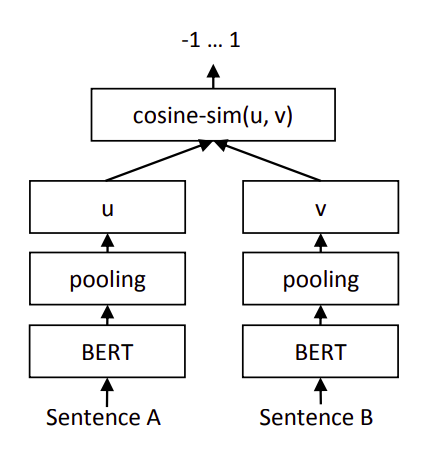
本文主要是介绍BERT-Bidirectional Encoder Representations from Transformers,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
BERT, or Bidirectional Encoder Representations from Transformers
BERT是google最新提出的NLP预训练方法,在大型文本语料库(如维基百科)上训练通用的“语言理解”模型,然后将该模型用于我们关心的下游NLP任务(如分类、阅读理解)。 BERT优于以前的方法,因为它是用于预训练NLP的第一个**无监督,深度双向**系统。
简单的说就是吊打以前的模型,例如 Semi-supervised Sequence Learning,Generative Pre-Training,ELMo, ULMFit,在多个语言任务上(SQuAD, MultiNLI, and MRPC)基于BERT的模型都取得了state of the art的效果。
BERT 的核心过程:
-
从句子中随机选取15%去除,作为模型预测目标,例如:
Input: the man went to the [MASK1] . he bought a [MASK2] of milk. Labels: [MASK1] = store; [MASK2] = gallon -
为了学习句子之间的关系。会从数据集抽取两个句子,其中第二句是第一句的下一句的概率是 50%,
Sentence A: the man went to the store . Sentence B: he bought a gallon of milk . Label: IsNextSentenceSentence A: the man went to the store . Sentence B: penguins are flightless . Label: NotNextSentence -
最后再将经过处理的句子传入大型 Transformer 模型,并通过两个损失函数同时学习上面两个目标就能完成训练。
主要在于Transformer模型。后续需要再分析其模型机构以及设计思想。
预训练模型
BERT-Base, Uncased:
12-layer, 768-hidden, 12-heads, 110M parametersBERT-Large, Uncased:
24-layer, 1024-hidden, 16-heads, 340M parametersBERT-Base, Cased:
12-layer, 768-hidden, 12-heads , 110M parametersBERT-Large, Cased: 24-layer, 1024-hidden, 16-heads, 340M parameters
(Not available yet. Needs to be re-generated).BERT-Base, Multilingual:
102 languages, 12-layer, 768-hidden, 12-heads, 110M parametersBERT-Base, Chinese:
Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M
parameters
其中包含:
- A TensorFlow checkpoint (
bert_model.ckpt) containing the pre-trained
weights (which is actually 3 files). - A vocab file (
vocab.txt) to map WordPiece to word id. - A config file (
bert_config.json) which specifies the hyperparameters of
the model.
其他语言见: Multilingual README。开放了中文数据集。
- BERT-Base, Multilingual: 102 languages, 12-layer, 768-hidden, 12-heads, 110M parameters
- BERT-Base, Chinese: Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M
parameters
(算力紧张情况下单独训练了一版中文,中文影响力可见一斑,我辈仍需努力啊)
更多细节见: https://github.com/google-research/bert
Reference
- GitHub(TensorFlow): https://github.com/google-research/bert
- PyTorch version of BERT :https://github.com/huggingface/pytorch-pretrained-BERT
- BERT-Base, Chinese: https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
- 论文: https://arxiv.org/abs/1810.04805.
这篇关于BERT-Bidirectional Encoder Representations from Transformers的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)