actbert专题
CVPR 2020 ActBERT: Learning Global-Local Video-Text Representations
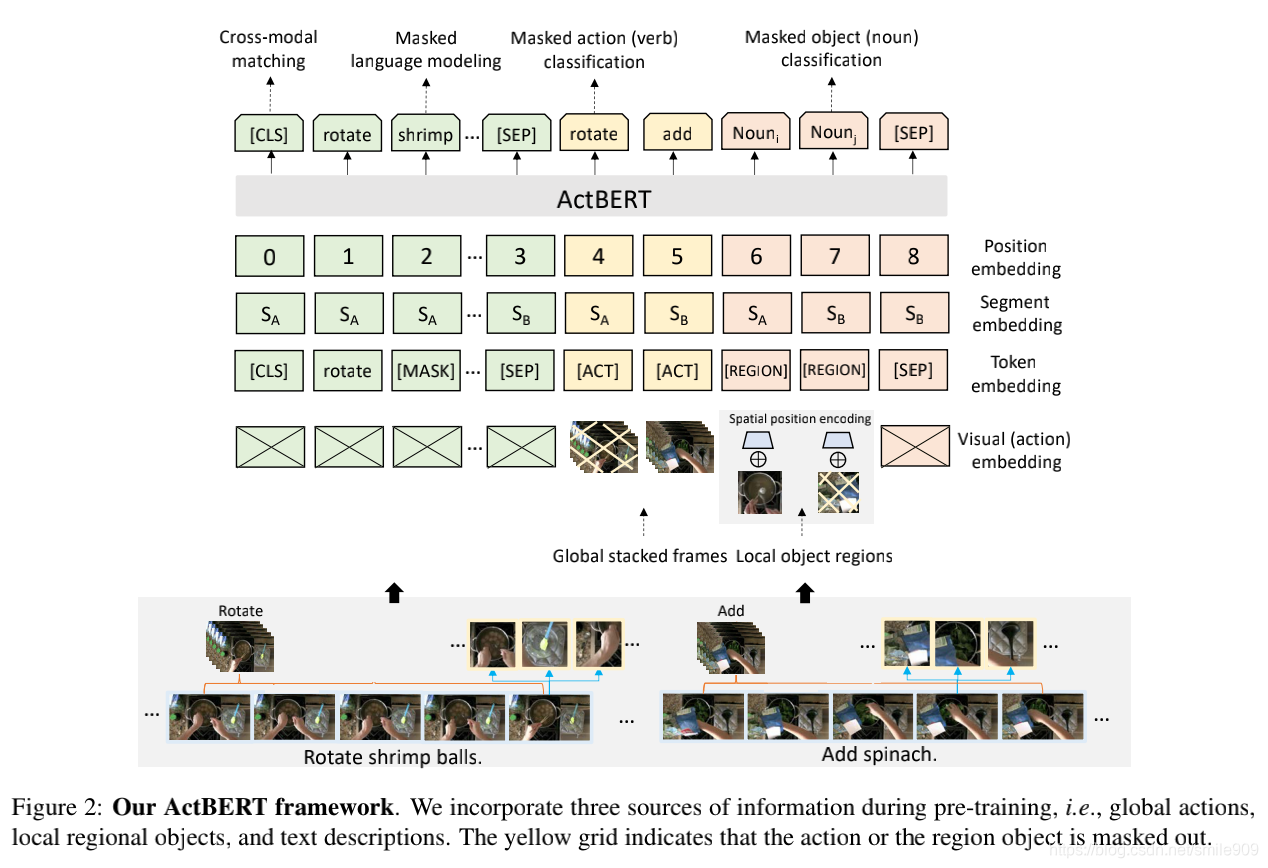
动机 目前已有许多视频和语言任务来评估模型在视频-文本联合表征学习中的能力,视频数据是学习跨模态表征的自然来源。文本描述由现成的自动语音识别(ASR)模型自动生成。这对于模型在实际应用程序中的部署更具有可缩放性和通用性。在本文中,作者致力于以一种自监督的方式学习联合视频-文本表示。尽管监督学习在各种计算机视觉任务中取得了成功,但近年来,基于无标记数据的自监督表征学习引起了越来越多的关注。在自监督
CVPR 2020 ActBERT: Learning Global-Local Video-Text Representations
动机 目前已有许多视频和语言任务来评估模型在视频-文本联合表征学习中的能力,视频数据是学习跨模态表征的自然来源。文本描述由现成的自动语音识别(ASR)模型自动生成。这对于模型在实际应用程序中的部署更具有可缩放性和通用性。在本文中,作者致力于以一种自监督的方式学习联合视频-文本表示。尽管监督学习在各种计算机视觉任务中取得了成功,但近年来,基于无标记数据的自监督表征学习引起了越来越多的关注。在自监督