efficient专题
![[论文笔记]QLoRA: Efficient Finetuning of Quantized LLMs](https://img-blog.csdnimg.cn/img_convert/e75c9a4137c39630cd34c5ebe3fe8196.png)
[论文笔记]QLoRA: Efficient Finetuning of Quantized LLMs
引言 今天带来LoRA的量化版论文笔记——QLoRA: Efficient Finetuning of Quantized LLMs 为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。 我们提出了QLoRA,一种高效的微调方法,它在减少内存使用的同时,能够在单个48GB GPU上对65B参数的模型进行微调,同时保持16位微调任务的完整性能。QLoRA通过一个冻结的4位量化预

《Efficient Batch Processing for Multiple Keyword Queries on Graph Data》——论文笔记
ABSTRACT 目前的关键词查询只关注单个查询。对于查询系统来说,短时间内会接受大批量的关键词查询,往往不同查询包含相同的关键词。 因此本文研究图数据多关键词查询的批处理。为多查询和单个查询找到最优查询计划都是非常复杂的。我们首先提出两个启发式的方法使关键词的重叠最大并优先处理规模小的关键词。然后设计了一个同时考虑了数据统计信息和搜索语义的基于cardinality的成本估计模型。 1.

《The Power of Scale for Parameter-Efficient Prompt Tuning》论文学习
系列文章目录 文章目录 系列文章目录一、这篇文章主要讲了什么?二、摘要中T5是什么1、2、3、 三、1、2、3、 四、1、2、3、 五、1、2、3、 六、1、2、3、 七、1、2、3、 八、1、2、3、 一、这篇文章主要讲了什么? The article “The Power of Scale for Parameter-Efficient Prompt Tuning
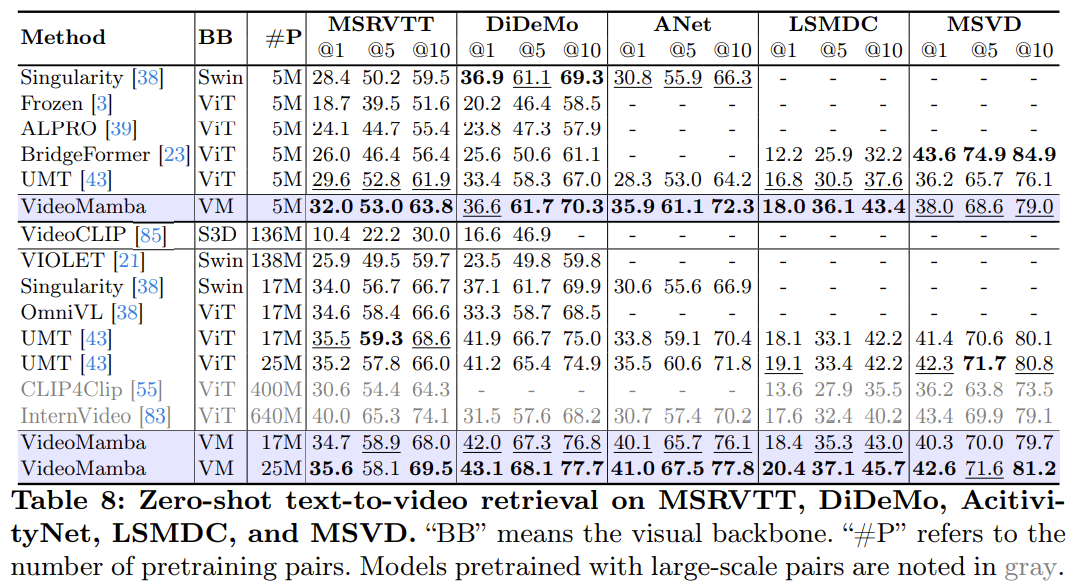
论文阅读:VideoMamba: State Space Model for Efficient Video Understanding
论文地址:arxiv 摘要 为了解决视频理解中的局部冗余与全局依赖性的双重挑战。作者将 Mamba 模型应用于视频领域。所提出的 VideoMamba 克服了现有的 3D 卷积神经网络与视频 Transformer 的局限性。 经过广泛的评估提示了 VideoMamba 的能力: 在视觉领域有可扩展性,无需大规模数据集来预训练。对于短期动作也有敏感性,即使是细微的动作差异也可以识别到在长期视

Efficient LoFTR论文阅读(特征匹配)
Efficient LoFTR论文阅读(特征匹配) 摘要1. 引言2. 相关工作基于检测器的图像匹配无检测器图像匹配 3. 方法3.1. 局部特征提取3.2. 高效的局部特征变换3.3. 准备工作3.4. 聚合注意力机制3.5 粗级匹配模块有效推理策略子像素级细化模块有效的精细特征提取两阶段相关细化 3.6 损失函数粗级匹配监督精细级匹配监督 4. 实验4.1. 实施细节4.2. 相对姿态

pytorch 参数冻结 parameter-efficient fine-tuning
目标:在网络中冻结部分参数进行高效训练 框架:pytorch (version 1.11.0) 基本实现: 需要学习的参数requires_grad设置为True,冻结的设置为False需要学习的参数要加到 optimizer的List中;对于冻结的参数,可以直接不加进去,(应该也可以加进去,但是requires_grad=False) 注意事项: 3. 如果不传递参数的层,记得前向操作是

论文学习—Efficient Multi-label Classification with Many Labels
论文学习:Efficient Multi-label Classification with Many Labels 摘要2. 多标签分类相关工作2.1 Label Transformation1. **降维(Dimensionality Reduction)**2. **回归模型(Regression Model)**3. **逆变换(Inverse Transformation)** 2

拥挤场景多人姿态估计论文梗概及代码CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark
姿态估计是视频动作分析识别的基础工作,我有一篇小综述讲了姿态估计相关技术路线的发展,可以点这个链接看。 本文是MVIG大佬们发表在CVPR2019上的一篇论文,上号交通大学,基于AlphaPose思路,进一步提升了拥挤情况下准度 代码:github点这,基于Pytorch,是实时多人姿态估计系统 论文:论文点这 论文第二版点这 Abstract 多人姿态估计是大量计算机视觉任务的基础,近年来也

论文阅读--Efficient Hybrid Zoom using Camera Fusion on Mobile Phones
这是谷歌影像团队 2023 年发表在 Siggraph Asia 上的一篇文章,主要介绍的是利用多摄融合的思路进行变焦。 单反相机因为卓越的硬件性能,可以非常方便的实现光学变焦。不过目前的智能手机,受制于物理空间的限制,还不能做到像单反一样的光学变焦。目前主流的智能手机,都是采用多摄的设计,一般来说一个主摄搭配一个长焦,为了实现主摄与长焦之间的变焦,目前都是采用数字变焦的方式,数字变焦相比于光学
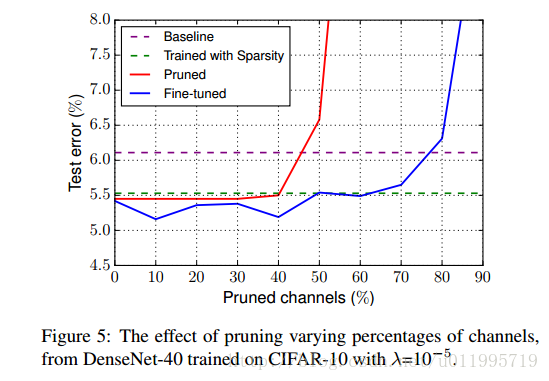
模型压缩:Networks Slimming-Learning Efficient Convolutional Networks through Network Slimming
Network Slimming-Learning Efficient Convolutional Networks through Network Slimming(Paper) 2017年ICCV的一篇paper,思路清晰,骨骼清奇~~ 创新点: 1. 利用batch normalization中的缩放因子γ 作为重要性因子,即γ越小,所对应的channel不太重要,就可以裁剪(prun
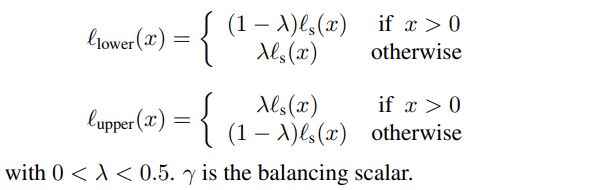
论文阅读笔记——DeepPruner: Learning Efficient Stereo Matching via Differentiable PatchMatch
这篇文章,是2019年新的ICCV的papper,文章典型的使用了PatchMatch的思路,使得最后的速度快了很多。主要思路是:首先利用一种新颖的可微Patch Match算法来获得稀疏的cost volume。 然后,我们利用此表示来了解每个像素的修剪范围,自适应地修剪了每个区域的搜索空间。 最后,利用图像引导的优化模块来进一步提高性能。 由于所有组件都是可区分的,因此可以以端到端的方式训练整
Light OJ 1054 Efficient Pseudo Code 求n^m的约数和
题目来源:Light OJ 1054 Efficient Pseudo Code 题意:求n的m次这个数的所有的约数和 思路:首先对于一个数n = p1^a1*p2^a2*p3^a3*…*pk^ak 约束和s = (p1^0+p1^1+p1^2+…p1^a1)(p2^0+p2^1+p2^2+…p2^a2)…(pk^0+pk^1+pk^2+…pk^ak) 然后就是先求素数表 分解因子 然后求
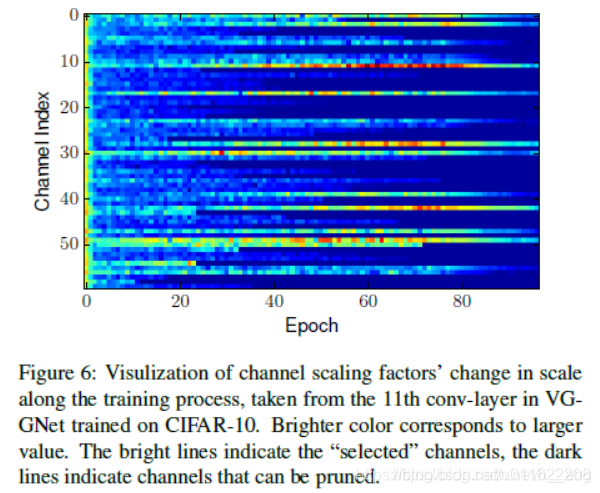
【网络裁剪】——Learning Efficient Convolutional Networks through Network Slimming
转载自:https://blog.csdn.net/h__ang/article/details/89376079 亮点:ICCV 2017 论文链接:https://arxiv.org/abs/1708.06519 官方代码(Torch实现):https://github.com/liuzhuang13/slimming 第三方代码(PyTorch实现):https://github.c
![LLM微调方法(Efficient-Tuning)六大主流方法:思路讲解优缺点对比[P-tuning、Lora、Prefix tuning等]](https://img-blog.csdnimg.cn/direct/9ddbc0ebbb4c456dbf42c95c066245dd.png)
LLM微调方法(Efficient-Tuning)六大主流方法:思路讲解优缺点对比[P-tuning、Lora、Prefix tuning等]
LLM微调方法(Efficient-Tuning)六大主流方法:思路讲解&优缺点对比[P-tuning、Lora、Prefix tuning等] 由于LLM参数量都是在亿级以上,少则数十亿,多则数千亿。当我们想在用特定领域的数据微调模型时,如果想要full-tuning所有模型参数,看着是不太实际,一来需要相当多的硬件设备(GPU),二来需要相当长的训练时间。因此,我们可以选择一条捷径,不需要微

3D点云论阅读:ShellNet:Efficient Point Cloud Convolutional Neural Networks using Concentric Shells Statics
论文:http://openaccess.thecvf.com/content_ICCV_2019/papers/Zhang_ShellNet_Efficient_Point_Cloud_Convolutional_Neural_Networks_Using_Concentric_Shells_ICCV_2019_paper.pdf 源码:https://github.com/hkust-vgd

论文笔记:EAST: an Efficient and Accuracy Scene Text detection pipeline
EAST: an Efficient and Accuracy Scene Text detection pipeline 直接在整张图像上回归目标和它的几何轮廓,模型是全卷积神经网络,每个像素位置都输出密集的文字预测。排除了生成候选目标,生成文字区域,字母分割(candidate proposal, text region formation, word partition)等中间过程。后续过

RT-DETR 详解之 Efficient Hybrid Encoder
在先前的博文中,博主介绍了RT-DETR在官方代码与YOLOv8集成程序中的训练与推理过程,接下来,博主将通过代码调试的方式来梳理RT-DETR的整个过程。 整体结构 RT-DETR的代码调试大家可以参考博主这篇文章: 在梳理整个代码之前,博主需要说明一下RT-DETR的主要创新点,方便我们在代码调试的过程中有的放矢。 博主首先使用官方代码进行讲解,在后面还会对YOLOv8集成的RT-DE
翻译 | ORB: An efficient alternative to SIFT or SURF(ORB:对SIFT或SURF的一种有效选择)
博主github:https://github.com/MichaelBeechan 博主CSDN:https://blog.csdn.net/u011344545 ORB:对SIFT或SURF的一种有效选择 ORB: an efficient alternative to SIFT or SURF 译者:Michael Beechan(陈兵) 重庆理工大学 Ethan Rublee Vi

uva 11020 - Efficient Solutions(STL)
题目链接:uva 11020 - Efficient Solutions 题目大意:依次给定n个人的坐标,每次输出当前有多少个人属于优势群体,优势群体的定义为不存在另一个人的坐标x,y均小于自己(等于是可以的)
论文阅读:《Bag of Tricks for Efficient Text Classification》
重磅专栏推荐: 《大模型AIGC》 《课程大纲》 《知识星球》 本专栏致力于探索和讨论当今最前沿的技术趋势和应用领域,包括但不限于ChatGPT和Stable Diffusion等。我们将深入研究大型模型的开发和应用,以及与之相关的人工智能生成内容(AIGC)技术。通过深入的技术解析和实践经验分享,旨在帮助读者更好地理解和应用这些领域的最新进展 https://blog.csdn.
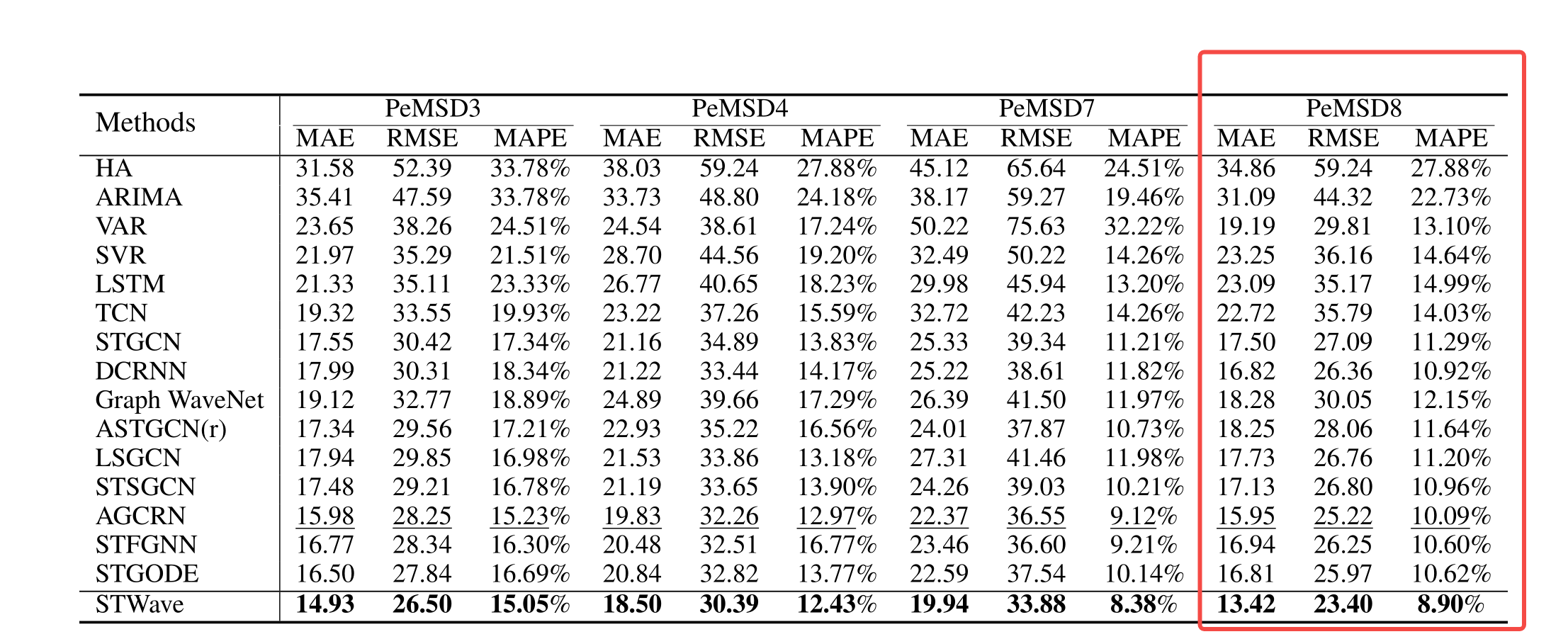
【深度学习】【STWave】时空图预测,车流量预测,Efficient Spectral Graph Attention Network
Spatio-Temporal meets Wavelet: Disentangled Traffic Flow Forecasting via Efficient Spectral Graph Attention Network 代码:https://github.com/LMissher/STWave 论文:https://arxiv.org/abs/2112.02740 帮助: http

【索引】Chapter 1. Algorithm Design :: Designing Efficient Algorithms :: Exercises: Beginner
题目链接:http://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&category=461 TitleTotal Submissions / Solving %Total Users / Solving %10125 - Sumsets17713 21.28% 2628 74.05% 1

【索引】Chapter 1. Algorithm Design :: Designing Efficient Algorithms :: Examples
链接:http://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&category=460 点击题目进入题解: TitleTotal Submissions / Solving %Total Users / Solving %11462 - Age Sort24713 36.09% 6227
UVA 11020 - Efficient Solutions(set)
UVA 11020 - Efficient Solutions 题目链接 题意:每个人有两个属性值(x, y),对于每一个人(x,y)而言,当有另一个人(x', y'),如果他们的属性值满足x' < x, y' <= y或x' <= x, y' < y的话,这个人会失去优势,每次添加一个人,并输出当前优势人个数 思路:由于每个人失去优势后,不可能再得到优势,所以失去优势就可以当成删去
TEINet: Towards an Efficient Architecture for Video Recognition 论文阅读
TEINet: Towards an Efficient Architecture for Video Recognition 论文阅读 Abstract1 Introduction2 Related Work3 Method3.1 Motion Enhanced Module3.2 Temporal Interaction Module3.3 TEINet 4 Experiments5 C
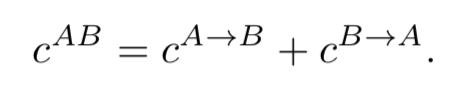
Efficient Neighbourhood Consensus Networks via Submanifold Sparse Convolutions
本文的目的是输入一个image pair 然后得到他们的匹配 内存消耗大,推理时间长,对应关系局部性差。我们提出的修改可以减少10倍以上的内存占用和执行时间,并且效果相当。这是通过对包含试探性匹配的相关张量进行稀疏化,然后使用子流形稀疏卷积对其进行4D CNN后续处理来实现的。通过以更高的分辨率处理输入图像(这是可能的,因为减少了内存占用),以及通过一个新的两级对应重定位模块,定位精度显著