本文主要是介绍论文阅读:Self-conditioned Image Generation via Generating Representations(RCG),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Self-conditioned Image Generation via Generating Representations(RCG)
work
提出的表示条件图像生成(Representation-Conditioned image Generation,RCG),一个简单而有效的框架用于自适应图像生成。
简而言之就是无附加条件生成相同分布的图片。
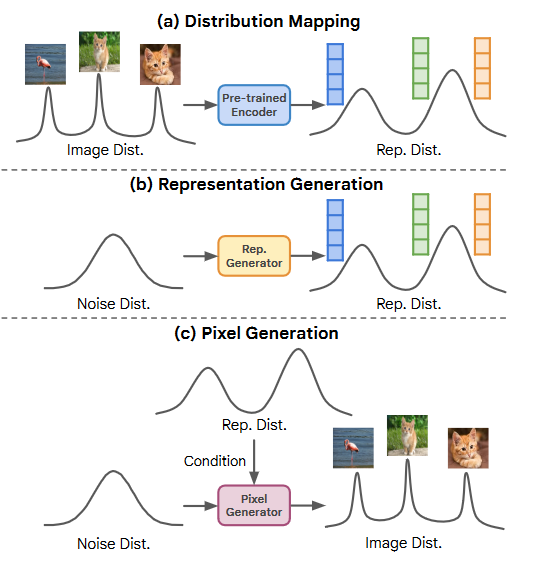
框架主要分为三步:
- 使用一个image encoder 将原始图像分布映射到低维表示分布(representation distribution);
- 训练一个表示生成器(representation generator)以将噪声分布映射到表示分布;
- 训练一个像素生成器(pixel generator)以将噪声分布映射到以表示分布为条件的图像分布。
Method
RCG包括三个关键组件:预训练的自监督图像编码器(pre-trained self-supervised image encoder),表示生成器(representation generator)和像素生成器(pixel generator)。
1. pre-trained self-supervised image encoder
RCG使用预训练的图像编码器将图像分布转换为表示分布。这种分布具有两个基本属性:表示扩散模型建模的简单性和用于指导像素生成的丰富的高层语义内容。文章的预训练模型选用ImageNet上的sota:Moco v3(同一个实验室的工作)。在projection head(256-dim)之后提取表示,并且每个表示都通过其自身的均值和标准差进行归一化。
2. representation generator
RCG使用简单而有效的表示扩散模型(RDM)从表示空间中进行采样。RDM采用以多个残差块为backbone的全连接网络。
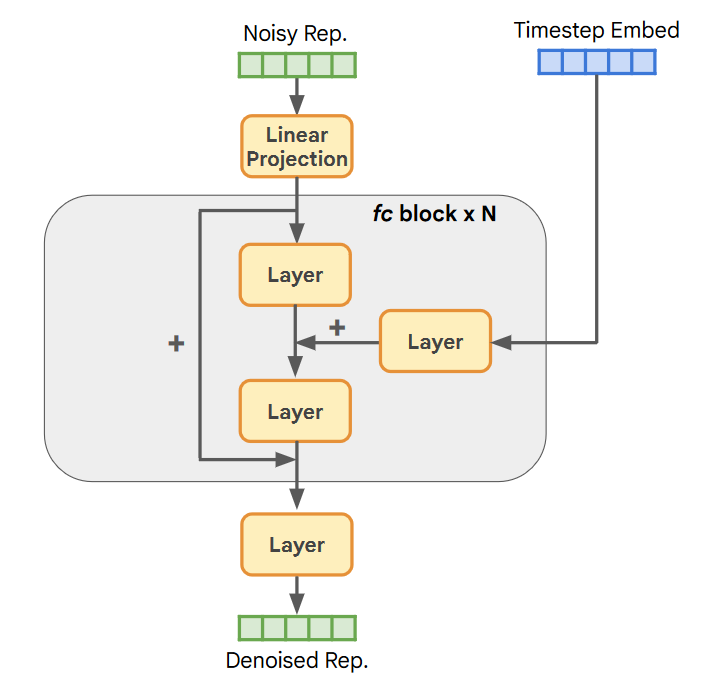
每层"Layer"都是由a LayerNorm layer ,a SiLU layer ,and a linear layer组成的。主干由输入层,时间步长嵌入投影层和输出层组成,输入层将表示投影到隐藏维度C,随后接着N个全连接(FC)块,输出层将隐藏latent投影回原始表示维度。这样的结构由两个参数控制:残差块的数量N和隐藏维度C。
RDM遵循去噪扩散隐式模型(DDIM)进行训练和推理。
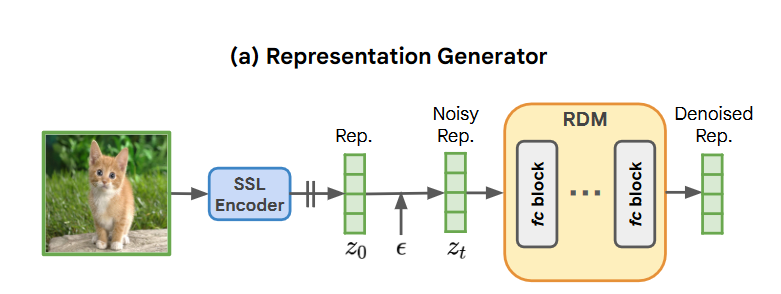
在训练的过程中,将图像表示(image representation) z 0 z_0 z0与标准高斯噪声变量(standard Gaussian noise variable) ϵ \epsilon ϵ混合: z t = α t z 0 + 1 − α t ϵ z_t=\sqrt{\alpha_t}z_0+\sqrt{1-\alpha_t}\epsilon zt=αtz0+1−αtϵ。然后对RDM backbone进行训练,以将 z t z_t zt降噪回 z 0 z_0 z0。在推理过程中,RDM根据DDIM采样过程从高斯噪声生成表示。由于RDM在高度紧凑的表示上操作,因此它为训练和生成带来了边际计算开销。
3. pixel generator
RCG中的像素生成器根据图像表示来生成图像像素。理论上,通过用SSL表示替换其原始条件,这样的像素生成器可以变成任何现代条件图像生成模型。我们以MAGE(一种并行译码生成模型)为例,像素生成器被训练以根据相同图像的表示从图像的掩蔽版本重建原始图像。在推断期间,像素生成器以来自表示生成器的表示为条件,从完全屏蔽的图像生成图像。
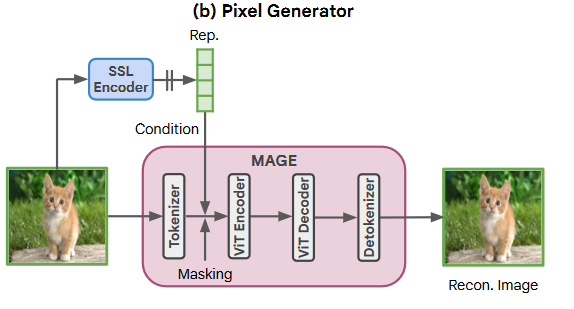
为了训练MAGE像素生成器,我们将随机掩蔽添加到标记化的图像中,并要求网络根据从同一图像中提取的表示来重建丢失的标记。
我们实验了三个有代表性的生成模型:基于扩散的ADM和LDM,以及一个并行解码框架MAGE。我们的实验表明,在高级表示的条件下,这三种生成模型都取得了更好的性能
4. Classifier-free Guidance.
RCG的一个优点是它无缝地提升了无条件生成任务(unconditional generation tasks)的无分类器指导(classifier-free guidance)。以增强生成模型性能而闻名的无分类器指导传统上不适用于无条件生成框架。这是因为无分类器引导被设计为通过无条件生成来为条件图像生成提供引导。虽然RCG也是为无条件生成任务而设计的,但RCG的像素生成器以自监督表示为条件,因此可以无缝集成无分类器指导,从而进一步提高其生成性能。
计的,但RCG的像素生成器以自监督表示为条件,因此可以无缝集成无分类器指导,从而进一步提高其生成性能。
RCG模仿 Muse 来使它的 MAGE 像素生成器支持无分类器引导。在训练过程中,MAGE 像素生成器有10%的概率不使用SSL representations作为conditioned。在每次推理步骤中,MAGE 预测每个掩码token的SSL representation条件logits l c l_c lc和无条件logits l u l_u lu。最终的logits l g l_g lg 是由 l c l_c lc从 l u l_u lu移动距离指导 scale τ \tau τ得到的: l g = l c + τ ( l c − l u ) l_g=l_c+\tau (l_c-l_u) lg=lc+τ(lc−lu)。然后,MAGE 根据 l g l_g lg对剩余的掩码token进行采样。
这篇关于论文阅读:Self-conditioned Image Generation via Generating Representations(RCG)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)