本文主要是介绍模型压缩:Networks Slimming-Learning Efficient Convolutional Networks through Network Slimming,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Network Slimming-Learning Efficient Convolutional Networks through Network Slimming(Paper)
2017年ICCV的一篇paper,思路清晰,骨骼清奇~~
创新点:
1. 利用batch normalization中的缩放因子γ 作为重要性因子,即γ越小,所对应的channel不太重要,就可以裁剪(pruning)。
2. 为约束γ的大小,在目标方程中增加一个关于γ的正则项,这样可以做到在训练中自动剪枝,这是以往模型压缩所不具备的。
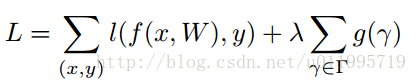
模型压缩三要素:
1. Model size ,模型大小
2. Run-time memory , 模型得小,效率也得高,不能参数少,运算却很多,还是不行滴。
3. Number of computing operations
模型压缩存在的不足:
1. 低秩分解方法:对全连接层效果可以,对卷积层不怎么样;模型大小可压缩3倍,但运算速度无明显提升。
2. Weight Quantization: HashNet虽然可采用分组、共享权值方法来压缩所需保存的参数数量,但是在 Run-time memory上面没有任何压缩。
3. 二值化权值: 损失精度
4. Weight Pruning/Sparsifying: 需要专用的硬件或者代码库;[12]训练过程中,没有一个对稀疏进行“约束”“指导”(guidance)
5. Structured Pruning/Sparsifying: 本文方法所属类型,当然没有缺点啦。。。就算就文章中也不会提嘛~
——————————————分割线—————————————
正文:
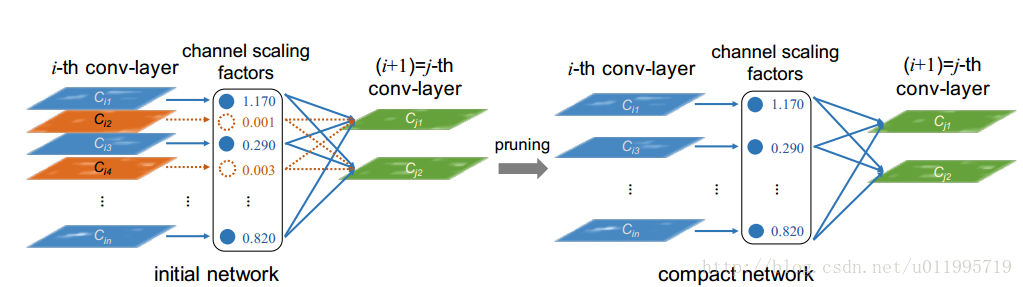
Network slimming,利用BN层中的缩放因子γ,在训练过程当中来衡量channel的重要性,将不重要的channel进行删减,达到压缩模型大小,提升运算速度的效果。
看一下模型图,左边为训练当中的模型,中间一列是scaling factors,也就是BN层当中的缩放因子γ,当γ较小时(如图中0.001,0.003),所对应的channel就会被删减,得到右边所示的模型。 道理是不是非常简单,而且巧妙的将γ增加到目标函数中去,达到了一边训练一边剪枝的奇效。
来看目标函数: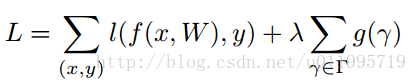
第一项是模型预测所产生的损失,第二项就是用来约束γ的,λ是权衡两项的超参,后面实验会给出,一般设置为1e-4 或者 1e-5。g(*)采用的是g(s)=|s|, 就是L1范,可达到稀疏的作用。原理就讲完了~
接下来看看,整体是如何运行的,如何剪枝再训练,再剪枝。 整体流程框图如下图所示:
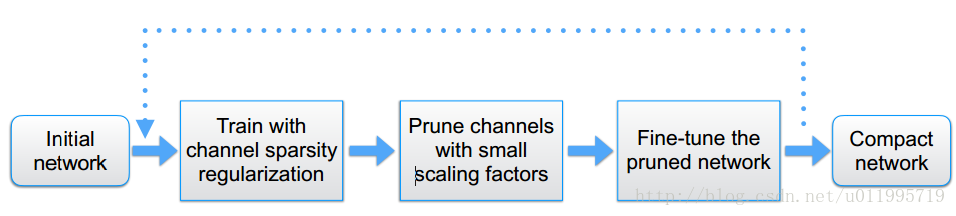
分为三部分,第一步,训练;第二步,剪枝;第三步,微调剪枝后的模型,循环执行。
具体操作细节:
γ通常取 1e-4或者1e-5,具体情况具体分析,
γ得出后,应该怎么剪,γ多小才算小? 这里采用与类似PCA里的能量占比差不多,将当前层的γ全都加起来,然后按从大到小的顺序排列,选取较大的那一部分,通常选取70%左右(具体情况具体分析)。
λ的选取对γ的影响如图所示:
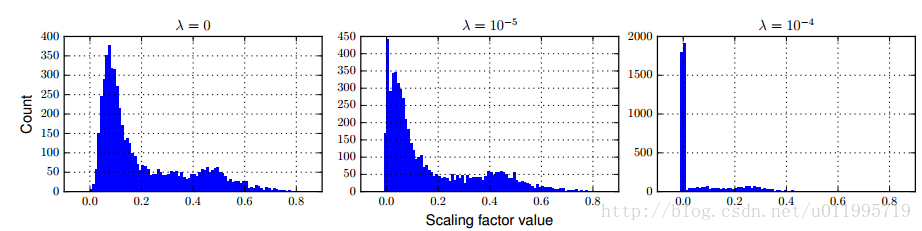
λ为0的时候,目标函数不会对γ进行惩罚,λ等于1e-5时,可以发现,γ=0.0+的有450多个,整体都向0靠近。当λ=1e-4时,对γ有了更大的稀疏约束了,可以看到有接近2000个γ是在0.0x附近。
剪枝百分比: 剪得越多,模型越小;剪得太多,精度损失。这是矛盾的,所以作者做了实验对比,看看剪多少合适。实验发现,当剪枝超过80%,精度会下降。
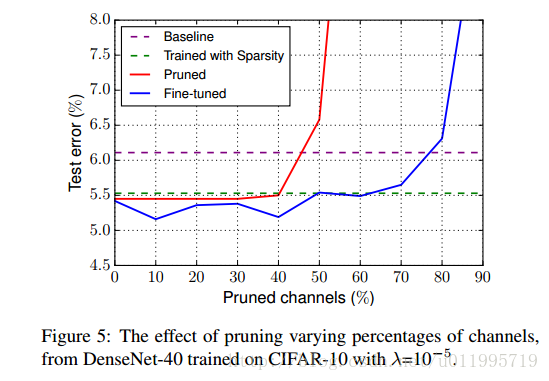
具体实验请阅读原文,其中涉及了vgg,resnet-164(pre-actionvation),densenet-40。效果都很好,不仅压缩模型大小,提升运算速度,还能提升分类准确率。
torch代码:https://github.com/liuzhuang13/slimming
这篇关于模型压缩:Networks Slimming-Learning Efficient Convolutional Networks through Network Slimming的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









