本文主要是介绍论文阅读:《Bag of Tricks for Efficient Text Classification》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
重磅专栏推荐:
《大模型AIGC》
《课程大纲》
《知识星球》
本专栏致力于探索和讨论当今最前沿的技术趋势和应用领域,包括但不限于ChatGPT和Stable Diffusion等。我们将深入研究大型模型的开发和应用,以及与之相关的人工智能生成内容(AIGC)技术。通过深入的技术解析和实践经验分享,旨在帮助读者更好地理解和应用这些领域的最新进展
https://blog.csdn.net/u011239443/article/details/80076720
论文地址:https://arxiv.org/pdf/1607.01759v2.pdf
摘要
本文提出了一种简单而有效的文本分类和表示学习方法。 我们的实验表明,我们的快速文本分类器fastText在准确性方面通常与深度学习分类器保持一致,并且在训练和评估中速度快很多。 我们可以在不到10分钟的时间内使用标准的多核CPU对超过10亿个单词进行快速文本训练,并在不到一分钟的时间内对312K类中的50万个句子进行分类。
介绍
建立良好的文本分类表示是许多应用程序的重要任务,如Web搜索,信息检索,排序和文档分类。 最近,基于神经网络的模型在计算句子表示方面越来越受欢迎。 虽然这些模型在实践中取得了非常好的表现,但是在训练和测试时间,它们往往相对较慢,限制了它们在非常大的数据集上的使用。
与此同时,简单的线性模型也显示出令人印象深刻的性能,同时计算效率非常高。 他们通常学习单词级别的表示,后来组合起来形成句子表示。 在这项工作中,我们提出了这些模型的扩展,以直接学习句子表示。 我们通过引入其他统计数据(如使用n-gram包)来显示,我们减少了线性和深度模型之间精度的差距,同时速度提高了许多个数量级。
我们的工作与标准线性文本分类器密切相关。 与Wang和Manning类似,我们的动机是探索由用于学习无监督词表示的模型启发的简单基线。 与Le和Mikolov不同的是,我们的方法在测试时不需要复杂的推理,使得其学习表示很容易在不同问题上重复使用。 我们在两个不同的任务中评估模型的质量,即标签预测和情感分析。
模型架构
句子分类的简单而有效的基线是将句子表示为词袋(BoW)并训练线性分类器,例如逻辑回归或支持向量机。 但是,线性分类器不能在特征和类之间共享参数,可能会限制泛化。 这个问题的常见解决方案是将线性分类器分解成低秩矩阵或使用多层神经网络。在神经网络的情况下,信息通过隐藏层共享。
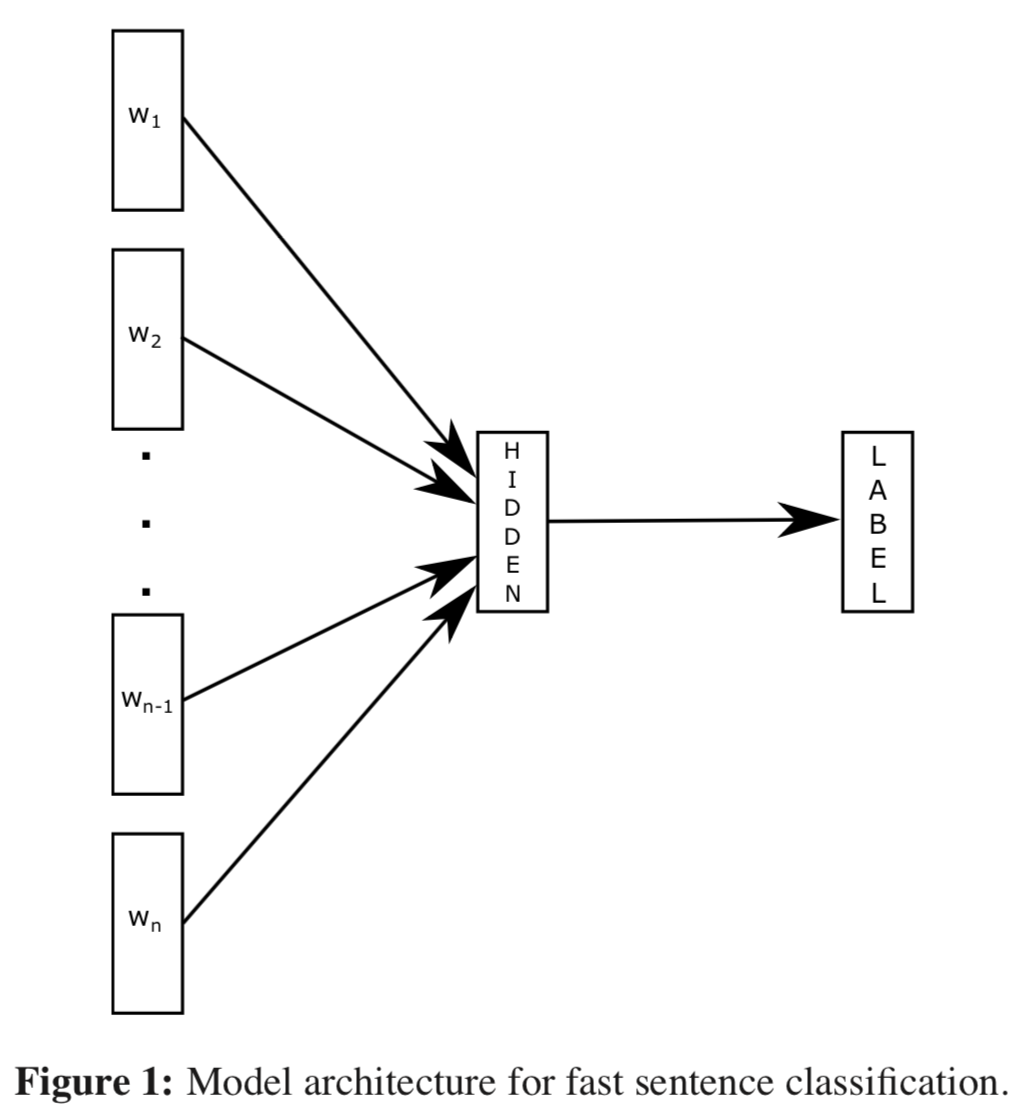
图1显示了一个带有1个隐藏层的简单模型。 第一个权重矩阵可以看作是一个句子单词的查找表。 词表示被平均为文本表示,然后反馈给线性分类器。 这种结构类似于Mikolov等人的cbow模型,其中中间的单词被标签取代。 该模型将一系列单词作为输入,并在预定义的类上生成概率分布。 我们使用softmax函数来计算这些概率。
训练这样的模型本质上与word2vec相似,也就是说,我们使用随机梯度下降和反向传播以及线性衰减的学习速率。 我们的模型在多个CPU上异步训练。
分层softmax
当目标数量很大时,计算线性分类器的计算量很大。 更准确地说,计算复杂度为 O
这篇关于论文阅读:《Bag of Tricks for Efficient Text Classification》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








