本文主要是介绍AutoNeRF:Training Implicit Scene Representations with Autonomous Agents,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

论文概述
《AutoNeRF》是由Pierre Marza等人撰写的一篇研究论文,旨在通过自主智能体收集数据来训练隐式场景表示(如神经辐射场,NeRF)。传统的NeRF训练通常需要人为的数据收集,而AutoNeRF则提出了一种使用自主智能体高效探索未知环境,并利用这些经验自动构建隐式地图表示的方法。本文比较了不同的探索策略,包括手工设计的基于前沿的探索、端到端方法以及由高层规划器和低层路径跟随器组成的模块化方法。
这些模型在四种下游任务(经典视点渲染、地图重建、规划和姿态精炼)上的表现进行了评估,结果显示使用自主收集的数据训练NeRF在未见过的环境中仅通过一次探索即可完成建模,并且模块化的探索模型优于其他经典和端到端的基线方法。最后,论文展示了AutoNeRF在重建大规模场景方面的能力,使其成为执行场景特定适应的有用工具。
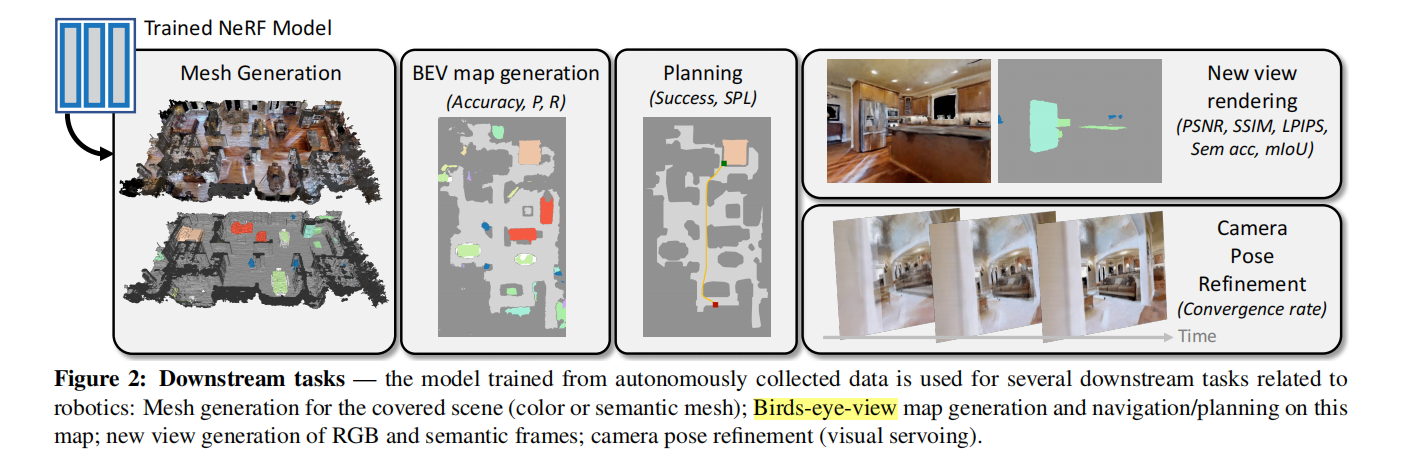
1. 引言
-
背景与动机:
- 随着计算机视觉和机器人技术的发展,隐式场景表示(如神经辐射场,NeRF)在生成新视角图像方面表现卓越。然而,训练这些模型需要大量的精心收集的数据。
- 本文提出的AutoNeRF方法,通过自主智能体高效探索未知环境,自主收集数据,训练高质量的隐式场景表示模型。
-
研究目标:
- 开发一种能自主收集数据的智能体,使其在探索未知环境时,能够自动构建NeRF模型。
- 评估这些模型在不同下游任务(如视角渲染、地图重建、规划和姿态精炼)中的表现。
2. 相关工作
-
神经场景表示:
- NeRF通过神经网络表示3D场景的结构,使用差分体积渲染损失从2D图像监督中重建3D场景。
- 隐式表示技术在新视角合成、实时SLAM和语义增强方面表现出色。
-
机器人领域的应用:
- 现有的隐式表示技术主要集中在离线场景的训练和推理,而在机器人领域的在线应用还需进一步探索。
-
主动学习和自主场景探索:
- 传统方法大多依赖于静态数据集上的帧选择,本文提出的方法在大规模动态室内场景中进行主动探索,提升数据收集效率。
3. 方法
整体框架
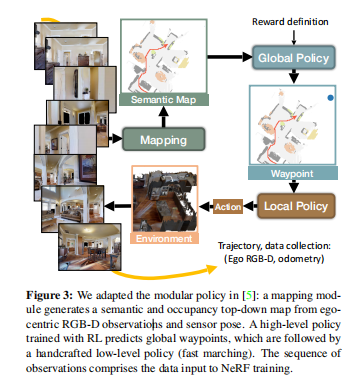
图3:模块化探索策略
图3展示了AutoNeRF中使用的模块化探索策略框架。该框架主要由三个部分组成:全局策略、局部策略和NeRF训练过程。以下是对每个组成部分的详细描述。
1. 全局策略
全局策略负责探索过程中的高级决策,预测智能体应该导航到的中间航点。全局策略的输入是一组语义地图,包括占据信息、已探索区域和语义分割信息。该策略通过卷积神经网络实现,并使用强化学习技术,特别是近端策略优化(PPO)进行训练。
- 输入:堆叠的语义地图(占据、探索、语义)。
- 输出:中间航点。
- 训练:强化学习(PPO)。
2. 局部策略
局部策略负责向全局策略提供的航点导航。它通过采取离散动作使智能体朝着航点移动(在本例中为25步)。这些动作包括向前移动和向左或向右转向。局部策略使用快速行进法(Fast Marching Method),一种经典的路径规划算法,高效地导航到目标航点。
- 输入:中间航点。
- 输出:离散导航动作(前进、左转、右转)。
- 算法:快速行进法。
3. NeRF训练
当智能体通过探索收集到数据后,使用这些数据训练NeRF模型。收集的数据包括图像及其相应的相机位姿。NeRF模型训练旨在预测3D空间中任何点的颜色、密度和语义类别。训练过程包括沿着从相机发出的射线采样点,并优化预测输出使其与真实图像匹配,使用体积渲染技术进行优化。
- 输入:探索过程中收集的图像和相机位姿。
- 输出:3D场景表示(密度、颜色、语义)。
- 训练:体积渲染优化。
其他组成部分
- 奖励函数:使用不同的奖励函数来训练全局策略,关注诸如已探索区域覆盖或障碍物重要性等方面。
- 评估:训练好的NeRF模型在几个下游任务上进行评估,包括新视角渲染、地图重建、规划和姿态精炼。
总结
图3概括了AutoNeRF框架的整体架构和流程。它展示了探索策略(全局和局部)如何协同工作进行导航和数据收集,以及如何利用这些数据训练NeRF模型进行3D场景重建。这种模块化的方法确保了高效的探索和高质量的3D建模,实现了通过自主收集的数据进行隐式场景表示的构建。
-
3.1 任务描述:
- 智能体在未知场景中初始化,通过执行离散动作收集观测数据,这些数据用于训练NeRF模型。
- 训练过程包括从智能体的视角收集图像和深度信息,并通过这些信息优化NeRF模型的参数。
-
3.2 探索策略训练:
- 使用模块化探索策略,主要由全局策略负责探索方向的决策。
- 奖励信号包括覆盖面积、障碍物覆盖、语义对象覆盖和视点覆盖等。
-
3.3 具体实现:
- 模块化探索策略由高层规划器(负责整体探索策略)和低层路径跟随器(负责具体行动)组成。
- 高层规划器使用强化学习训练,目标是最大化覆盖新区域的奖励信号。
- 低层路径跟随器通过快速行进方法导航,确保智能体能高效到达目标位置。
4. 实验
-
实验设置:
- 在不同测试场景中使用训练好的探索策略收集数据,并训练NeRF模型。
- 评估这些模型在下游任务(如视角渲染、地图重建、规划和姿态精炼)中的表现。
-
结果分析:
- 实验结果表明,AutoNeRF能够在仅一次探索中有效收集数据并训练NeRF模型。
- 模块化探索策略在多项任务上表现优越,证明其在未知环境中自主探索和数据收集的有效性。




5. 结论
-
总结:
- AutoNeRF展示了自主智能体在探索未知环境中的高效数据收集能力,能够利用这些数据训练高质量的隐式场景表示模型。
- 这种方法在多种下游任务中表现出色,为机器人领域的场景特定适应提供了有力工具。
-
未来工作:
- 进一步优化探索策略,提高智能体在复杂环境中的适应性。
- 探索更多的下游任务应用,验证AutoNeRF在不同场景中的泛化能力。
论文细节补充
-
训练数据集:
- 论文中使用了多种室内环境数据集进行训练和测试,以验证方法的有效性。
- 包括模拟的房间布局和真实世界的室内场景。
-
技术细节:
- NeRF模型的训练过程涉及优化损失函数,使得预测的颜色和密度与观测数据一致。
- 强化学习策略的训练过程涉及多个探索步骤和奖励信号的设计,以引导智能体高效探索新区域。
-
评估方法:
- 通过比较不同探索策略的覆盖面积和重建质量,评估智能体的探索效率。
- 使用标准的视角渲染、地图重建、规划和姿态精炼任务,验证模型在下游任务中的性能。
这篇关于AutoNeRF:Training Implicit Scene Representations with Autonomous Agents的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




![[论文解读]Genre Separation Network with Adversarial Training for Cross-genre Relation Extraction](https://i-blog.csdnimg.cn/blog_migrate/a81ef8f36f1400d5367d93036bc14ef7.png)


