本文主要是介绍CVPR 2020 ActBERT: Learning Global-Local Video-Text Representations,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
动机
- 目前已有许多视频和语言任务来评估模型在视频-文本联合表征学习中的能力,视频数据是学习跨模态表征的自然来源。文本描述由现成的自动语音识别(ASR)模型自动生成。这对于模型在实际应用程序中的部署更具有可缩放性和通用性。在本文中,作者致力于以一种自监督的方式学习联合视频-文本表示。
- 尽管监督学习在各种计算机视觉任务中取得了成功,但近年来,基于无标记数据的自监督表征学习引起了越来越多的关注。在自监督学习中,一个模型首先在一个代理损失的大量未标记数据上进行预训练。微调过程进一步帮助预训练好的模型在下游任务中得以应用。近年来,文本的自监督表示学习取得了迅速的进展,其中BERT模型可明显地推广到许多自然语言任务中,如问答。
- 激励于BERT在自监督训练方面的成功,作者的目标是学习一个相似的视频-文本联合建模的模型。
- 为了将BERT推广到视频和语言任务(跨模态数据的建模),Sun等人通过聚类将视觉特征离散化为视觉单词。这些视觉token可以直接传递给原始的BERT模型。然而,聚类过程中可能会丢失详细的局部信息,如交互目标、人的动作等。它阻止了模型发现视频和文本之间的细粒度关系。另外,同步的视频-音频信号利用了低层次音频信号,只考虑了视频数据的同步性质。在本工作中,作者重点研究视频-文本联合表征学习。作者的ActBERT充分利用了多源信息,在许多下游视频-文本任务中取得了令人瞩目的性能。
- 从教学视频中学习具有挑战性,因为它在各种任务中的数据复杂性。这些视频收集自许多领域,如烹饪,体育,园艺。许多作品也将教学视频生成的transcriptions视为监督的一个来源。然而,作者在一个统一的框架中使用ActBERT显式地建模人类动作、局部区域。作者改进了Howto100m,在视频和视频描述之间建立了更具体的关系模型。作者定量地证明了ActBERT更适合于无监督的视频-文本建模。
方法
简介
激励于BERT在自监督训练方面的成功,作者的目标是学习一个相似的视频和文本联合建模的模型。作者基于解说的教学视频,利用视频-文本关系,其中对齐的文本是通过现成的自动语音识别(ASR)模型检测出来的。这些教学视频是视频-文本关系研究的自然来源。首先,它们可以在YouTube和其他平台上大量地获得和免费访问。其次,视觉帧与教学解说对齐。文本解说不仅明确地涵盖了场景中的目标,而且识别了视频剪辑中的突出动作。
为了将BERT推广到视频和语言任务,作者提出ActBERT从成对的视频序列和文本描述中学习一种联合的视频-文本表示,该表示揭示了全局和局部的视觉线索。全局和局部视觉信号都与语义流彼此相互作用。ActBERT利用深刻的上下文信息和细粒度关系进行视频-文本联合建模。
首先,ActBERT在一个联合框架中结合了全局动作、局部-区域目标和文本描述。“cut”、“rotate”、“slice”等动作对于各种视频相关的下游任务是必不可少的。对人的动作的识别可以体现模型对动作的理解能力和对复杂的人的意图的推理能力。在模型预训练过程中,显式地模拟人的动作是有益的。长期动作序列还提供了关于一个教学任务的时间依赖性。虽然动作线索很重要,但在以前的自监督的视频文本训练中,它们很大程度上被忽略了,在这些训练中,动作与目标是做相同处理的。为了对人类动作进行建模,作者首先从文本描述中提取动词,并从原始数据集中构造一个动作分类数据集。然后,训练一个3D卷积网络来预测动作标签。将优化后的网络特征作为动作嵌入。通过这种方式,表示剪辑级操作,并插入相应的操作标签。除了全局动作信息之外,作者还结合了局部-区域信息来提供细粒度的视觉提示。目标区域提供了关于整个场景的详细的视觉线索,包括目标的区域特征、目标的位置等。语言模型可以从区域信息中受益,以更好地实现语言和视觉的对齐。
其次,作者引入了一个TNT(TaNgled Transformer block)来编码来自三个来源的特征,即全局输入、局部-区域目标和语言tokens。以前的研究在设计新的Transformer层时考虑了两种模式,即来自图像和自然语言的细粒度目标信息。Lu等人引入了一个co-attention的Transformer层,其中一个模态的键-值对被传递到另一个模态的attention块以充当新的键-值对。然而,在作者的场景中,有三个输入源。两个来源,即局部区域特征和语言文本,提供了在剪辑中发生事件的详细的描述。另一个全局动作特征提供了时间序列中的人类意图,并为上下文推断提供了直接的线索。作者设计了一种新的TaNgled Transformer块,用于从三个源进行跨模态特征学习。为了增强两个视觉线索和语言特征之间的相互作用,作者使用一个不相关的Transformer块来编码每个模态。相互的跨模态交流在后来通过两个额外的多头attention块来增强。动作特征催化了相互间的交互作用。在动作特征的指导下,作者将视觉信息注入到语言Transformer中,并将语言信息整合到视觉Transformer中。TaNgled Transformer动态地选择其上下文的明智线索,以促进目标预测。
此外,作者设计了四个替代任务来训练ActBERT,即基于全局和局部视觉线索的masked语言建模、masked动作分类、masked目标分类和跨模态匹配。经过预训练的ActBERT被转移到五个与视频相关的下游任务,即视频captioning、动作分割、文本-视频分段检索、动作步骤定位和视频问答。作者定量地表明ActBERT以明显的优势实现了最先进的性能。
架构
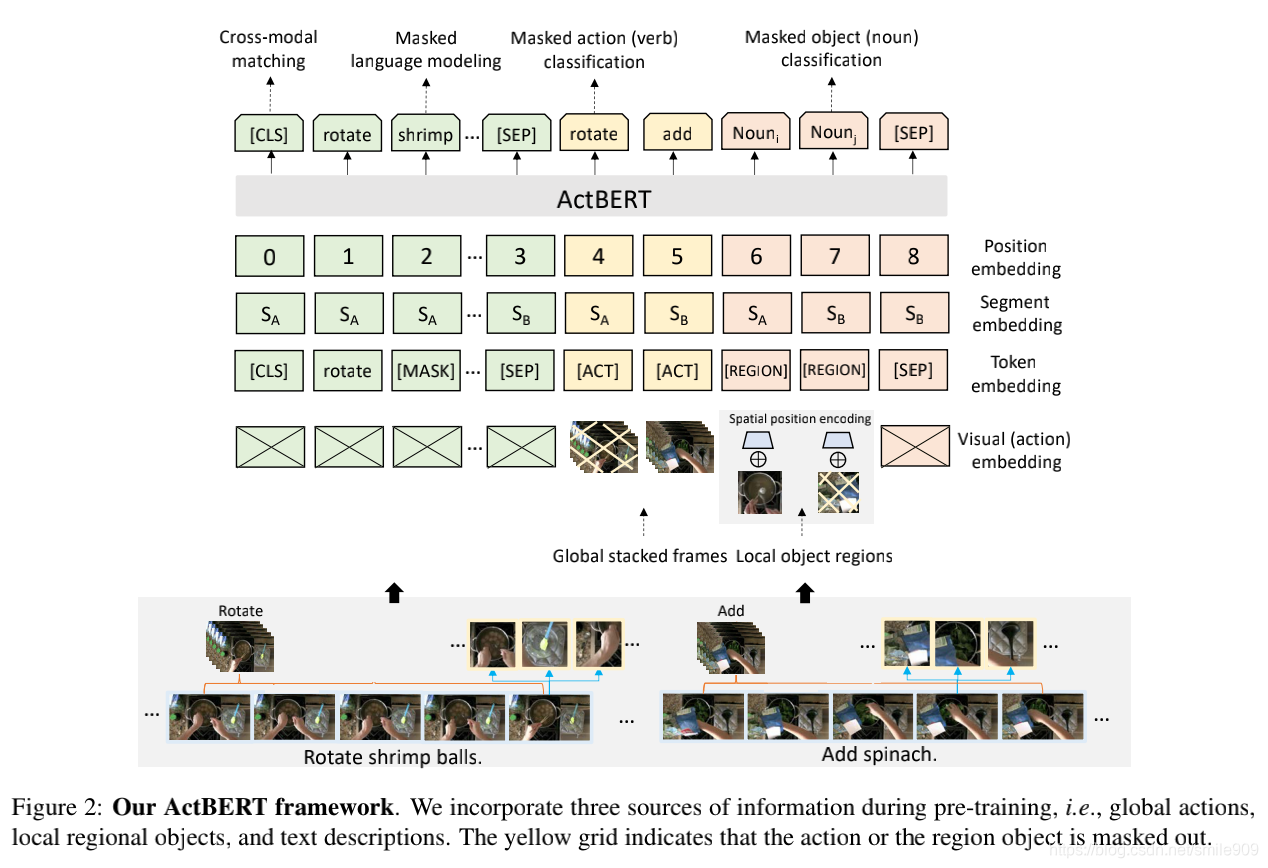
在ActBERT架构中,作者在预训练过程中结合了三个信息源,即全局动作、局部区域目标和文本描述。
BERT
作者首先说明原始的BERT模型。BERT以无监督的方式在大型语料库上预训练了一个语言模型。预训练好的模型是灵活的,并且有利于各种下游任务
这篇关于CVPR 2020 ActBERT: Learning Global-Local Video-Text Representations的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






