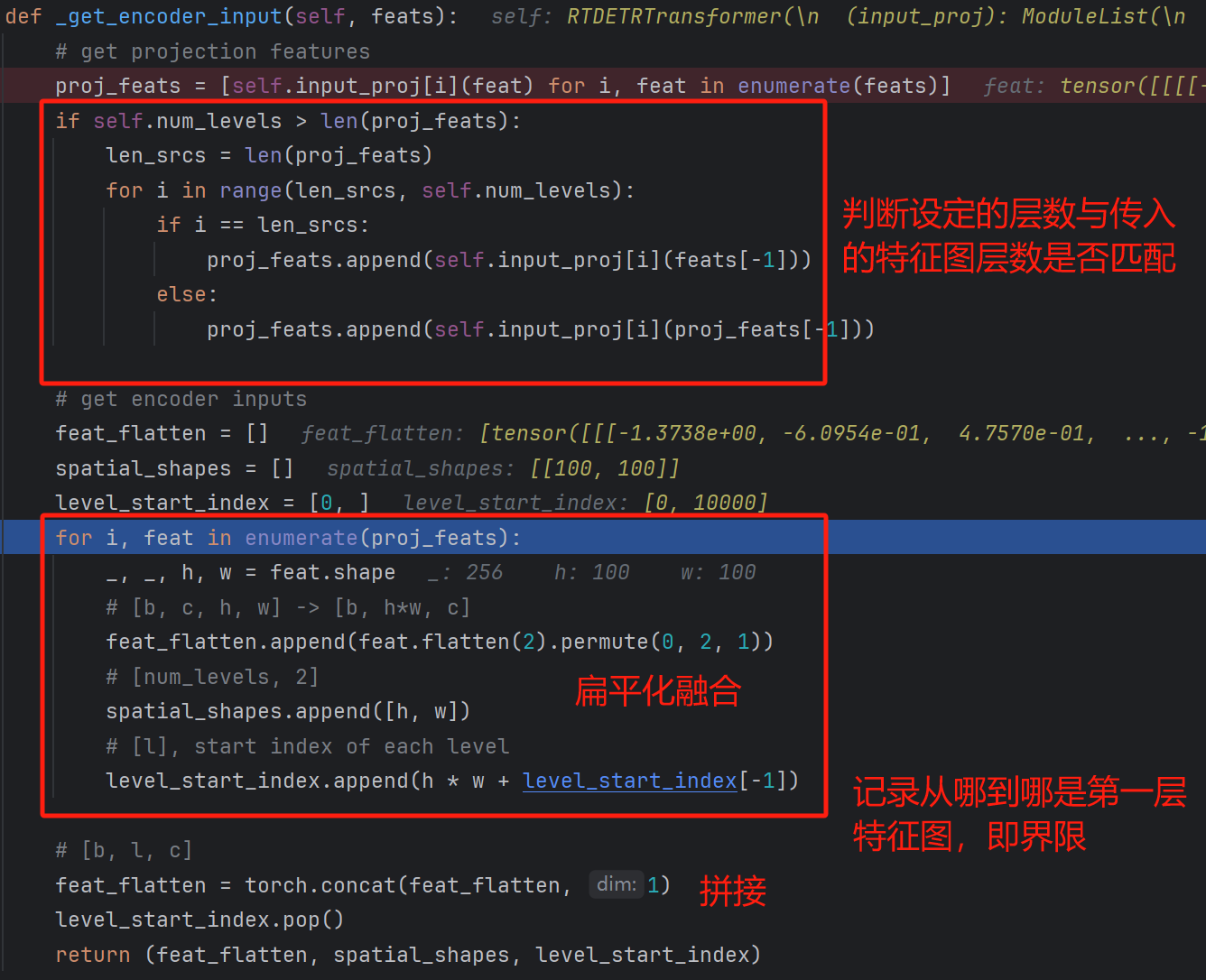
level_start_index 的值为 [0, 10000, 12500, 13125]
spatial_shapes的值为:[[100, 100], [50, 50], [25, 25]]
得到的feat_flatten如下:

通过concat拼接后如下:
至此,Efficient Hybrid Encoder模块便讲解完成了。
上述整个流程如下:

接下来,便是Decoder部分的介绍了,码字不易,给个赞呗!
这篇关于RT-DETR 详解之 Efficient Hybrid Encoder的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






