本文主要是介绍简要论文笔记:Conformer: Local Features Coupling Global Representations for Visual Recognition,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者团队:
Zhiliang Peng,Wei Huang,Shanzhi Gu,Lingxi Xie,Yaowei Wang,Jianbin Jiao,Qixiang Ye国科大,华为,鹏城实验室
在下面我们将简要总结一下介绍一下Conformer,有兴趣的读者可以看下原文:论文原文
VIT后很多工作都是想办法把transforemer和convolution结合起来,希望同时享受各自的优点。这篇文章也是如此。
目录
一.论文试图解决什么问题?
二.有没有相关类似的工作?
三.论文的贡献是什么?
四.论文中提到的解决方案是什么?
核心网络结构
一.论文试图解决什么问题?
在Visual Transformer中,虽然级联自注意力模块可以捕获长距离特征依赖关系,但会破坏局部特征细节,虽然已经有工作提出了一个标记化模块或利用CNN特征图作为输入tokens来捕获特征相邻信息。然而不幸的是,关于如何精确的将局部特征和全局表示相互嵌入的问题依然存在。CNN虽然擅长提取局部细节,但是难以捕获全局表示,虽然已经有相关将全局线索引入CNN的工作,但是它们或意味着更低的空间分辨率或意味着将有可能会恶化局部特征细节。
二.有没有相关类似的工作?
有。作者不是第一个考虑将convolution和transformer结合起来的人,之前也有一些工作做的这方面。
ContNet:降参数量的时候可以考虑用这个
T2TViT:多个tokens并成一个token,这是soft spilt,类似conv的想法,存在着重叠部分。
ConTNet:在vit中加入了一个conv embedding,就是先把tokens reshape成图,然后用卷积完成下采样以及相邻token的交互。这样tokens越来越少,embedding越来越多。在多头注意力部分利用层深可分离卷积做Convolutional Projection,取代了线性投影(降计算量,提取局部特征)
DeiT:提出使用蒸馏token将基于CNN的特征转移到visual transformers
DETR:将CNN提取的局部特征提供给transformer encoder-decoder,以串行方式对特征之间的全局关系进行建模。
三.论文的贡献是什么?
1.提出了一种双重网络结构,称为conformer,它最大限度地保留了局部特征和全局表示。
2.提出了特征耦合单元(FCU),以交互方式将卷积局部特征与基于transforemers的全局表示融合。
3.在可比的参数复杂性下,Conformer的性能明显优于CNN和visual transformers。Conformer继承了CNN和visual transformers的结构和泛化优势,展示了成为通用骨干网络的巨大潜力。
四.论文中提到的解决方案是什么?
核心网络结构
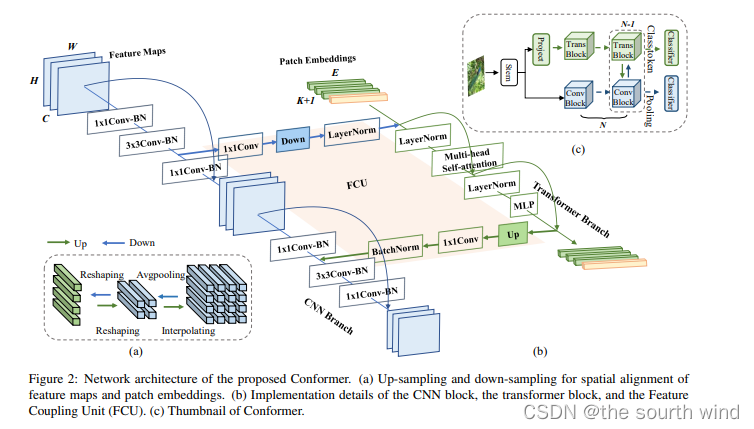
CNN Branch:CNN分支方面采用特征金字塔结构,特征图的分辨率随着网络深度的增加而降低,而通道数增加,作者将分支分为了四个阶段,每个阶段由多个卷积块组成,每个卷积块包含![]() 个bottlenecks。按照ResNet中的定义,bottleneck包含一个1*1下投影卷积、一个3*3空间卷积、一个1*1的上投影卷积,以及bottleneck的输入和输出之间的残差连接。在实验中,
个bottlenecks。按照ResNet中的定义,bottleneck包含一个1*1下投影卷积、一个3*3空间卷积、一个1*1的上投影卷积,以及bottleneck的输入和输出之间的残差连接。在实验中,![]() 在第一个卷积中设置为1,在随后的N-1个卷积块中满足>=2。
在第一个卷积中设置为1,在随后的N-1个卷积块中满足>=2。
visual transformers通过一个步骤将图像patch投影到一个向量中,导致局部细节丢失。而在CNN中,卷积核在重叠的特征图上滑动,这提供了保留精细局部特征的可能性。因此,CNN分支能够为transformer分支连续提供局部特征细节。
Transformer Branch:在VIT之后,这个分支包含N个重复的Transfoerm blocks。如上面的网络结构图所示,每个transformer block由一个多头自注意力模块和一个MLP block(包含一个上投影fc层和一个下投影fc层)组成。LayerNorms应用于自注意力层和MLP block中的每一层和残差连接之前。对于tokenization,作者通过线性投影层将主干模块生成的特征图压缩为没有重叠的14*14 patch embeddings,该线性投影层是一个4*4卷积,步长为4。然后将类token假装成patch embeddings进行分类。考虑到CNN分支(3*3卷积)对局部特征和空间位置信息进行编码,不再需要位置embeddings。这有助于提高下游任务的图像分辨率。
这篇关于简要论文笔记:Conformer: Local Features Coupling Global Representations for Visual Recognition的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







