本文主要是介绍3D点云论阅读:ShellNet:Efficient Point Cloud Convolutional Neural Networks using Concentric Shells Statics,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文:http://openaccess.thecvf.com/content_ICCV_2019/papers/Zhang_ShellNet_Efficient_Point_Cloud_Convolutional_Neural_Networks_Using_Concentric_Shells_ICCV_2019_paper.pdf
源码:https://github.com/hkust-vgd/shellnet



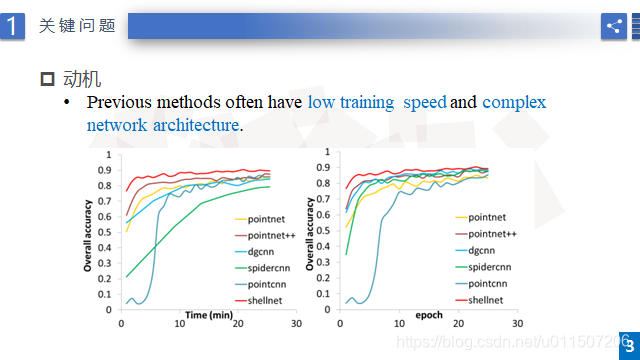










这篇关于3D点云论阅读:ShellNet:Efficient Point Cloud Convolutional Neural Networks using Concentric Shells Statics的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









